
Bring this project to life
Introduction
YOLO-World a SOTA model joins the YOLO series, now whats new if we ask! This new model can perform object detection on (allegedly) any object without the need to train the model. Now that's something new and incredible!
With Paperspace get access to the powerful GPUs, we get a decent FPS when working with real-time object detection. GPUs, such as NVIDIA with CUDA, work with optimized libraries and frameworks specifically designed for deep learning tasks. These libraries leverage the parallel architecture of GPUs and offer efficient implementations of common deep learning operations, further enhancing performance.
In applications where real-time object detection is required, such as autonomous vehicles or surveillance systems, GPUs are essential. Their parallel processing capabilities enable fast inference speeds, allowing the model to process and analyze video streams in real-time.
In this article, let's dig into YOLO-World, a groundbreaking zero-shot object detector that boasts a remarkable 20-fold speed enhancement compared to its predecessors. We'll explore its architecture, dissect the primary factors contributing to its exceptional speed, and most importantly, we will go through the process of running the model on Paperspace Platform to analyze both images and videos.
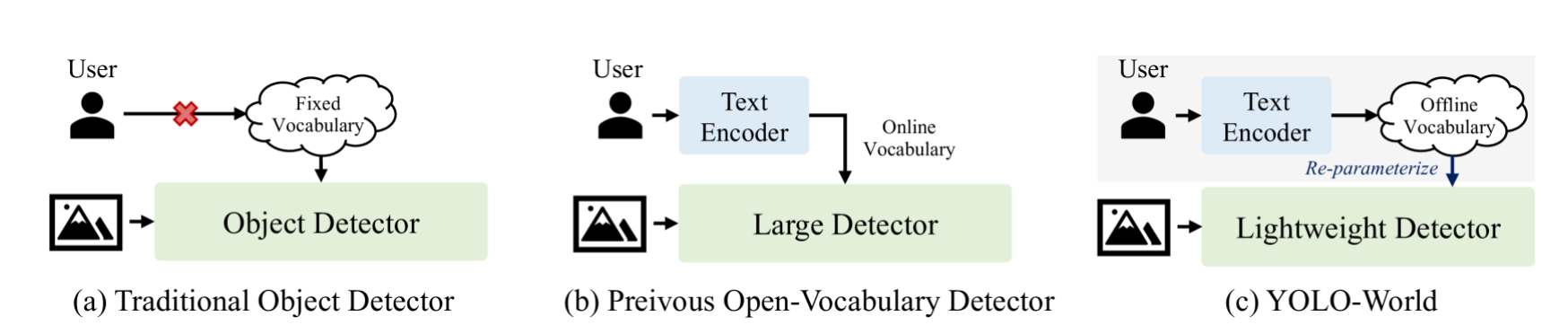
What's new in YOLO-World
If we talk about traditional object detection models like Faster R-CNN, Single Shot Detectors (SSD), or YOLO for that matter, these models are confined to detecting objects within the predefined categories (such as the 80 categories in the COCO dataset). This is a facet of all supervised learning models. Recently, researchers have turned their attention towards developing open-vocabulary models. These models aim to address the need for detecting new objects without the necessity of creating new datasets, a process which is both time-consuming and costly.
The YOLO-World Model presents a cutting-edge, real-time method built upon Ultralytics YOLOv8, revolutionizing Open-Vocabulary Detection tasks. This advancement allows for the identification of various objects in images using descriptive texts. With reduced computational requirements yet maintaining top-tier performance, YOLO-World proves to be adaptable across a wide array of vision-based applications.
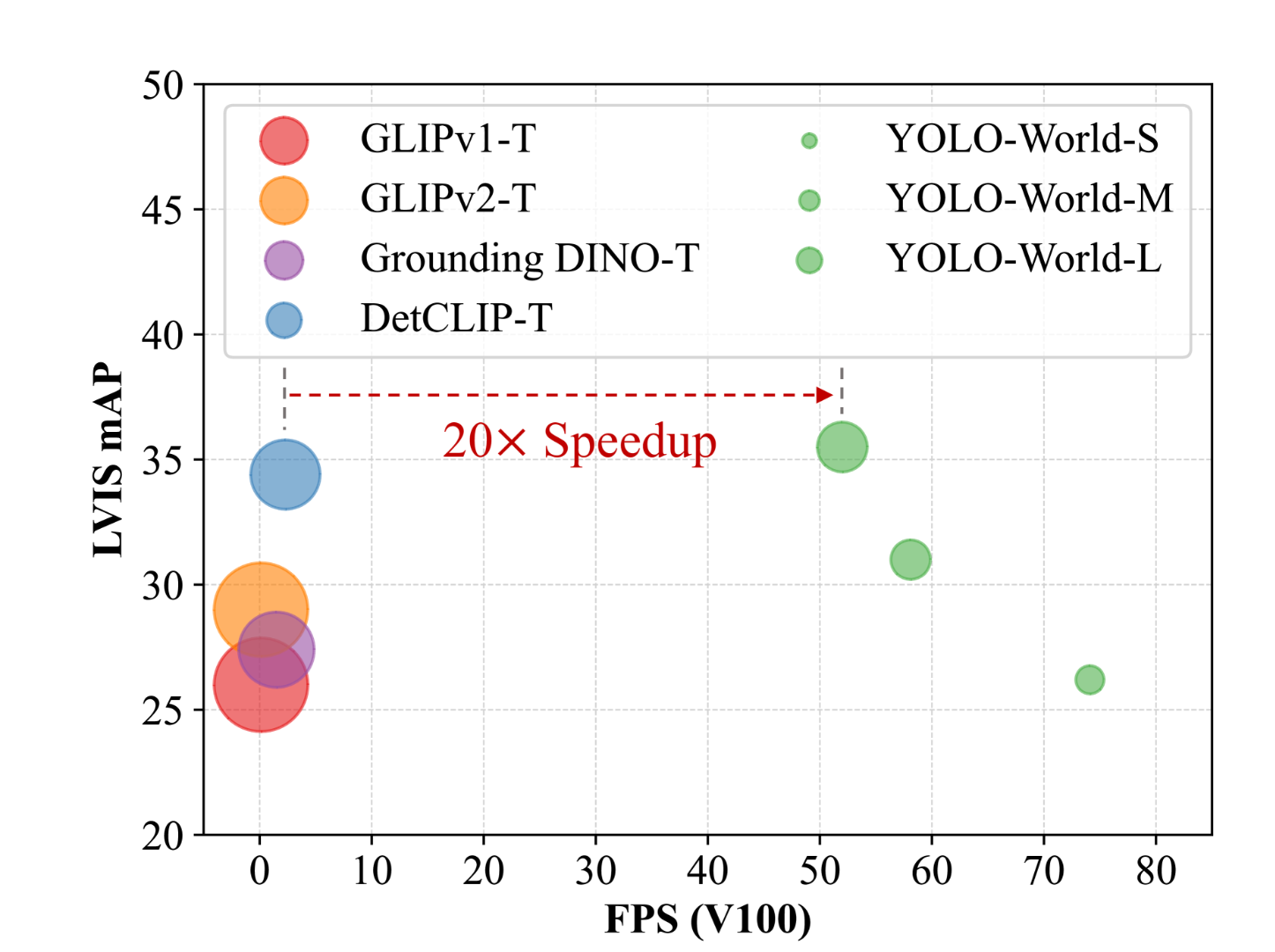
If you are interested in other models in YOLO series, we encourage our readers to checkout our blogs in YOLO and object detection.
Model Architecture
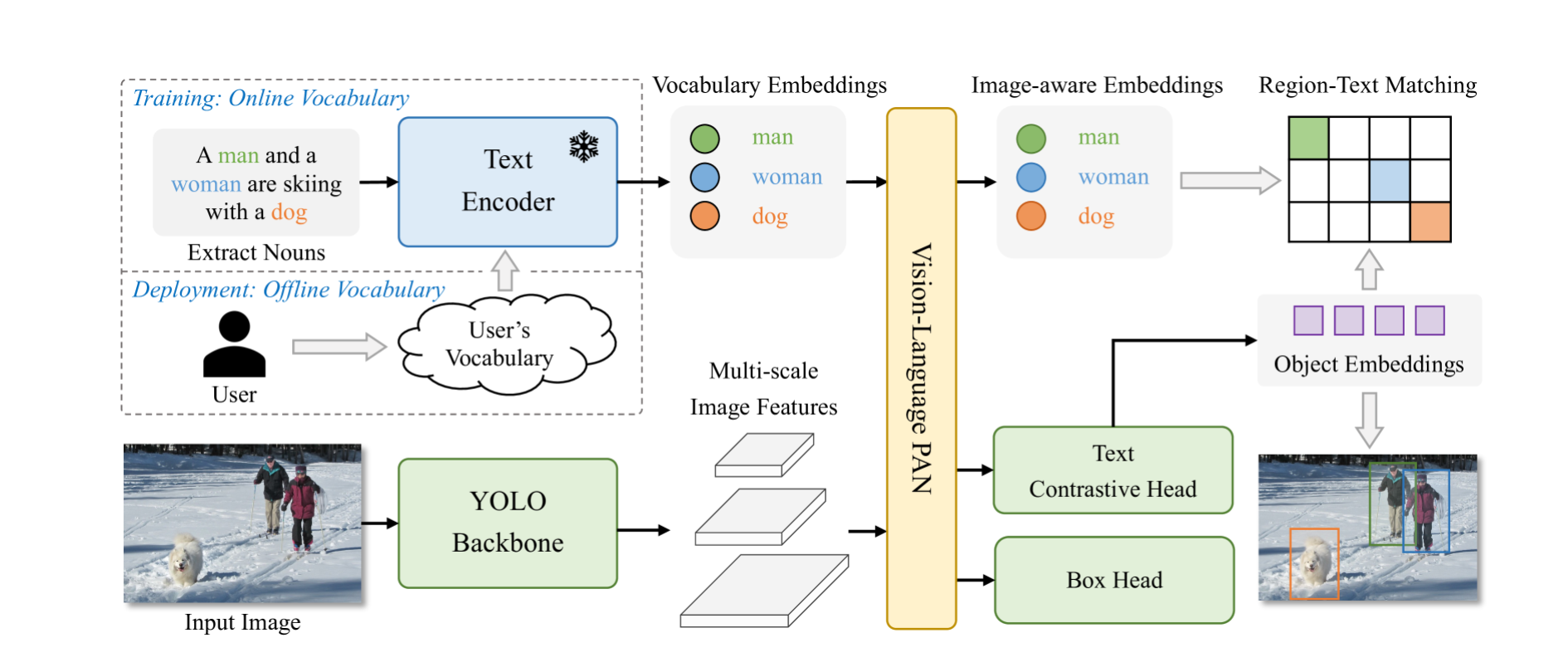
The architecture of the YOLO-World consists of a YOLO detector, a Text Encoder, and a Re-parameterizable Vision-Language Path Aggregation Network (RepVL-PAN).
YOLO-World primarily builds upon YOLOv8, which includes a Darknet backbone serving as the image encoder, a path aggregation network (PAN) for generating multi-scale feature pyramids, and a head for both bounding box regression and object embeddings.
The detector captures multi-scale features from the input image, a text encoder to convert the text into embeddings, utilizes a network for multi-level fusion of image features and text embeddings, and incorporates a custom network for the same purpose.
Using a lighter and faster CNN network as its backbone is one of the reasons for YOLO-World's speed. The second one is prompt-then-detect paradigm. Instead of encoding your prompt each time you run inference, YOLO-World uses Clip to convert the text into embeddings. Those embeddings are then cached and reused, bypassing the need for real-time text encoding.
YOLO-World achieves its speed through two main strategies. Firstly, it adopts a lighter and faster CNN network as its backbone. Secondly, it employs a "prompt-then-detect" paradigm. Unlike traditional methods that encode text prompts each time during inference, YOLO-World utilizes Clip to convert text into embeddings. These embeddings are cached and reused, eliminating the need for real-time text encoding, thereby enhancing speed and efficiency.
Now let us jump to the coding part and check out the model using the Paperspace Platform. The link to the notebook is provided with this article, we highly recommend to check out the notebook and try the model. Click the link and you should be redirected to the Paperspace Platform.
Code Demo
Bring this project to life
Let us start by checking the running GPU
!nvidia-smi
Now that we have the confirmed output that CUDA session has GPU support, it's time to install the necessary libraries.
!pip install -U ultralyticsOnce the requirement is satisfied, move to the next step of importing the libraries
import ultralytics
ultralytics.__version__Output-
'8.1.28'
from ultralytics import YOLOWorld
# Initialize a YOLO-World model
model = YOLOWorld('yolov8s-world.pt') # or select yolov8m/l-world.pt for different sizes
# Execute inference with the YOLOv8s-world model on the specified image
results = model.predict('dog.png',save=True)
# Show results
results[0].show()
Now, if we want the model to predict certain objects in the image without training we can do that by simply passing the argument on "model.set_classes()" function.
Let us use the same image and try to predict the backpack, a truck and a car which is in the background.
# Define custom classes
model.set_classes(["backpack", "car","dog","person","truck"])
# Execute prediction for specified categories on an image
results = model.predict('/notebooks/data/dog.jpg', save=True)
# Show results
results[0].show()
Next, let us try to experiment with another image and here we will predict only a pair of shoes.
# Define custom classes
model.set_classes(["shoes"])
# Execute prediction for specified categories on an image
results = model.predict('/notebooks/data/Two-dogs-on-a-walk.jpg', save=True)
# Show results
results[0].show()
Object Detection using a video
Let us now try out the 'yolov8s-world.pt' model to detect objects in a video. We will execute the following code to carry out the object detection using a saved video.
!yolo detect predict model=yolov8s-world.pt source="/content/pexels-anthony-shkraba-8064146 (1440p).mp4"This code block will generate a "runs" folder in your current directory. Within this folder, you'll find the video saved in the "predict" subfolder, which itself resides within the "detect" folder.
Available Models
Please find the table below which has a details of the models which are available and the tasks they support.
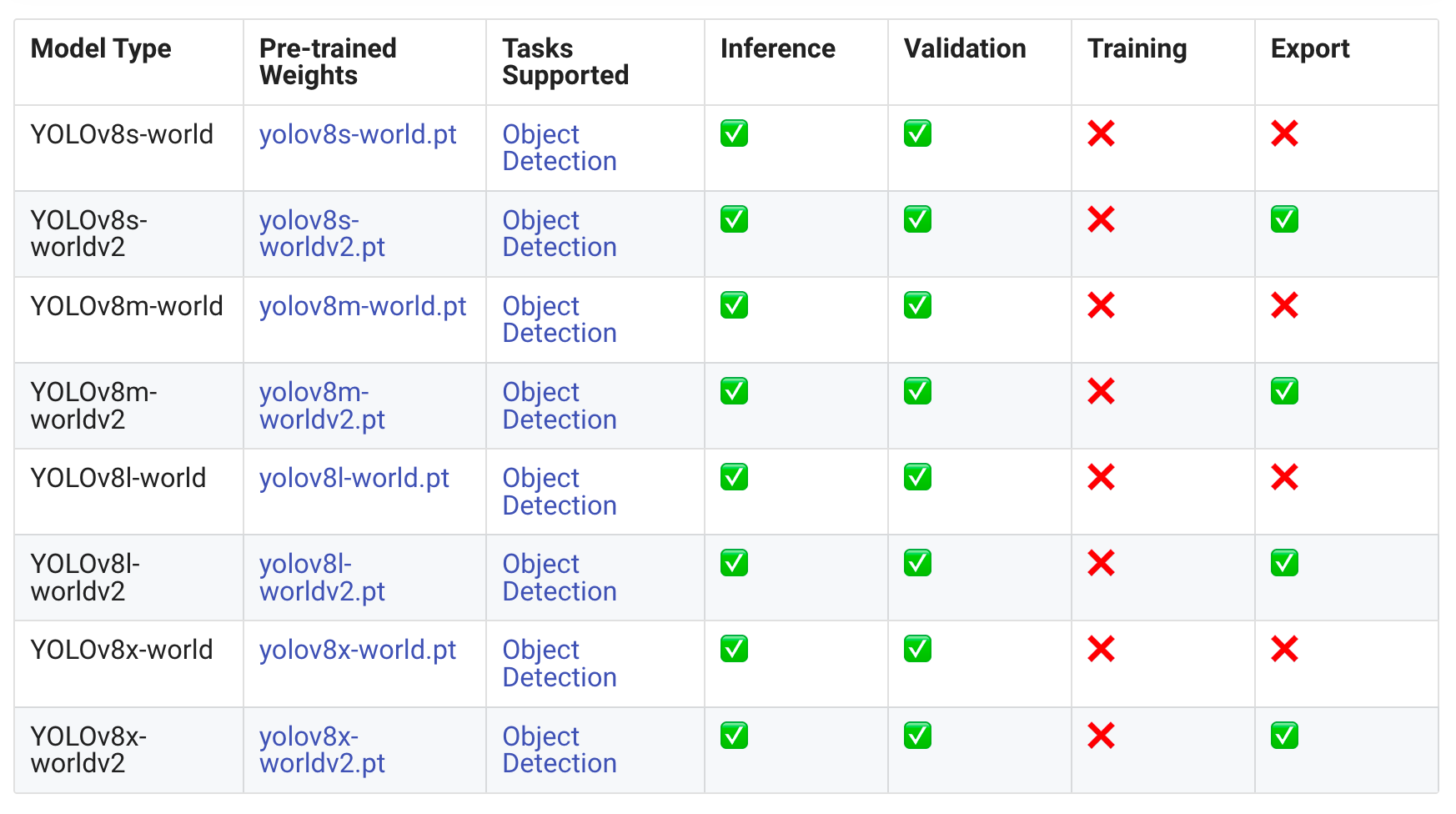
Ultralytics offers a Python API and CLI commands designed for user-friendly development, simplifying the development process.
Detection Capabilitites with Defined Categories
We tried the model's detection capabilities with our defined categories. Here are few images that we tried YOLOV8m. Please feel free to try other models from YOLO-World.


Conclusion
In this article we introduce YOLO-World, an advanced real-time detector aiming to enhance efficiency and open-vocabulary capability in practical settings. This approach is a novel addition to the traditional YOLO architectures to support open-vocabulary pre-training and detection, utilizing RepVL-PAN to integrate vision and language information effectively. Our experiments with different images demonstrates YOLO-World's superior speed and performance, showcasing the benefits of vision-language pre-training on compact models. We envision YOLO-World as a new benchmark for real-world open-vocabulary detection tasks.










