Bring this project to life
These past few months have seen an explosion of AI research that has been long awaited. The advent of Generative Pretrained Transformer (GPT) models almost exactly 5 years prior to the publication of this article was arguably the first stone on which the path was laid. From there, development of nearly human speech generation was only a matter of time. With the proliferation of OpenAI's ChatGPT and GPT4, along with major competitors like Bard and open-source (sort of) alternatives like LLaMa, into the public sector this past half year, now more than ever is the time for everyone to familiarize themselves with these impressive new technologies.
In this article, we want to make navigating this increasibly complex environment simpler - whether you have been working in AI for decades or if you are just starting out. To begin, we will start by discussing the GPT architecture at a glance, and succinctly explain why this architecture has become the default architecture for any NLP/NLU task. Next, we will walk through many of the major terms flying around with regards to LLMs, such as LoRA Fine-Tuning methods, Reinforcement Learning from Human Feedback (RHLF), and quantization methods for faster, lower cost fine-tuning such as QLoRA. We will wrap up this section with brief overviews for what we have concluded are the best available NLP models for us to make use of on our own projects, including Alpaca, LLaVa, MPT-7B, and Guanaco.
We will conclude the article with a tech demo on Paperspace showing how to run any HuggingFace space in a Gradient Notebook, with an example worked completely through on the Guanaco Playground TGI.
The GPT Architecture
The GPT model us a type of LLM that was first introduced with "Improving Language Understanding by Generative Pre-Training" by Rashford et al. in 2018. These researchers fom OpenAI, a name now synonymous with cutting edge deep learning, sought to create a model that takes in natural language prompts as inputs and predicts the best possible response, given the model's understanding of the language. The way GPT models achieve this is, rather than generating an entire text sequence at once, to instead treat each word, called "token", as the guiding input for generating the following token. This allows for a sequential generation of a text sentence with a localized context that prevents the sentences from straying too far from the desired input.
Furthermore, the self attention mechanism built into the transformer enables the model to attend to different parts of this input sequence when generating the response, so it can focus individual attention to the predicted most important parts of the sentence. "Self- attention works by computing a set of attention weights for each input token. The weights then show the relevance of each token compared to other tokens. The transformer then uses the attention weights to assign more importance to the most significant parts of the input, and assigns less importance to the less relevant parts." (source)
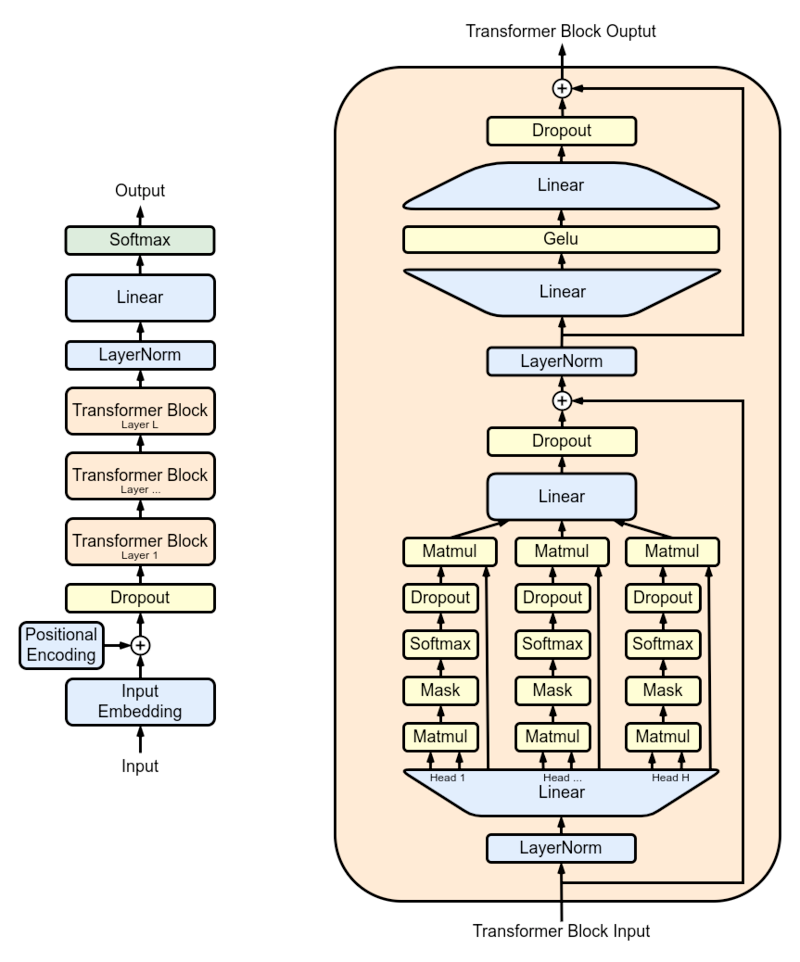
To go into a bit more detail about a generic GPT loop, a token is passed through the architecture as input. along with a positional encoding representing its placement in a sentence. It then passes through a dropout layer, and then through N transformer block layers (shown on the right). A Transformer block consists of layers of Self Attention, Normalization, and feed-forward networks (i.e., MLP or Dense)). These together work to determine the most probable new token output.
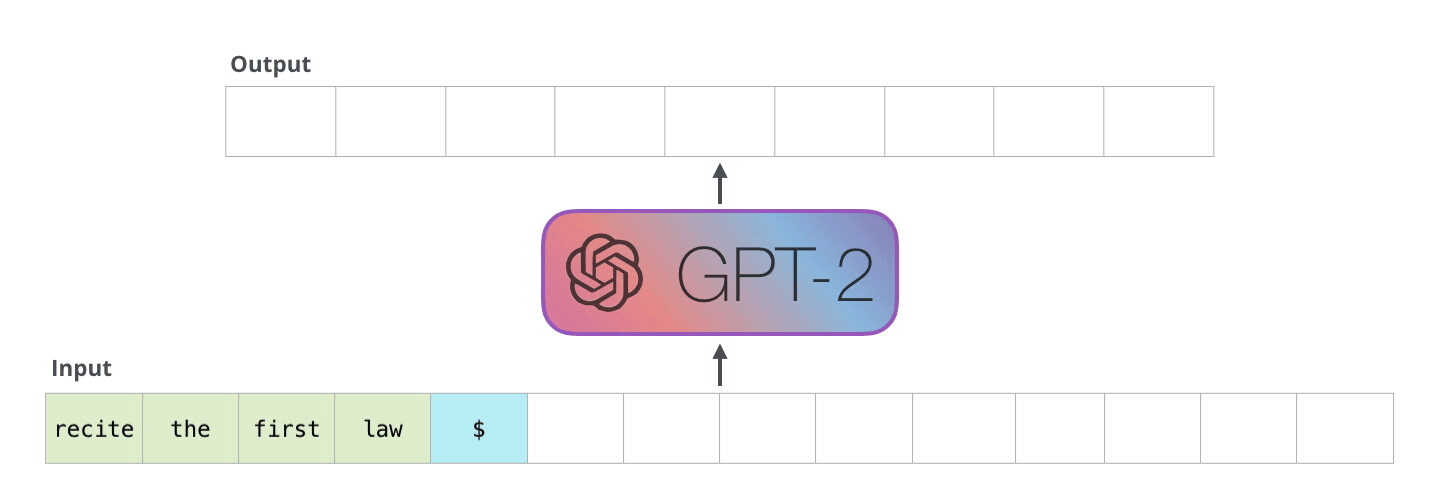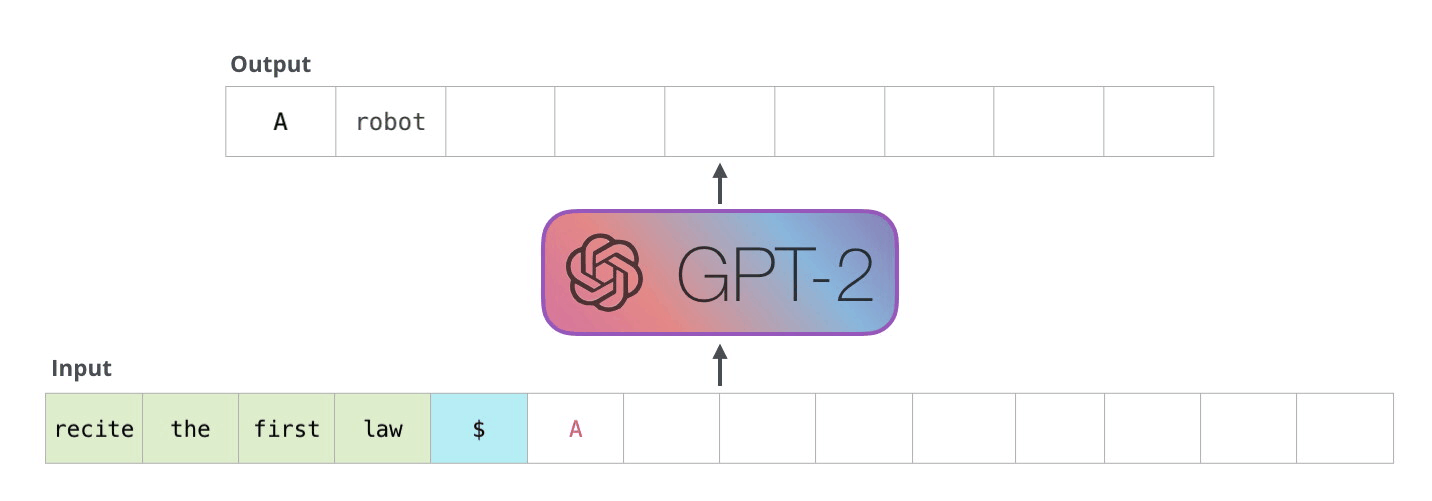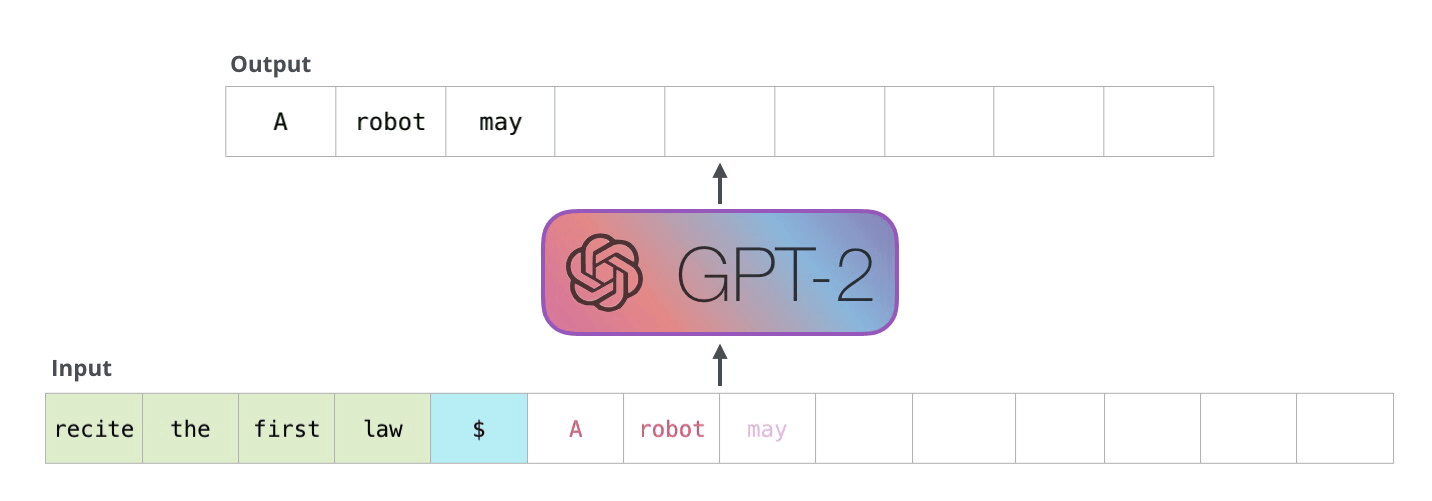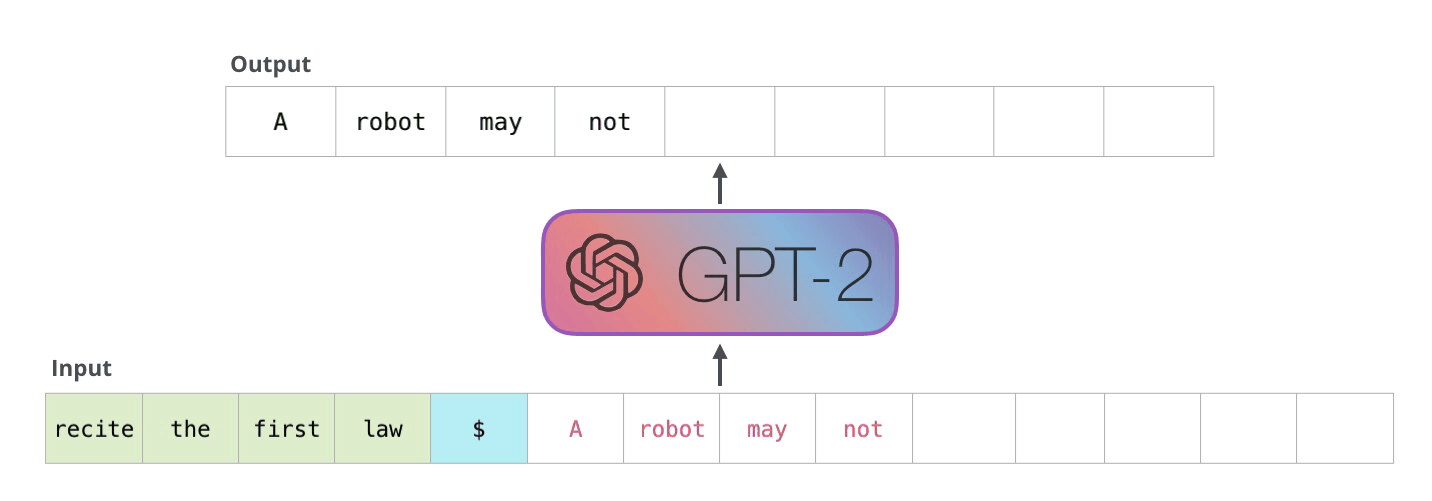
This process is then looped until the GPT model predicts the most likely new token to be an end of sentence token. This can be extended further to generate full paragraphs, and going further than a single sentence is especially common in the newer versions of the GPT models. When trained on sufficient data, this capability for long, context driven generations makes the GPT models unparalleled for text synthesis tasks.
Terms to know for Modern LLMs
This section covers fine-tuning methods for LLMs we believe are worth knowing.
LoRA
The first technique we will discuss is Low Rank Adaptation (LoRA). Low-Rank Adaptation (LoRA) of Large Language Models is a nifty method for training/fine-tuning LLMs that significantly reduces the RAM requirements to do so. To achieve this, LoRA merges the existing model weights with pairs of rank-decomposition weight matrices. These new weights are then the exclusive training targets while the remaining weights remain frozen.
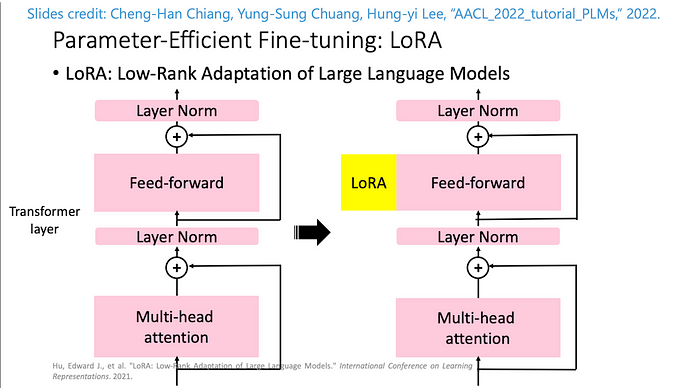
Because the update matrices represent significantly less parameters than the original weights, this allows for a significant reduction of cost to train without significantly lowering training efficacy. Furthermore, by adding these weights to the attention layers of these models, we can adjust the effect of such additive weights as needed.
RLHF
LLM reinforcement learning human feedback (LLM RLHF) refers to a method of training large language models (LLMs) using a combination of reinforcement learning and human feedback. Reinforcement learning is a type of machine learning where an algorithm learns to make decisions by trial and error. In the context of LLMs, reinforcement learning can be used to optimize the performance of the LLM by providing it with feedback on the quality of its generated text.
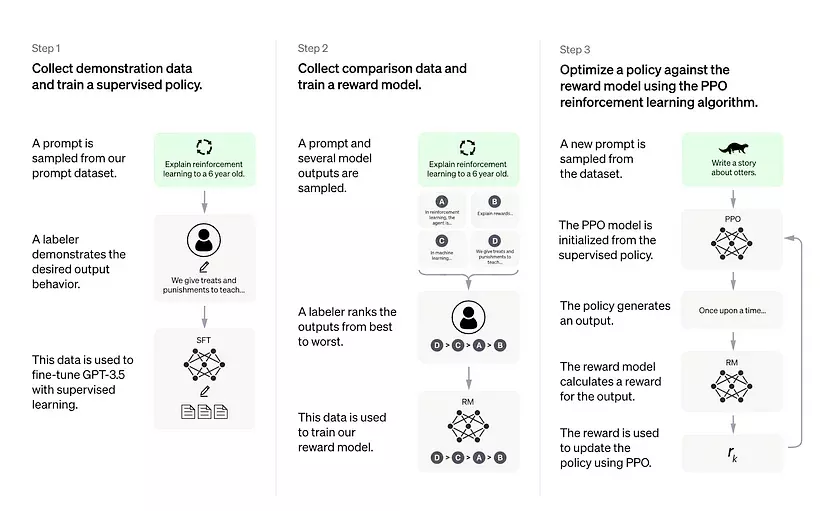
In the case of Large Language Models like Chat GPT, the sequence of events for RHLF can be broken down succinctly as follows:
- Train some generative pretrained transformer model on sufficient data
- Train a reward model that takes in a sequence of text, and returns a scalar reward which should numerically represent the human preference. This is done by using human actors to directly record there experience using the LLM
- Fine-tune the model using the reinforcement learning model trained by humans.
Together, this allows the LLM to develop beyond the effects of pure machine learning, and introduce an additional human element later in the training process. In practice, this works to massively improve the humanity and interactivity of the models responses as perceived by the user.
QLoRA
QLoRA is an efficient LLM fine-tuning approach that significantly reduces memory requirements enough to fine-tune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning task performance. (Source) QLoRA represents a quantitative step forward from the previous LoRA methodology, and though it was only recently released, its efficacy merits its inclusion in this article. QLoRA is very similar to LoRA, with a few primary differences.
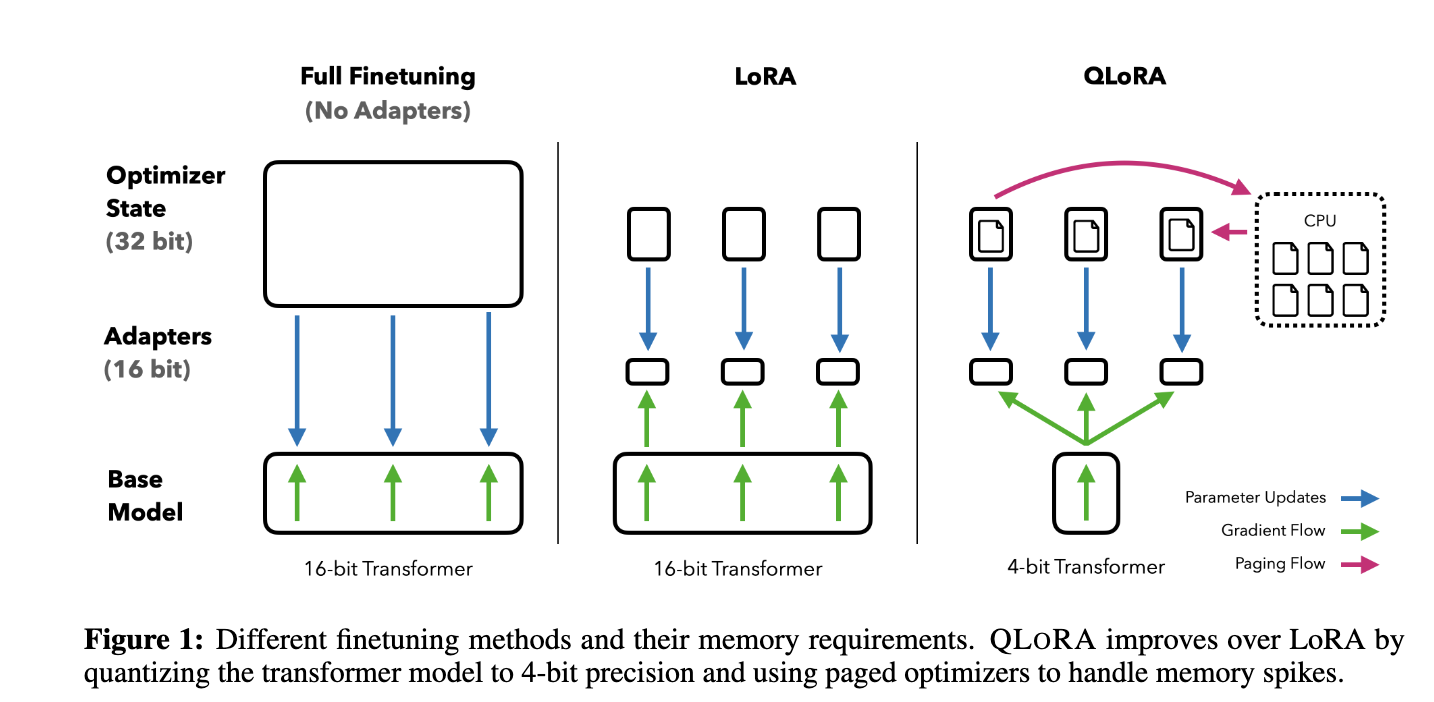
As shown in the diagram above, QLoRA differs in a few clear ways from it's predecessor, LoRA. The differences are specifically that the QLoRA method quantizes the transformer model to 4-bit precision, and uses paged optimizers in the CPU to handle any excessive data spiking. In practice, this makes it possible to fine-tune a LLM like LLaMA at significantly reduced memory requirements.
Models to know in the LLM revolution
That GPT models in the open source community have been exploding in popularity this past half year can be broadly attributed to the proliferation of Meta's LLaMa models. Though not available for commercial use, they are publicly available to researchers who fill out a simple form. This availability has lead to a massive increase in open source projects based on the LLaMa models. In this section, we will take a brief look at some of the most important of these tuned LLaMA models to be released in the past half year.
Alpaca

LLaMa-Alpaca was the first major fine-tuning project to find prominence. This project, run by researchers at Stanford, used 52k generated instruction-response sequences from OpenAI's text-davinci-003 to create a robust instruction following dataset.
The research team behidn the project quickly found that their model was achieving near SOTA results on a significantly smaller model than GPT-3.5/GPT-4. They performed a blind comparison of their newly trained model with the original text-davinci-003 model using 5 students. The blind, pairwise assesment found that the results were remarkably similar, indicating that Alpaca achieved nearly the same capabilities with a fraction of the training parameters.
The release of Alpaca lead to a slew of alternative's trained on similar datasets, and adding in additional modalities like vision.
LLaVA
LLaVA (Large Language-and-Vision Assistant) is the first and arguably most prominent of the projects seeking to merge LLaMA fine-tuning with visual understanding. This allows for the model to take in multimodal inputs, and generate thoughtful responses that demonstrate understanding of both the text and visual inputs.
Their experiments showed that LLaVA has impressive multimodel chat abilities, sometimes exhibiting similar behaviors to multimodal GPT-4 on unseen images/instructions. It was found to yield a 85.1% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset. Furthermore, when fine-tuned on Science QA, the synergy of LLaVA and GPT-4 achieves a new state-of-the-art accuracy of 92.53%.
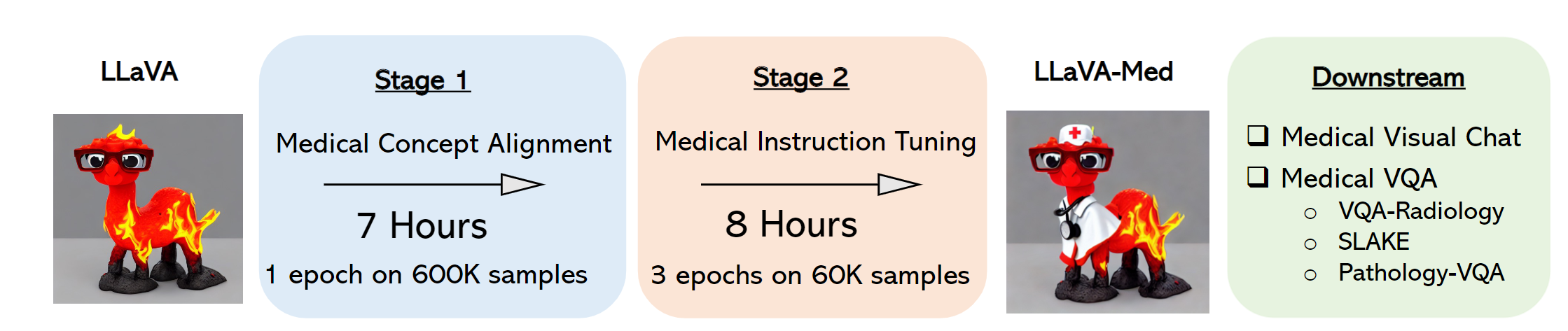
The authors have gone on to extend this project using a similar instruction tuning stategy to create LLaVA-Med. This versatility of the LLaVA model to adapt and expand to cover new and complex topics in both modalities shows that LLaVA is a model to look out for as development continues.
MPT-7B
One of our favorite open-source projects right now, the series of MosaicML Pretrained Transformers represents some of the greatest development spurned by this LLM revolution. Unlike others we are discussing today, it was developed without LLaMA and thus does not have to inherit its commercial licensing. This makes it probably the best available open source LLM right now, comparable to a tuned LLaMA 7B model.
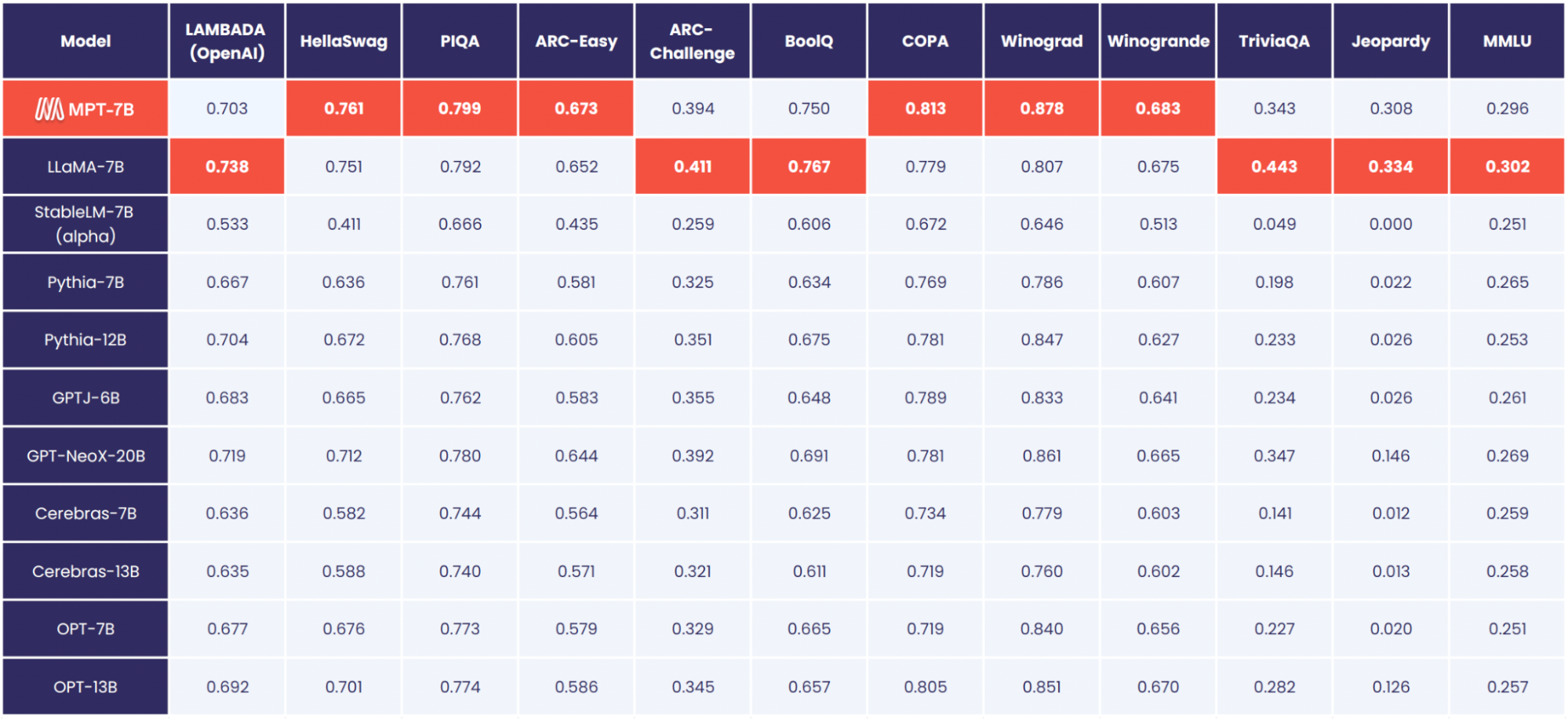
MPT-7B is extremely high performant. As you can see from the diagram above, it is comparable to LLaMA-7B's peformance across the gamut of varied tests.
MPT-7B is a transformer trained from scratch on 1T tokens of text and code. It comes with three variations:
- Chat: This is likely the most familiar model type to readers, this model is designed to output human chat-like responses
- Instruct: another common archetype for these models, as seen in Alpaca, Vicuna, etc., the instruct model is capable of interpretting complex directions and returning accurately predicted responses.
- Storywriter: the storywriter model was trained on longer sequences of writtern literature, and is capable of accurately mimicking author styles for longform story generation.
Guanaco
Introduced for the QLoRA paper, Generative Universal Assistant for Natural-language Adaptive Context-aware Omnilingual outputs (Guanaco). Guanaco is an advanced instruction-following language model built on Meta's LLaMA 7B model.
Expanding upon the initial 52K dataset from the Alpaca model, Guanaco was trained with an additional 534,530 entries covering English, Simplified Chinese, Traditional Chinese (Taiwan), Traditional Chinese (Hong Kong), Japanese, Deutsch, and various linguistic and grammatical tasks. This wealth of data enables Guanaco to perform exceptionally well in multilingual environments, and extends the capabilities of the model to cover the a wider variety of linguistic contexts.
Run any HuggingFace Space with Paperspace Gradient
Running HuggingFace Spaces on Paperspace's powerful GPUs gives users the ability to avoid queues, select from our huge variety of GPU offerings, and ensure that they have the compute required for launching the space. In this section, we will show how to run any HuggingFace space as a Gradio application in a Paperspace Gradient Notebook, and demonstrate this with the Guanaco Playground TGI.
To get started, open up a Gradient Notebook in any project and Team you choose. Be sure to choose a GPU that will be able to handle the task at hand. In this demo, i am going to be looking at an Alpaca LoRA serving application. Since it is only running the 7B version of the model, it should be able to run on 8 GB of RAM. If we want to try a more powerful GPU test, we can try the Guanaco Playground TGI on a more powerful GPU like an A100-80GB, and see how much faster it runs compared to the, likely, A10 it runs as a Space.
For a quick setup, click the link below.
Bring this project to life
Once you are in a standard Notebook, create a new notebook using the file creator in the GUI on the top left of the page. Open up the Notebook to get started with the application.
Step 1: Download git-lfs
We are going to use the git-lfs package to pull the space over. The Large File Share package makes it easier if our Space happens to have any large model checkpoints within.
!apt-get update && apt-get install git-lfsStep 2: Clone the Space onto your machine
We are going to clone the alpaca-lora Space for this demo.
# git-lfs clone <huggingface repo>
!git-lfs clone https://huggingface.co/spaces/tloen/alpaca-loraStep 3: Set up environment
We need to do two things to make sure the app runs correctly. First, we need to install the required packages. Change into the directory to do so.
%cd alpaca-lora
!pip install -r requirementsNext, we want to make the app shareable. This is the quickest way to make it accessible from our local browser when launched from a cloud machine. Open up the .py script file, and scroll down to the end of the file. Look for the .launch() method being called somewhere, and add in or edit the params within to contain share = True. This is important for accessibility.
Step 4: Launch the application
Now, everything is ready to go! Just run the following code to open up the application.
!python app.py --shareFrom there, click the shareable link, and the application will open in your local browser.
From here, we can use this augmented input-output format to synthesize text using the Alpaca LoRA 7B pretrained model.
Try out this formula on your favorite HuggingFace spaces, and get access to more GPU power, solo access to machines, and security with your HuggingFace applications!
Closing Thoughts
In conclusion, we are in the midst of rapid growth in the NLP realm of AI. This is the best time left to get involved, build understanding, and capture the power of these techologies for yourself and your own business interests.
In this article, we covered a slew of relevant topics to the LLM revolution to help facilitate the understanding of these complex systems, and showed how to launch any of the popular LLM's hosted on HuggingFace Spaces within Paperspace. Look our for future articles where we will go in further depth on fine-tuning these models, and show how to tune models in Paperspace.











