
Bring this project to life
Overview
The ongoing trend in recent Large Language Models (LLMs) development has focussed attention on larger models, often neglecting the practical requirements of on-device processing, energy efficiency, low memory footprint, and response efficiency. These factors are critical for scenarios that prioritize privacy, security, and sustainable deployment. Mobillama, a compact model is a paradigm shift towards "less is more", by tackling the challenge of crafting Small Language Models (SLMs) that are both accurate and efficient for resource-constrained devices.
The introduction of MobiLlama, an open-source SLM with 0.5 billion (0.5B) parameters released on 26th February 2024. MobiLlama is specifically designed to meet the needs of resource-constrained computing, emphasizing enhanced performance while minimizing resource demands. The SLM design of MobiLlama originates from a larger model and incorporates a parameter sharing scheme, effectively reducing both pre-training and deployment costs.
Introduction
In recent years, there has been a significant development in Large Language Models (LLMs) like ChatGPT, Bard, and Claude. These models show impressive abilities in solving complex tasks, and there's a trend of making them larger for better performance. For example, the 70 billion (70B) model of Llama-2 is preferred for handling dialogues and logical reasoning compared to its smaller counterpart.
However, a drawback of these large models is their size and the need for extensive computational resources. The Falcon 180B model, for instance, requires a substantial amount of GPUs and high-performance servers. However, we have a detailed article on how to get a hands on experience with falcon-70b using Paperspace platform.
On the other hand, Small Language Models (SLMs), like Microsoft's Phi-2 2.7 billion, are gaining attention. These smaller models show decent performance with fewer parameters, offering advantages in efficiency, cost, flexibility, and customizability. SLMs are more resource-efficient, making them suitable for applications where efficient resource use is crucial, especially on low-powered devices like edge devices. They also support on-device processing, leading to enhanced privacy, security, response time, and personalization. This integration could result in advanced personal assistants, cloud-independent applications, and improved energy efficiency with a reduced environmental impact.
Architecture Brief Overview
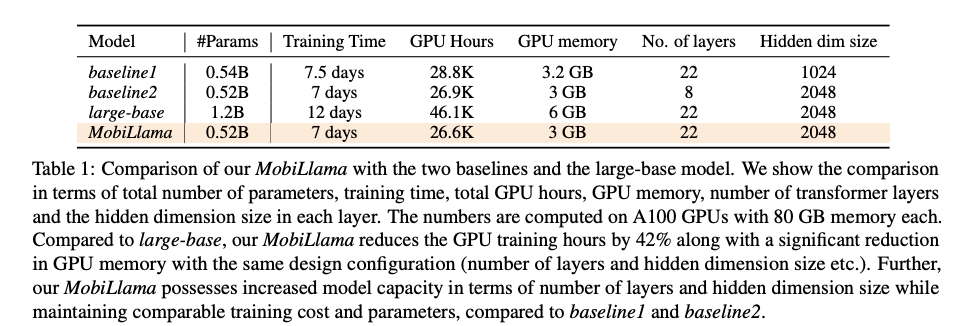
The Mobillama, baseline Small Language Model (SLM) architecture of 0.5 billion (0.5B) parameters, is inspired by TinyLlama and Llama-2 models. This baseline has N layers with hidden dimensions of M and intermediate size (MLPs) of 5632. The vocabulary size is 32,000, and the maximum context length is denoted as C.
- Baseline1: This has 22 layers with a hidden size of 1024.
- Baseline2: This has 8 layers with a hidden size of 2048.
Both of the baselines faced challenges in balancing accuracy and efficiency. Baseline1, with a smaller hidden size, enhances computational efficiency but may compromise the model's ability to capture complex patterns. Baseline2, with fewer layers, hampers the model's depth and its capability for deep linguistic understanding.
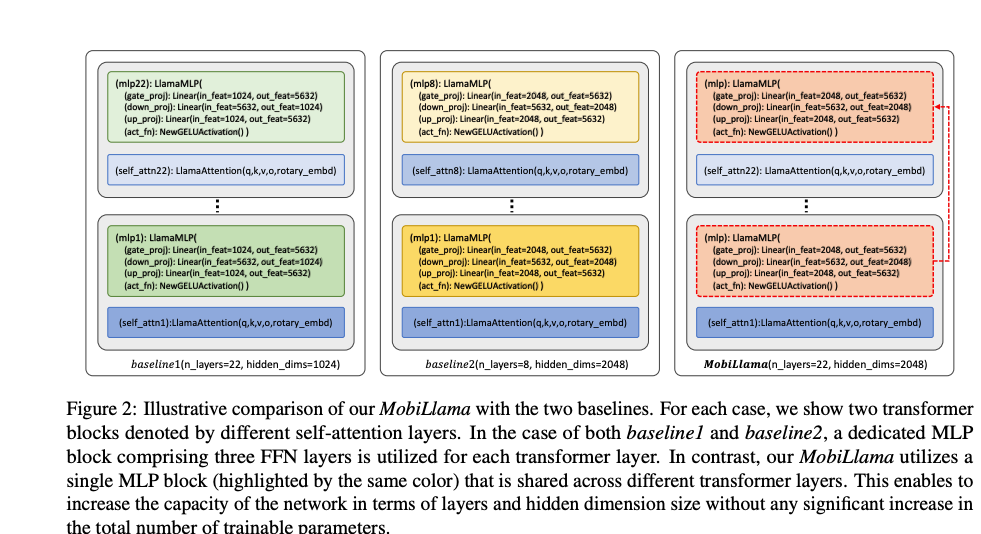
To address these issues, combining the advantages of both baselines into a single model (22 layers and hidden size of 2048) results in a larger 1.2 billion (1.2B) parameterized model called "largebase," with increased training costs.
The authors then introduce their proposed MobiLlama 0.5B model design, aiming to maintain hidden dimension size and the total number of layers while ensuring comparable training efficiency. This new design seeks to achieve a balance between computational efficiency and the model's capacity to understand complex language patterns.
Paperspace Demo & Code Explanation
Bring this project to life
Let us jump to the most intersting part to make the model working using Paperspace powerful A6000.
- Begin with installing and updating the required packages.
!pip install -U transformers
!pip install flash_attnfrom transformers import AutoTokenizer, AutoModelForCausalLM
- Load the pre-trained tokenizer for the model called "MBZUAI/MobiLlama-1B-Chat."
tokenizer = AutoTokenizer.from_pretrained("MBZUAI/MobiLlama-1B-Chat", trust_remote_code=True)
- Next load the pre-trained language model for language modeling associated with the "MBZUAI/MobiLlama-1B-Chat" model using the Hugging Face Transformers library. Further, move the model to cuda device.
model = AutoModelForCausalLM.from_pretrained("MBZUAI/MobiLlama-1B-Chat", trust_remote_code=True)
model.to('cuda')
- Define a template for the response.
template= "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n### Human: Got any creative ideas for a 10 year old’s birthday?\n### Assistant: Of course! Here are some creative ideas for a 10-year-old's birthday party:\n1. Treasure Hunt: Organize a treasure hunt in your backyard or nearby park. Create clues and riddles for the kids to solve, leading them to hidden treasures and surprises.\n2. Science Party: Plan a science-themed party where kids can engage in fun and interactive experiments. You can set up different stations with activities like making slime, erupting volcanoes, or creating simple chemical reactions.\n3. Outdoor Movie Night: Set up a backyard movie night with a projector and a large screen or white sheet. Create a cozy seating area with blankets and pillows, and serve popcorn and snacks while the kids enjoy a favorite movie under the stars.\n4. DIY Crafts Party: Arrange a craft party where kids can unleash their creativity. Provide a variety of craft supplies like beads, paints, and fabrics, and let them create their own unique masterpieces to take home as party favors.\n5. Sports Olympics: Host a mini Olympics event with various sports and games. Set up different stations for activities like sack races, relay races, basketball shooting, and obstacle courses. Give out medals or certificates to the participants.\n6. Cooking Party: Have a cooking-themed party where the kids can prepare their own mini pizzas, cupcakes, or cookies. Provide toppings, frosting, and decorating supplies, and let them get hands-on in the kitchen.\n7. Superhero Training Camp: Create a superhero-themed party where the kids can engage in fun training activities. Set up an obstacle course, have them design their own superhero capes or masks, and organize superhero-themed games and challenges.\n8. Outdoor Adventure: Plan an outdoor adventure party at a local park or nature reserve. Arrange activities like hiking, nature scavenger hunts, or a picnic with games. Encourage exploration and appreciation for the outdoors.\nRemember to tailor the activities to the birthday child's interests and preferences. Have a great celebration!\n### Human: {prompt}\n### Assistant:"
- Use the pre-trained model to generate response for the prompt regarding practicing mindfulness. The
generatemethod is used for text generation, and parameters such asmax_lengthcontrol the maximum length of the generated text, andpad_token_idspecifies the token ID for padding.
prompt = "What are the key benefits of practicing mindfulness meditation?"
input_str = template.format(prompt=prompt)
input_ids = tokenizer(input_str, return_tensors="pt").to('cuda').input_ids
outputs = model.generate(input_ids, max_length=1000, pad_token_id=tokenizer.eos_token_id)
print(tokenizer.batch_decode(outputs[:, input_ids.shape[1]:-1])[0].strip())
output: -
Mindfulness meditation is a practice that helps individuals become more aware of their thoughts, emotions, and physical sensations. It has several key benefits, including:
1. Reduced stress and anxiety: Mindfulness meditation can help reduce stress and anxiety by allowing individuals to focus on the present moment and reduce their thoughts and emotions.
2. Improved sleep: Mindfulness meditation can help improve sleep quality by reducing stress and anxiety, which can lead to better sleep.
3. Improved focus and concentration: Mindfulness meditation can help improve focus and concentration by allowing individuals to focus on the present moment and reduce their thoughts and emotions.
4. Improved emotional regulation: Mindfulness meditation can help improve emotional regulation by allowing individuals to become more aware of their thoughts, emotions, and physical sensations.
5. Improved overall well-being: Mindfulness meditation can help improve overall well-being by allowing individuals to become more aware of their thoughts, emotions, and physical sensations.We have added the link to the notebook, please feel free to check the model and the Paperspace platform to experiment further.
Conclusion
In this article we have experimented with a new SLM called MobiLlama that makes a part of the transformer block more efficient by reducing unnecessary repetition. In MobiLlama, authors suggested using a shared design for part of the system called feed forward layers (FFN) across all the blocks in the SLM. MobiLlama was tested on nine different tasks and found that it performs well compared to other methods for models with less than 1 billion parameters. This model efficiently handles both text and images together, making it a versatile SLM.
However, there are some limitations. We think there's room to make MobiLlama even better at understanding context. While MobiLlama is designed to be very clear in how it works, it's important for us to do more research to make sure it doesn't accidentally show any wrong or biased information.
We hope you enjoyed the article and the demo of Mobillama!








