

Bring this project to life
Object detection is a technology in the field of computer vision, which enables machines to identify and locate various objects within digital images or video frames. This process involves not only recognizing the presence of objects but also precisely drawing specific boundaries around the object. Object detection finds extensive applications across multiple industries, from enhancing surveillance systems and autonomous vehicles to healthcare and retail domain. This powerful technology is the stepping stone of transforming how machines perceive and interact with the visual world.
What is new in YOLOv9
Traditional deep neural network suffers from problem such as vanishing gradient and exploding gradient however, techniques such as batch normalization and activation functions have mitigated this issue to quite some extent. YOLOv9 released by Chien-Yao Wang et al. on Februrary 21st, 2024, a recent addition to the YOLO series model takes a deeper look at the analyzing the problem of information bottleneck. This issue was not addressed in previous YOLO series. Whats new in YOLO!!
The components which we have discussed going forward.
Components of YOLOv9
YOLO models are the most widely used object detector in the field of computer vision. In the YOLOv9 paper, YOLOv7 has been used as the base model and further developement has been proposed with this model. There are four crucial concepts discussed in YOLOv9 paper and they are Programmable Gradient Information (PGI), the Generalized Efficient Layer Aggregation Network (GELAN), information bottleneck principle, reversible functions. YOLOv9 as of now, is capable of object detection, segmentation, and classification.
YOLOv9 comes in four models, ordered by parameter count:
- v9-S
- v9-M
- v9-C
- v9-E
Reversible Network Architecture
While one approach to combat information loss is to increase parameters and complexity in neural networks, it brings about challenges such as overfitting. Therefore, the reversible function approach is introduced as a solution. By incorporating reversible functions, the network can effectively preserve sufficient information, enabling accurate predictions without the overfitting issues.
Reversible architectures in neural networks maintain the original information in each layer by ensuring that the operations can reverse their inputs back to their original form. This addresses the challenge of information loss during transformation in networks, as highlighted by the information bottleneck principle. This principle suggests that as data progresses through successive layers, there's an increasing risk of losing vital information.
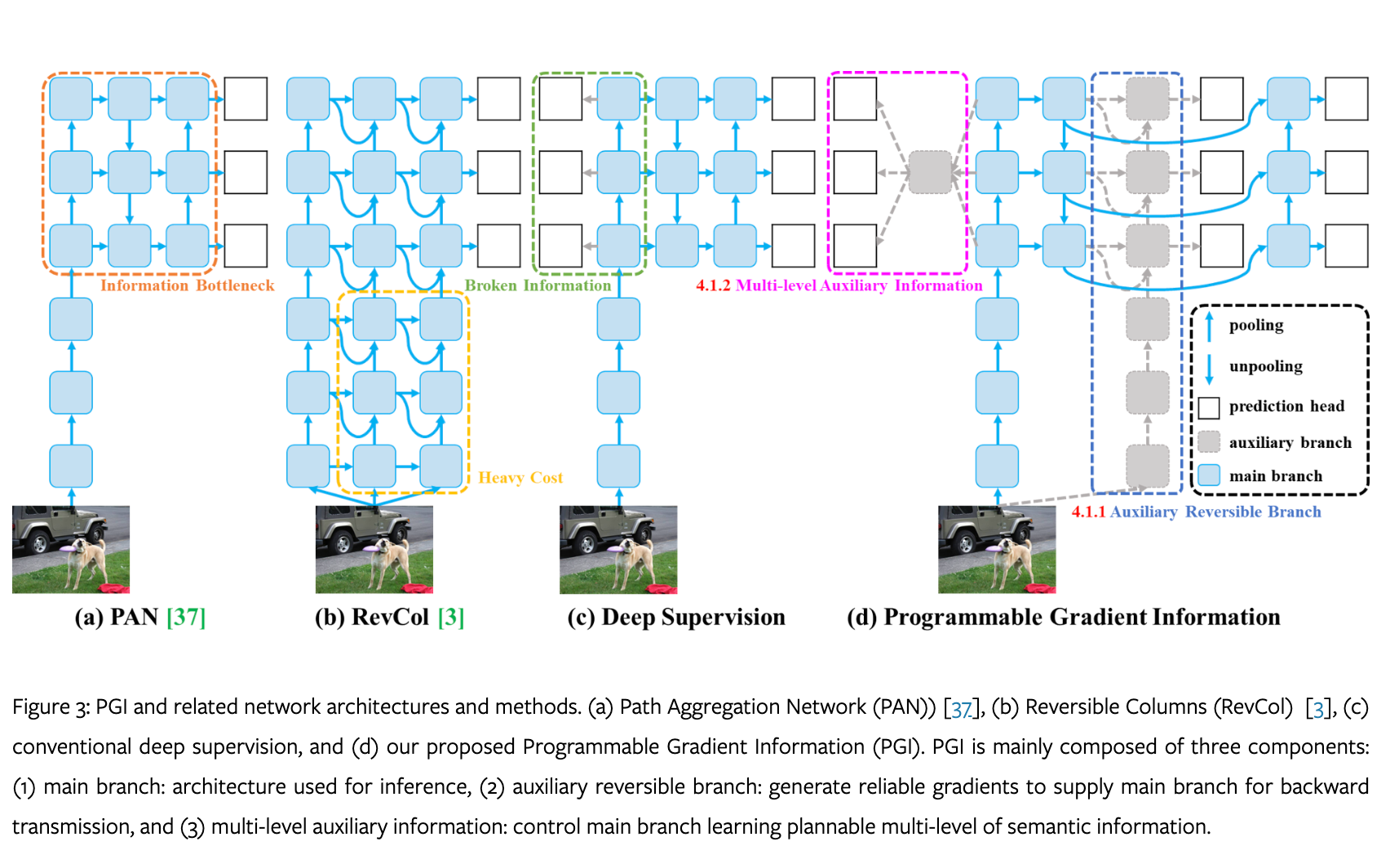
Information Bottleneck
Information bottleneck in simpler terms is an issue where the information gets lost as the density of the neural network increases. One of the major consequences of information loss is the networks ability to accurately predict target is compromised.
As the number of network layer becomes deeper, the original data will be more likely to be lost.
In deep neural networks, different parameters are determined by comparing the network's output to the target and adjusting the gradient based on the loss function. However, in deeper networks, the output might not fully capture the target information, leading to unreliable gradients and poor learning. One solution is to increase the model size with more parameters, allowing better data transformation. This helps retain enough information for mapping to the target, highlighting the importance of width over depth. Yet, this doesn't completely solve the issue.
Introducing reversible functions is a method to address unreliable gradients in very deep networks.
Programmable Gradient Information
A new auxiliary supervision framework called Programmable Gradient Information (PGI), as shown in the above Figure is proposed in this paper. PGI comprises of three key elements: the main branch, an auxiliary reversible branch, and multi-level auxiliary information. The figure above illustrates that the inference process solely relies on the main branch (d), eliminating any additional inference costs. The auxiliary reversible branch addresses challenges arising from deepening neural networks, mitigating information bottlenecks and ensuring reliable gradient generation. On the other hand, multi-level auxiliary information tackles error accumulation issues related to deep supervision, particularly beneficial for architectures with multiple prediction branches and lightweight models. Feel free to read the research paper to find out more on each branch.
Generalized ELAN
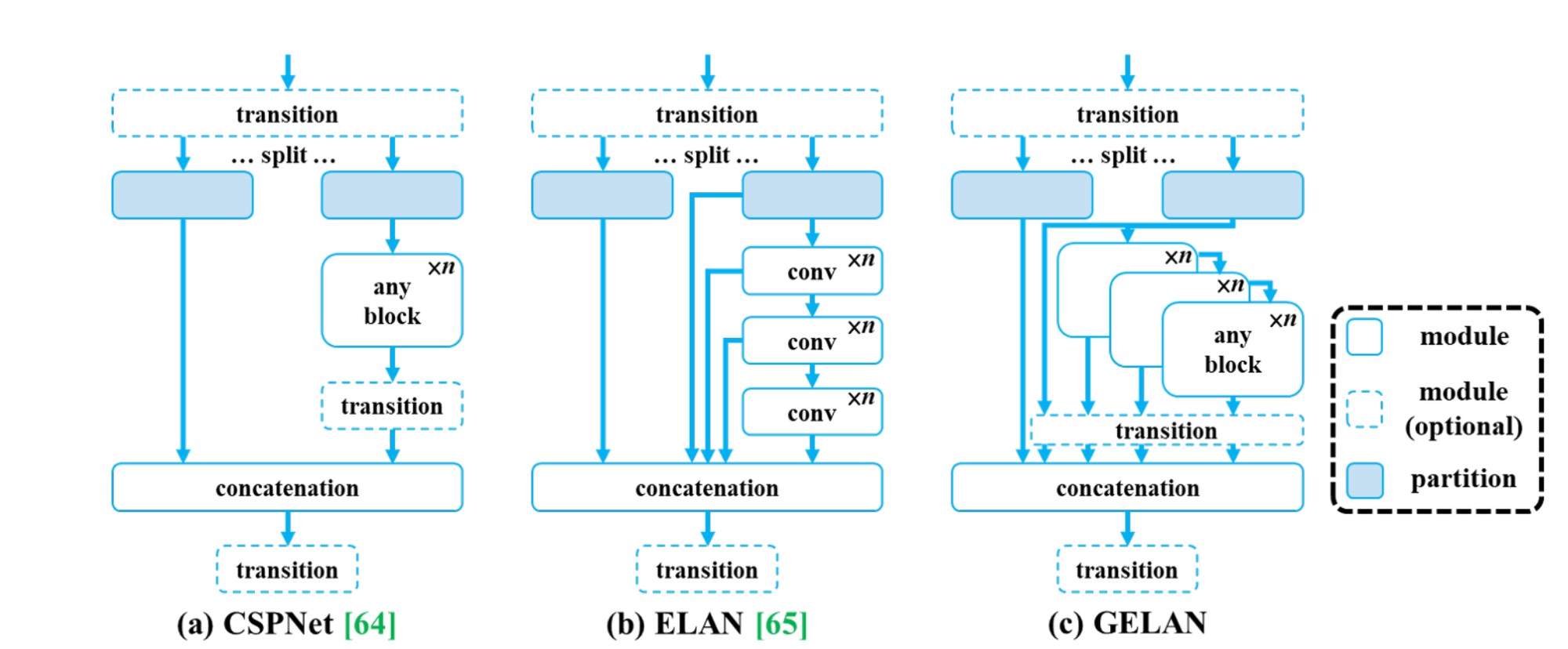
This paper proposed GELAN, a novel network architecture that merges the features of two existing neural network designs, CSPNet and ELAN, both crafted with gradient path planning. This innovative research, prioritizes lightweight design, fast inference speed, and accuracy. The comprehensive architecture, illustrated in the Figure above, extends the capabilities of ELAN, initially limited to stacking convolutional layers, to a versatile structure accommodating various computational blocks.
The proposed method was verified using the MSCOCO dataset and the total number of training included 500 epochs.
Comparison with state-of-the-arts
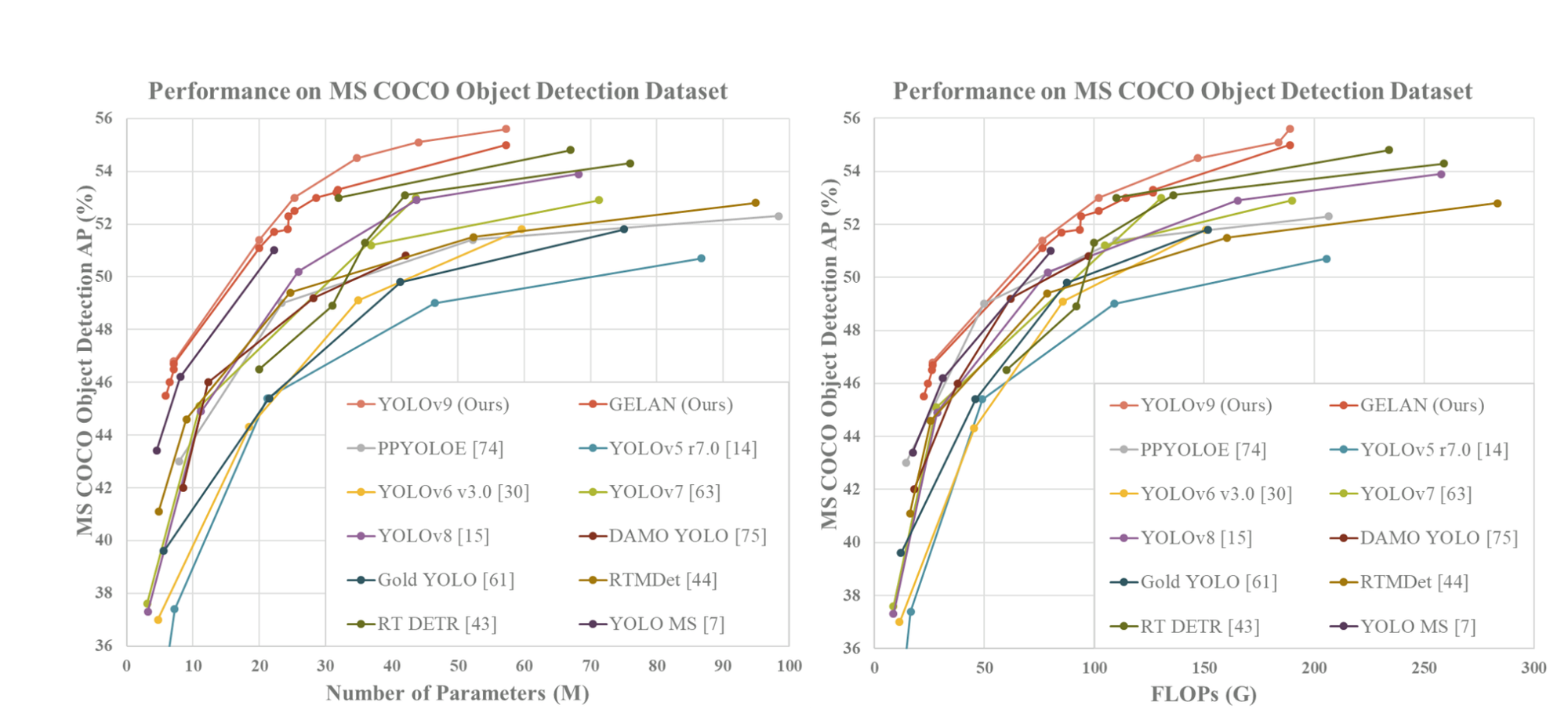
In general, the most effective methods among the existing ones are YOLO MS-S for lightweight models, YOLO MS for medium models, YOLOv7 AF for general models, and YOLOv8-X for large models. When comparing with YOLO MS for lightweight and medium models, YOLOv9 has approximately 10% fewer parameters and requires 5-15% fewer calculations, yet it still shows a 0.4-0.6% improvement in Average Precision (AP). In comparison to YOLOv7 AF, YOLOv9-C has 42% fewer parameters and 22% fewer calculations while achieving the same AP (53%). Lastly, when compared to YOLOv8-X, YOLOv9-E has 16% fewer parameters, 27% fewer calculations, and a noteworthy improvement of 1.7% in AP. Further, ImageNet pretrained model is also included for the comparison and it is based on the parameters and the amount of computation the model takes. RT-DETR has performed the best considering the number of parameters.
YOLOv9 Demo
Bring this project to life
To find out the model performance let us run the model using Paperspace platform.
Let's begin by quickly verifying the GPU we're currently utilizing.
!nvidia-smi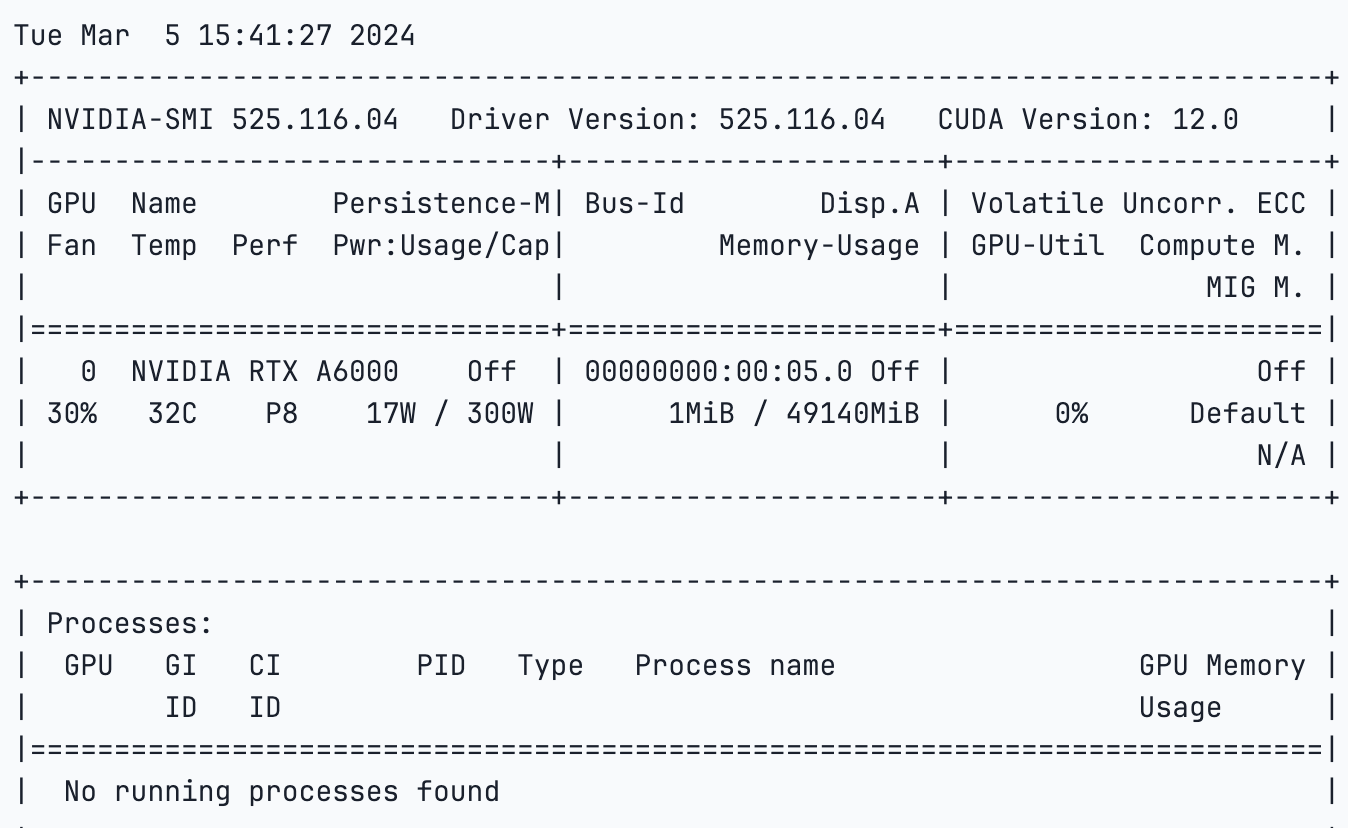
- Clone the yolov9 repository and install the requirements.txt to install the necessary packages required to run the model.
# clone the repo and install requiremnts.txt
!git clone https://github.com/WongKinYiu/yolov9.git
%cd yolov9
!pip install -r requirements.txt -q- Create a weights folder and download the pre-trained weights and save them in the created 'weights' folder
# create a folder and download the weights and save them to the created folder
!mkdir -p {HOME}/weights
!wget -P {HOME}/weights -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/yolov9-c.pt
!wget -P {HOME}/weights -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/yolov9-e.pt
!wget -P {HOME}/weights -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/gelan-c.pt
!wget -P {HOME}/weights -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/gelan-e.pt- The below command creates a directory named 'data' and download an image from the provided URL. Next, save the image to the 'data' directory within the home folder.
# download and save the image from the url
!mkdir -p {HOME}/data
!wget -P {HOME}/data -q https://www.petpipers.com/wp-content/uploads/2019/05/Two-dogs-on-a-walk.jpg
SOURCE_IMAGE_PATH = f"{HOME}/Two-dogs-on-a-walk.jpg"- Next, we will run the python script '!python detect.py' to detect the objects in the image using pre-trained weights.
!python detect.py --weights {HOME}/weights/gelan-c.pt --conf 0.1 --source {HOME}/data/Two-dogs-on-a-walk.jpg --device 0
Please note here that the confidence threshold '--conf 0.1' for object detection is set to 0.1. It means that only detections with a confidence score greater than or equal to 0.1 will be considered.
In summary, the command runs an object detection script (detect.py) with the pre-trained weights ('gelan-c.pt'), with a confidence threshold of 0.1, and the specified input image ('Two-dogs-on-a-walk.jpg') located in the 'data' directory. The detection will be performed on the specified device (GPU 0 in this case).
- Let us review how the model performed
from IPython.display import Image
Image(filename=f"{HOME}/yolov9/runs/detect/exp4/Two-dogs-on-a-walk.jpg", width=600)

We've included all the essential links to provide access to the notebook and effortlessly execute the model. Additionally, we've provided a notebook 'yolov9.ipynb' containing the code for running the Gradio-powered HuggingFace Space on Paperspace Notebooks, enabling the creation of publicly accessible web applications.
These web applications have proven to be one of the most reliable ways to share novel AI projects with the greater community. The Gradio applications are low code applications and allows users with little to no coding knowledge to use AI for whatever purpose.
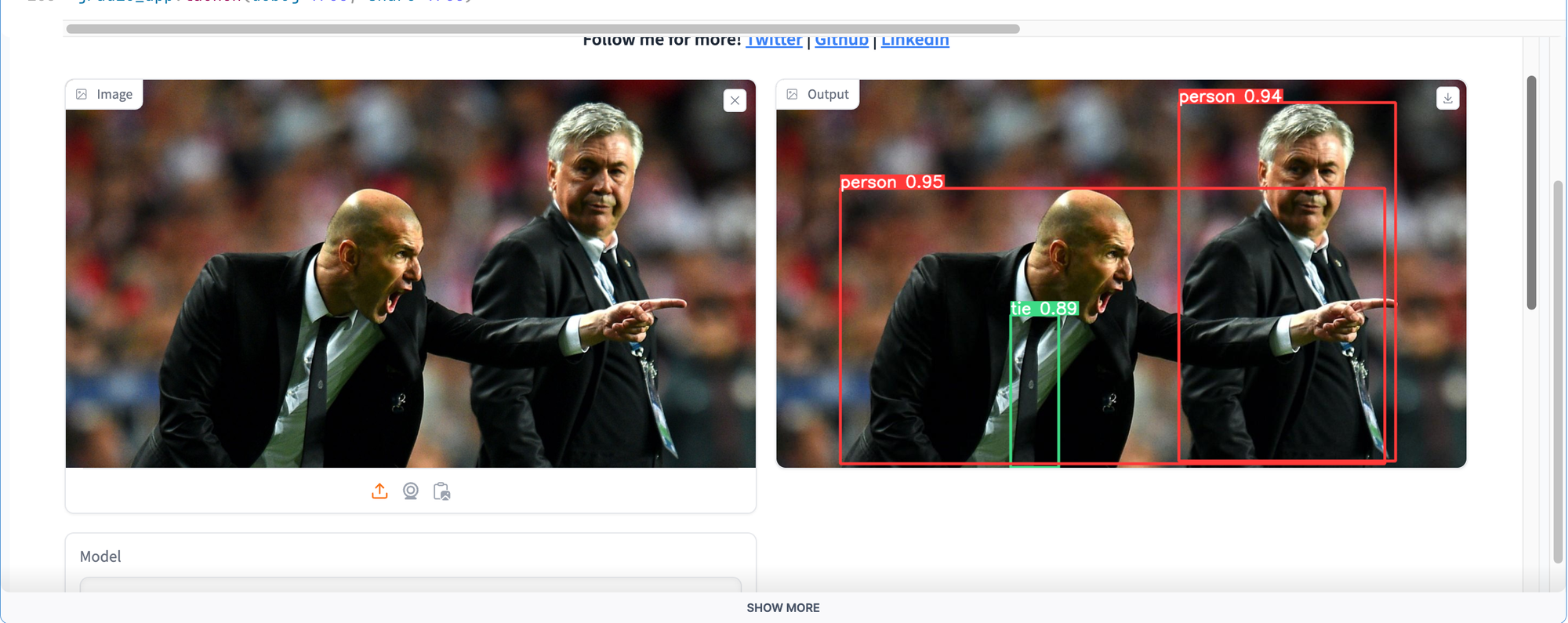
We have provided a notebook named 'yolo9.ipynb' file, run the code cells to built the gradio web app.
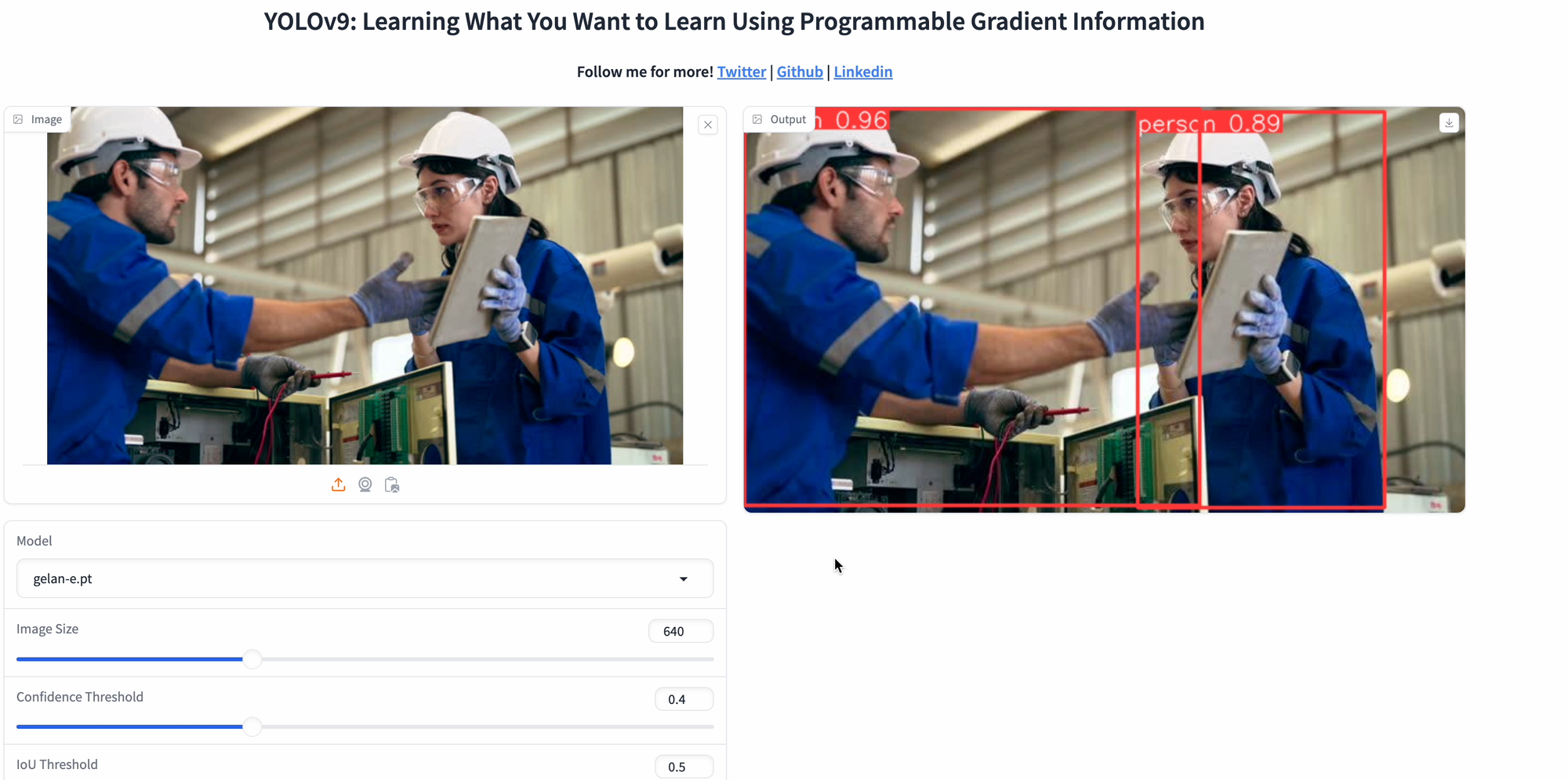
Conclusion
In this article, we discussed YOLOv9 an object detection model released recently. YOLOv9 proposed using PGI to address the information bottleneck problem and the challenge of the deep supervision mechanism not being suitable for lightweight neural networks. The research proposed GELAN, a highly efficient and lightweight neural network. When it comes to object detection, GELAN performs well across different computational blocks and depth settings. It can be easily adapted for various devices used for inference. By introducing PGI, both lightweight and deep models can achieve significant improvements in accuracy.
Combining PGI with GELAN in the design of YOLOv9 demonstrates strong competitiveness. YOLOv9, with this combination, manages to reduce the number of parameters by 49% and calculations by 43% compared to YOLOv8. Despite these reductions, the model still achieves a 0.6% improvement in Average Precision on the MS COCO dataset.
References
Bring this project to life











