

Introduction
The transformer-based diffusion models are improving day by day and have proven to revolutionize the text-to-image generation model. The capabilities of transformers enhance the scalability and performance of any model, thereby increasing the model's complexity.
In this case, with great model complexities comes great power and memory consumption.
For instance, running inference with models like Stable Diffusion 3 requires a huge GPU memory, due to the involvement of components—text encoders, diffusion backbones, and image decoders. This high memory requirement causes set back for those using consumer-grade GPUs, which hampers both accessibility and experimentation.
Enter Model Quantization. Imagine being able to scale down a resource-hungry model to a more manageable size without sacrificing its effectiveness. Quantization, is like compressing a high-resolution image into a more compact format, transforms the model’s parameters into lower-precision representations. This not only reduces memory usage but also speeds up computations, making complex models more accessible and easier to work with.
In this post, we explore how Quanto's quantization tools can significantly enhance the memory efficiency of Transformer-based diffusion pipelines.
Introducing Quanto: A Versatile PyTorch Quantization Backend
Quantization is a crucial technique for reducing the computational and memory demands of Deep Learning Models, making them more suitable for deployment on consumer devices. By using low-precision data types like 8-bit integers (int8) instead of 32-bit floating points (float32), quantization not only decreases memory storage requirements but also enables optimizations for specific hardware, such as int8 or float8 matrix multiplications on CUDA devices.
Introducing Quanto, a new quantization backend for Optimum, designed to offer a versatile and straightforward quantization process. Quanto stands out with its comprehensive support for various features, ensuring compatibility with diverse model configurations and devices:
- Eager Mode Compatibility: Works seamlessly with non-traceable models.
- Device Flexibility: Quantized models can be deployed on any device, including CUDA and MPS.
- Automatic Integration: Inserts quantization/dequantization stubs, functional operations, and quantized modules automatically.
- Streamlined Workflow: Provides an effortless transition from a float model to both dynamic and static quantized models.
- Serialization Support: Compatible with PyTorch
weight_onlyand 🤗 Safetensors formats. - Accelerated Matrix Multiplications: Supports various quantization formats (int8-int8, fp16-int4, bf16-int8, bf16-int4) on CUDA devices.
- Wide Range of Support: Handles int2, int4, int8, and float8 weights and activations.
While many tools focus on making large AI models smaller, Quanto is designed to be simple and useful for all kinds of models.
Quanto Workflow
To install Quanto using pip, please use the code below:-
!pip install optimum-quanto- Quantize a Model
The below code will help to convert a standard model to a quantized model
from optimum.quanto import quantize, qint8
quantize(model, weights=qint8, activations=qint8)- Calibrate
Quanto’s calibration mode ensures that the quantization parameters are adjusted to the actual data distributions in the model, enhancing the accuracy and efficiency of the quantized model.
from optimum.quanto import Calibration
with Calibration(momentum=0.9):
model(samples)
- Quantization-Aware-Training
In case the model performance is effected one can tune the model for few epochs to enhance the model performance.
import torch
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data).dequantize()
loss = torch.nn.functional.nll_loss(output, target)
loss.backward()
optimizer.step()
- Freeze integer weights
While freezing the model, the float weights gets converted to quantized weights.
from optimum.quanto import freeze
freeze(model)H100 Benchmarking Study
The H100 GPU is a high-performance graphics card designed specifically for demanding AI tasks, including training and inference for large models like transformers and diffusion models. Here’s why it’s chosen for this benchmark:
- Top-tier Performance: The H100 offers exceptional speed and power, making it ideal for handling complex operations required by large models like text-to-image and text-to-video generation pipelines.
- Support for FP16: This GPU efficiently handles computations in FP16 (half-precision floating point), which reduces memory usage and speeds up calculations without significantly sacrificing accuracy.
- Advanced Hardware Features: The H100 supports optimized operations for mixed-precision training and inference, making it an excellent choice for quantization techniques that aim to reduce model size while maintaining performance.
In the benchmarking study, the main focus is on applying Quanto, a new quantization tool, to diffusion models. While quantization is well-known among practitioners of Large Language Models (LLMs), it’s less commonly used with diffusion models. Quanto is used to explore whether it can provide memory savings in these models with little or no loss in quality.
Here's what the study involves:
- Environment Setup:
- CUDA 12.2: The version of CUDA used, which is crucial for running computations on the H100 GPU.
- PyTorch 2.4.0: The deep learning framework used for model training and inference.
- Diffusers: A library used for building and running diffusion models, installed from a specific commit to ensure consistency.
- Quanto: The quantization tool, also installed from a specific commit.
- Computations in FP16: By default, all computations were performed in FP16 to reduce memory usage and increase speed. However, the VAE (Variational Autoencoder) is not quantized to avoid potential numerical instability.
- Focus on Key Pipelines: For this study, three transformer-based diffusion pipelines are selected from Diffusers. These pipelines are chosen because they represent some of the most advanced models for text-to-image generation, making them ideal for testing the effectiveness of Quanto in reducing memory usage while maintaining model quality.
- PixArt-Sigma
- Stable Diffusion 3
- Aura Flow
By using the H100 GPU and focusing on these key models, the study aims to demonstrate the potential of Quanto to bridge the gap between LLMs and diffusion models in terms of quantization, offering significant memory savings with minimal impact on performance.
| Model | Checkpoint | # Params(Billions) |
|---|---|---|
| PixArt | https://huggingface.co/PixArt-alpha/PixArt-Sigma-XL-2-1024-MS | 0.611 |
| Stable Diffusion 3 | https://huggingface.co/stabilityai/stable-diffusion-3-medium-diffusers | 2.028 |
| Aura Flow | https://huggingface.co/fal/AuraFlow/ | 6.843 |
Applying Quanto to Quantize a DiffusionPipeline
Quantizing a model using quanto follows a straightforward process:-
First install the required packages, here we are installing transformers, quanto, torch, sentencepiece. However please note you might need to install a few more packages as per requirement.
!pip install transformers==4.35.0
!pip install quanto==0.0.11
!pip install torch==2.1.1
!pip install sentencepiece==0.2.0
!pip install optimum-quanto
The quantize() function is called on the module to be quantized, specifying the components targeted for quantization. In this context, only the parameters are being quantized, while the activations remain unchanged. The parameters are quantized to the FP8 data type. Finally, the freeze() function is invoked to replace the original parameters with the newly quantized ones.
from optimum.quanto import freeze, qfloat8, quantize
from diffusers import PixArtSigmaPipeline
import torch
pipeline = PixArtSigmaPipeline.from_pretrained(
"PixArt-alpha/PixArt-Sigma-XL-2-1024-MS", torch_dtype=torch.float16
).to("cuda")
quantize(pipeline.transformer, weights=qfloat8)
freeze(pipeline.transformer)
Once done use the pipeline.
image = pipeline("ghibli style, a fantasy landscape with castles").images[0]

The below code can be used to quantize the text encoder.
quantize(pipeline.text_encoder, weights=qfloat8)
freeze(pipeline.text_encoder)
The text encoder, being a transformer model as well, can also be quantized. By quantizing both the text encoder and the diffusion backbone, significantly greater memory savings are achieved.
LLM Pipelines
optimum-quanto provides helper classes to quantize, save and reload Hugging Face quantized models. The code below will load the pre-trained language model (Meta-Llama-3-8B) using the Transformers library. It then applies quantization to the model using the QuantizedModelForCausalLM class from Optimum Quanto, specifically converting the model's weights to the qint4 data type. The lm_head (output layer) is excluded from quantization to preserve its precision, ensuring that the final output quality remains high.
from transformers import AutoModelForCausalLM
from optimum.quanto import QuantizedModelForCausalLM, qint4
model = AutoModelForCausalLM.from_pretrained('meta-llama/Meta-Llama-3-8B')
qmodel = QuantizedModelForCausalLM.quantize(model, weights=qint4, exclude='lm_head')# quantized model can be saved using save_pretrained
qmodel.save_pretrained('./Llama-3-8B-quantized')
# reload the model using from_pretrained
from optimum.quanto import QuantizedModelForCausalLM
qmodel = QuantizedModelForCausalLM.from_pretrained('Llama-3-8B-quantized')Integrations with the Transformers
Quanto seamlessly integrates with the Hugging Face transformers library. Any model can be quantized by just passing the model through QuantoConfig.
from transformers import AutoModelForCausalLM, AutoTokenizer, QuantoConfig
model_id = "facebook/opt-125m"
tokenizer = AutoTokenizer.from_pretrained(model_id)
quantization_config = QuantoConfig(weights="int8")
quantized_model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config= quantization_config
)
from transformers import AutoModelForSpeechSeq2Seq
model_id = "openai/whisper-large-v3"
quanto_config = QuantoConfig(weights="int8")
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="cuda",
quantization_config=quanto_config
)
Tensors in Quanto:
- What Quanto Does: Quanto works with special Tensors (data structures) that it modifies to fit into smaller data types, like int8 or float8. This makes the model more memory-efficient and faster to run.
- Conversion Process:
- For floating-point numbers, it simply uses PyTorch’s built-in conversion.
- For integers, it rounds the numbers to fit them into the smaller data type.
- Accuracy: Quanto tries to keep the conversion accurate by avoiding too many extreme values (either too large or too small) that can distort the model’s performance.
- Optimized Operations: Using these smaller data types (lower-bitwidth) allows the model to run faster because the operations for these types are quicker.
Modules in Quanto:
- Replacing Torch Modules: Quanto can swap out regular PyTorch components with special Quanto versions that work with these smaller Tensors.
- Weight Conversion: When the model is still being fine-tuned, the weights (the model’s adjustable parameters) are dynamically converted, which might slow things down a bit. But once the model is finalized (frozen), this conversion stops.
- Biases: Biases (another set of model parameters) aren’t converted because converting them would either reduce accuracy or require very high precision, making it inefficient.
- Activations: The model's activations (intermediate outputs) are also converted to smaller data types, but only after the model is calibrated to find the best conversion settings.
Modules That Can Be Quantized:
- Linear Layers: These are fully connected layers in the model where weights are always quantized, but biases are left as they are.
- Conv2D Layers: These are convolutional layers often used in image processing. Here, weights are also always quantized, and biases are not.
- LayerNorm: This normalizes data in the model. In Quanto, the outputs can be quantized, but weights and biases are left as they are.
This setup allows models to become smaller and faster while still maintaining a good level of accuracy.
Final Observations from the Study
Quantizing the text encoder in diffusion models, such as those used in Stable Diffusion, can significantly affect performance and memory efficiency. For Stable Diffusion 3, which uses three different text encoders, the observations related to quantizing these encoders are as follows:
- Quantizing the Second Text Encoder: This approach does not work well, likely due to the specific characteristics of the second encoder.
- Quantizing the First Text Encoder (CLIPTextModelWithProjection): This option is recommended and generally effective, as the first encoder's quantization provides a good balance between memory savings and performance.
- Quantizing the Third Text Encoder (T5EncoderModel): This approach is also recommended. Quantizing the third encoder can lead to substantial memory savings without significantly impacting the model's performance.
- Quantizing Both the First and Third Text Encoders: Combining the quantization of both the first and third text encoders can be a good strategy for maximizing memory efficiency while maintaining acceptable performance levels.
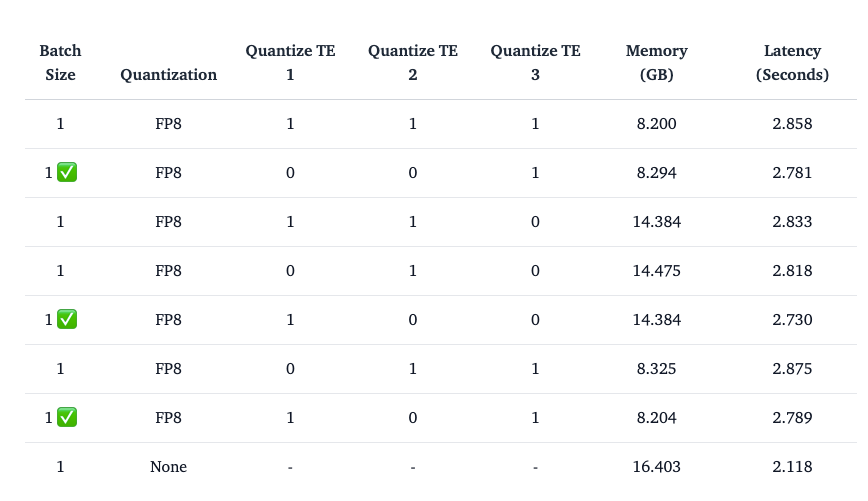
- Quantizing the diffusion transformer in all cases ensures that the observed memory savings are primarily due to the text encoder quantization.
- Using the bfloat16 can be faster when powerful GPUs such as H100 or 4090 are considered.
qint8is generally faster for inference due to efficient integer operations and hardware optimization.- Fusing QKV Projections thickens the int8 kernels, which optimizes computation further by reducing the number of operations and leveraging efficient data processing.
- When using
qint4withbfloat16on an H100 GPU, results improvements in memory usage becauseqint4uses only 4 bits per value, which reduces the amount of memory needed to store the weights. However, this comes at the cost of increased inference latency. This is because the H100 GPU still does not support computations with 4-bit integers (int4). Although the weights are stored in a compressed 4-bit format, the actual computations are still performed inbfloat16(a 16-bit floating-point format), which means the hardware has to handle more complex operations, leading to slower processing times.
Conclusions
Quanto offers a powerful quantization backend for PyTorch, optimizing model performance by converting weights to lower precision formats. By supporting techniques like qint8 and qint4, Quanto reduces memory consumption and speeds up inference. Additionally, Quanto works across different devices (CPU, GPU, MPS) and is compatible with various setups. However, on MPS devices, using float8 will cause an error.
Overall, Quanto enables more efficient deployment of deep learning models, balancing memory savings with performance trade-offs.







