

Bring this project to life
The recent paper on MIGC: Multi-Instance Generation Controller for Text-to-Image Synthesis, released on 24 February 2024, introduces a new task called Multi-Instance Generation (MIG). The goal here is to create multiple objects in an image, each with specific attributes and positioned accurately. The novel approach, Multi-Instance Generation Controller (MIGC), breaks down this task into smaller parts and uses an attention mechanism to ensure precise rendering of each object. Next, these rendered objects are combined to create the final image. A benchmark called COCO-MIG is created to evaluate the models on this task, and the experiments show that this approach gives exceptional control over the quantity, position, attributes, and interactions of the generated objects.
This article provides a detailed review on the paper MIGC and also includes a Paperspace demo to provide a hands on experiment with MIGC.
Introduction
Stable diffusion has been well known for text to image generation. Further, it has shown remarkable capabilities across various domains such as photography, painting, and others. However these researches mostly concentrates on Single-Instance Generation. However, practical scenarios requires simultaneous generation of multiple instances within a single image, with a control over quantity, position, attributes, and interactions, remain largely unexplored. This study dives deeper into the broader task of Multi-Instance Generation (MIG), aiming to tackle the complexities associated with generating diverse instances within a unified framework.
Motivated by the divide and conquer strategy, we propose the Multi-Instance Generation Controller (MIGC) approach. This approach aims to decompose MIG into multiple subtasks and then combines the results of those subtasks. - Original Research Paper
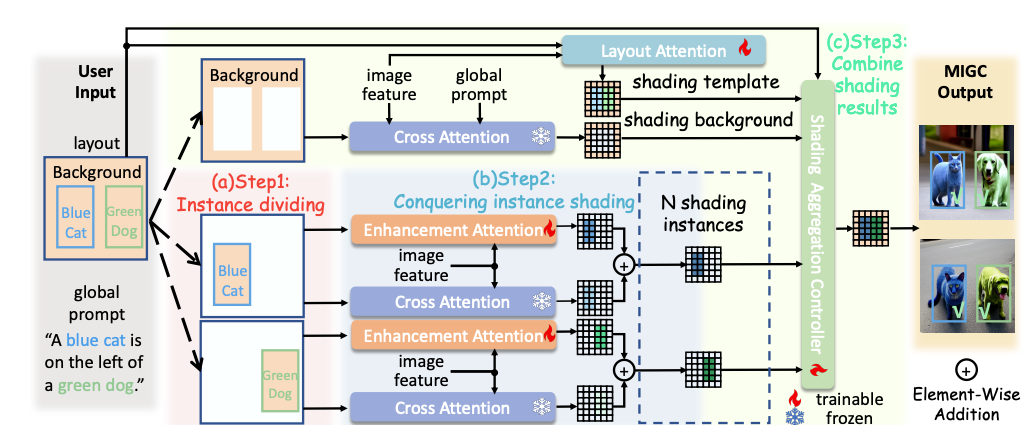
MIGC consists of three steps:
1) Divide: MIGC breaks down Multi-Instance Generation (MIG) into individual instance shading subtasks within the Cross-Attention layers of SD. This approach accelerates the resolution of each subtask, enhancing image harmony in the generated images.
2) Conquer: MIGC, uses a special layer called Enhancement Attention Layer to improve the shading outcomes from the fixed Cross-Attention. This ensures that each instance receives proper shading.
3) Combine: MIGC, gets the shading template using a Layout Attention layer. Then, they combine it with the shading background and shading instances, sending them to a Shading Aggregation Controller to get the final shading result.
A comprehensive experiment was conducted with COCO-MIG, COCO, and DrawBench. The COCO-MIG method significantly improved the Instance Success Rate from 32.39% to 58.43%. When applied to the COCO benchmark, this approach notably increased the Average Precision (AP) from 40.68/68.26/42.85 to 54.69/84.17/61.71. Similarly, on DrawBench, the observed improvements in position, attribute, and count, notably boosting the attribute success rate from 48.20% to 97.50%. Additionally, as mentioned on the research paper MIGC maintains a similar inference speed to the original stable diffusion.
Analysis and Results
In Multi-Instance Generation (MIG), users provide the generation models with a global prompt (P), bounding boxes for each instance (B), and descriptions for each instance (D). Based on these inputs, the model has to create an image (I) where each instance within its box should match its description, and all instances should align correctly within the image. Prior method such as stable diffusion struggled with attribute leakage which includes textual leakage and spatial leakage.

The above image compares the MIGC approach with other baseline methods on the COCO-MIG dataset. Specifically, a yellow bounding box marked "Obj" is used to denote instances where the position is inaccurately generated, and a blue bounding box labeled "Attr" to indicate instances where attributes are incorrectly generated.
The experimental findings from the research demonstrates that MIGC excels in attribute control, particularly regarding color, while maintaining precise control over the positioning of instances.
In assessing positions, Grounding-DINO was used to compare detected boxes with the ground truth, marking instances with IoU above 0.5 as "Position Correctly Generated." For attributes, if an instance is correctly positioned, Grounded-SAM was used to measure the percentage of the target color in the HSV space, labeling instances with a percentage above 0.2 as "Fully Correctly Generated."
On COCO-MIG, the main focus was on Instance Success Rate and mIoU, with IoU set to 0 if color is incorrect. For COCO-Position, Success Rate, mIoU, and Grounding-DINO AP score for Spatial Accuracy, alongside FID for Image Quality, CLIP score, and Local CLIP score for Image-Text Consistency was measured.
For DrawBench, Success Rate was assessed for position and count accuracy and check for correct color attribution. Manual evaluations complement automated metrics.
Paperspace Demo
Bring this project to life
Use the link provided with the article to start the notebook on Paperspace and follow the tutorial.
- Clone the repo, install and update the necessary libraries
!git clone https://github.com/limuloo/MIGC.git
%cd MIGC!pip install --upgrade --no-cache-dir gdown
!pip install transformers
!pip install torch
!pip install accelerate
!pip install pyngrok
!pip install opencv-python
!pip install einops
!pip install diffusers==0.21.1
!pip install omegaconf
!pip install -U transformers!pip install -e .- Import the necessary modules
import yaml
from diffusers import EulerDiscreteScheduler
from migc.migc_utils import seed_everything
from migc.migc_pipeline import StableDiffusionMIGCPipeline, MIGCProcessor, AttentionStore
import os
- Download the pre-trained weights and save them to your directory
!gdown --id 1v5ik-94qlfKuCx-Cv1EfEkxNBygtsz0T -O ./pretrained_weights/MIGC_SD14.ckpt
!gdown --id 1cmdif24erg3Pph3zIZaUoaSzqVEuEfYM -O ./migc_gui_weights/sd/cetusMix_Whalefall2.safetensors
!gdown --id 1Z_BFepTXMbe-cib7Lla5A224XXE1mBcS -O ./migc_gui_weights/clip/text_encoder/pytorch_model.bin- Create the function 'offlinePipelineSetupWithSafeTensor'
This function sets up a pipeline for offline processing, integrating MIGC and CLIP models for text and image processing.
def offlinePipelineSetupWithSafeTensor(sd_safetensors_path):
migc_ckpt_path = '/notebooks/MIGC/pretrained_weights/MIGC_SD14.ckpt'
clip_model_path = '/notebooks/MIGC/migc_gui_weights/clip/text_encoder'
clip_tokenizer_path = '/notebooks/MIGC/migc_gui_weights/clip/tokenizer'
original_config_file='/notebooks/MIGC/migc_gui_weights/v1-inference.yaml'
ctx = init_empty_weights if is_accelerate_available() else nullcontext
with ctx():
# text_encoder = CLIPTextModel(config)
text_encoder = CLIPTextModel.from_pretrained(clip_model_path)
tokenizer = CLIPTokenizer.from_pretrained(clip_tokenizer_path)
pipe = StableDiffusionMIGCPipeline.from_single_file(sd_safetensors_path,
original_config_file=original_config_file,
text_encoder=text_encoder,
tokenizer=tokenizer,
load_safety_checker=False)
print('Initializing pipeline')
pipe.attention_store = AttentionStore()
from migc.migc_utils import load_migc
load_migc(pipe.unet , pipe.attention_store,
migc_ckpt_path, attn_processor=MIGCProcessor)
pipe.scheduler = EulerDiscreteScheduler.from_config(pipe.scheduler.config)
return pipe- Call the function
offlinePipelineSetupWithSafeTensor()with the argument'./migc_gui_weights/sd/cetusMix_Whalefall2.safetensors'to set up the pipeline. Post setting up the pipeline, we will transfer the entire pipeline, to the CUDA device for GPU acceleration using the.to("cuda")method.
pipe = offlinePipelineSetupWithSafeTensor('./migc_gui_weights/sd/cetusMix_Whalefall2.safetensors')
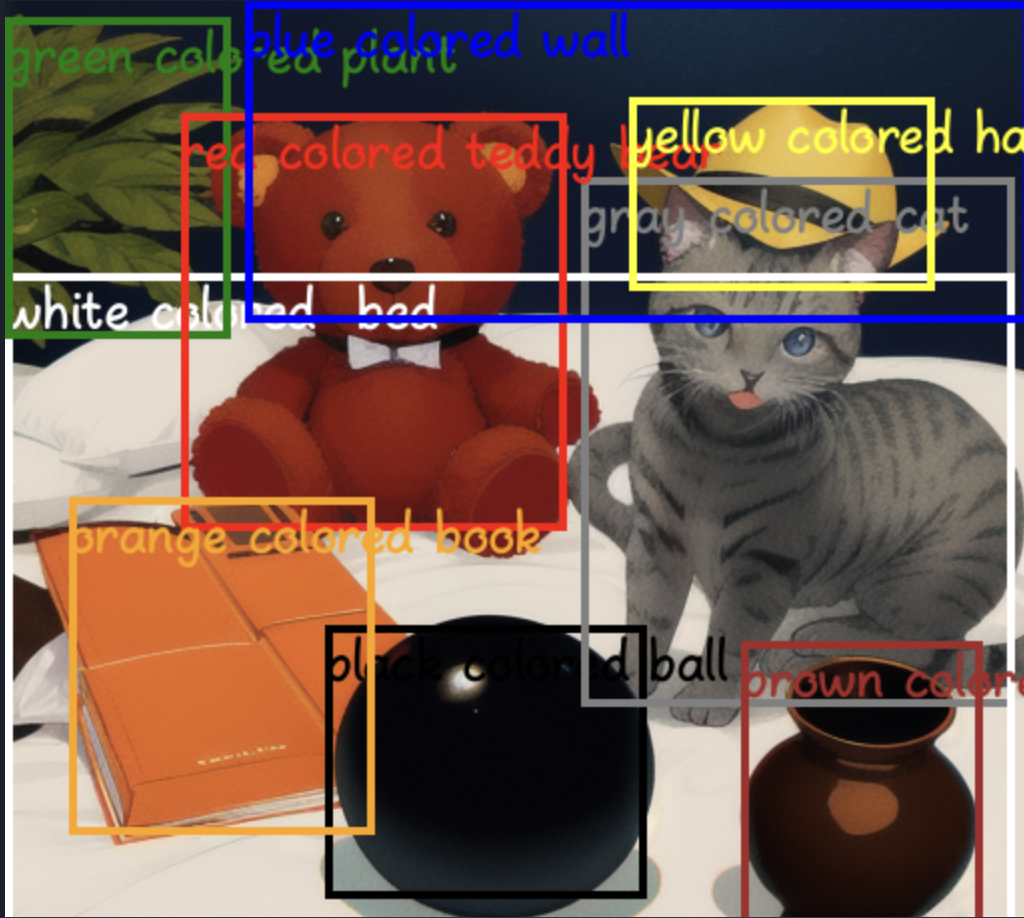
pipe = pipe.to("cuda")- We will use the created pipeline to generate an image. The created image is based on the provided prompts and the bounding boxes, the function annotates the generated image with bounding boxes and descriptions, and saves/display the results.
prompt_final = [['masterpiece, best quality,black colored ball,gray colored cat,white colored bed,\
green colored plant,red colored teddy bear,blue colored wall,brown colored vase,orange colored book,\
yellow colored hat', 'black colored ball', 'gray colored cat', 'white colored bed', 'green colored plant', \
'red colored teddy bear', 'blue colored wall', 'brown colored vase', 'orange colored book', 'yellow colored hat']]
bboxes = [[[0.3125, 0.609375, 0.625, 0.875], [0.5625, 0.171875, 0.984375, 0.6875], \
[0.0, 0.265625, 0.984375, 0.984375], [0.0, 0.015625, 0.21875, 0.328125], \
[0.171875, 0.109375, 0.546875, 0.515625], [0.234375, 0.0, 1.0, 0.3125], \
[0.71875, 0.625, 0.953125, 0.921875], [0.0625, 0.484375, 0.359375, 0.8125], \
[0.609375, 0.09375, 0.90625, 0.28125]]]
negative_prompt = 'worst quality, low quality, bad anatomy, watermark, text, blurry'
seed = 7351007268695528845
seed_everything(seed)
image = pipe(prompt_final, bboxes, num_inference_steps=30, guidance_scale=7.5,
MIGCsteps=15, aug_phase_with_and=False, negative_prompt=negative_prompt, NaiveFuserSteps=30).images[0]
image.save('output1.png')
image.show()
image = pipe.draw_box_desc(image, bboxes[0], prompt_final[0][1:])
image.save('anno_output1.png')
image.show()
We highly recommend our readers to click the link and access the complete notebook and further experiment with the codes.
Conclusion
This research aims to tackle a challenging task called "MIG" and introduce a solution called MIGC to enhance the performance of stable diffusion in handling MIG tasks. One of the novel idea utilizes the strategy of divide and conquer which breaks down complex MIG task into simpler tasks, focusing on shading individual objects. Each object's shading is further enhanced using an attention layer, and then combined with all the shaded objects using another attention layer and a controller. Several experiments are conducted using the proposed COCO-MIG dataset as well as widely used benchmarks like COCO-Position and Drawbench. We experimented with MIGC and the results show that MIGC is efficient and effective.
We hope you enjoyed reading the article as much as we enjoyed writing about it and experimenting with Paperspace Platform.










