
Introduction
Bring this project to life
Large-scale Text-to-Image (T2I) models, like Stable Diffusion, have gained rapid prominence in creative domains, producing visually captivating outputs based on textual prompts. Despite their success, ensuring a consistent style control remains a challenge, often requiring fine-tuning and manual intervention to separate content and style. The paper "StyleAligned Image Generation via Shared Attention" introduces StyelAligned, a novel technique aimed at establishing style alignment within a series of generated images. Through minimal 'attention sharing' during the diffusion process, the main approach maintains style consistency in T2I models. This enables the creation of style-consistent images using a reference style through a simple inversion operation. Evaluation across diverse styles and text prompts showcases the method's effectiveness, highlighting its ability to achieve consistent style across a range of inputs with high-quality synthesis and fidelity.

This approach eliminates the need for optimization and is applicable to any attention-based text-to-image diffusion model. The original research paper demonstrates that incorporating minimal attention sharing operations throughout the diffusion process, from each generated image to the initial one in a batch, results in a style-consistent set. Additionally, through diffusion inversion, this method can generate style-consistent images based on a reference style image, requiring no optimization or fine-tuning.
Key benefits of this approach
There have been several studies focused on text conditioned image generative models, and these studies have been successful in generating high quality image from the given prompt. In diffusion models, Hertz et al. demonstrated the influence of cross and self-attention maps on shaping the layout and content of the generated images during the diffusion process. Here we discuss few of the key benefits of this approach:
- This approach excels in producing images with various structures and content, which is quite different from all of the previous methods. To add more this approach preserves the consistent style interpretation.
- A very close approach to this study is StyleDrop, which can generate a consistent set of images without the optimization phase. Also, this approach does not rely on several images of training. To ensure this, the approach involves the creation of personalized encoders dedicated to injecting new priors directly into T2I models using a single input image. However, these methods face challenges in separating style from content, as their focus is on generating the same subject as presented in the input image. This issue is tackled in the style alignment approach.
- The qualitative comparison with StyleDrop (SDXL), StyleDrop (unofficial implementation of MUSE unofficial), and Dreambooth-LoRA (SDXL) was conducted in this research. It was found that the images generated with this method are far more consistent across the styles such as color palette, drawing style, composition, and pose.
- A user study was conducted using StyleAligned, StyleDrop, and DreamBooth. The user were shown 4 images from the above methods and it was found that the majority favored StyleAligned in terms of style consistency, and text alignment.
- StyleAligned addresses the challenges of achieving image generation within the realm of large scale T2I models. This is achieved using minimal attention sharing operations with AdaIN modulation during the diffusion process. This method has been capable of establishing style-consistency and visual coherence across generated images.
Now that we have discussed the capabilities of StyleAligned, let us walk through setting up the platform to run this model successfully and explore the capabilities using Paperspace GPUs.
StyleAligned demo on Paperspace
Running the demo on Paperspace is relatively simple. To start, click the link provided in this article, which will spin up the notebook on Paperspace. We are provided with five notebooks which include:
- style_aligned_sd1 notebook for generating StyleAligned images using sd.
- style_aligned_sdxl notebook for generating StyleAligned images using SDXL.
- style_aligned_transfer_sdxl notebook for generating images with a style from reference image using SDXL.
- style_aligned_w_controlnet notebook for generating StyleAligned and depth conditioned images using SDXL with ControlNet-Depth.
- style_aligned_w_multidiffusion can be used for generating StyleAligned panoramas using SD V2 with MultiDiffusion.
To add more we have provided a helper.ipynb notebook that facilitates the quick launch of the Gradio app in your browser.
Setup
Bring this project to life
With that done, we can get started with our first notebook style_aligned_sd1.ipynb. This notebook includes all the code that will allow you to generate the images.
- Run the first cell, this will start the installation process for the required libraries.
#Install the libraries using pip
!pip install -r requirements.txt
!pip install -U transformers diffusers
!pip install -y torch torchvision torchaudio
!pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
!python3 -m pip install torch==2.0.0+cu117 torchvision==0.15.1+cu117 torchaudio==2.0.1 --index-url https://download.pytorch.org/whl/cu117
This code cell will install everything needed to run StyleAligned in the notebook. Once all the packages are installed run all the cells provided in the notebook.
- StyleAligned using stable diffusion to generate images.
from diffusers import DDIMScheduler,StableDiffusionPipeline
import torch
import mediapy
import sa_handler
import math
scheduler = DDIMScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", clip_sample=False,
set_alpha_to_one=False)
pipeline = StableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
scheduler=scheduler
)
pipeline = pipeline.to("cuda")
handler = sa_handler.Handler(pipeline)
sa_args = sa_handler.StyleAlignedArgs(share_group_norm=True,
share_layer_norm=True,
share_attention=True,
adain_queries=True,
adain_keys=True,
adain_values=False,
)
handler.register(sa_args, )
# run StyleAligned
sets_of_prompts = [
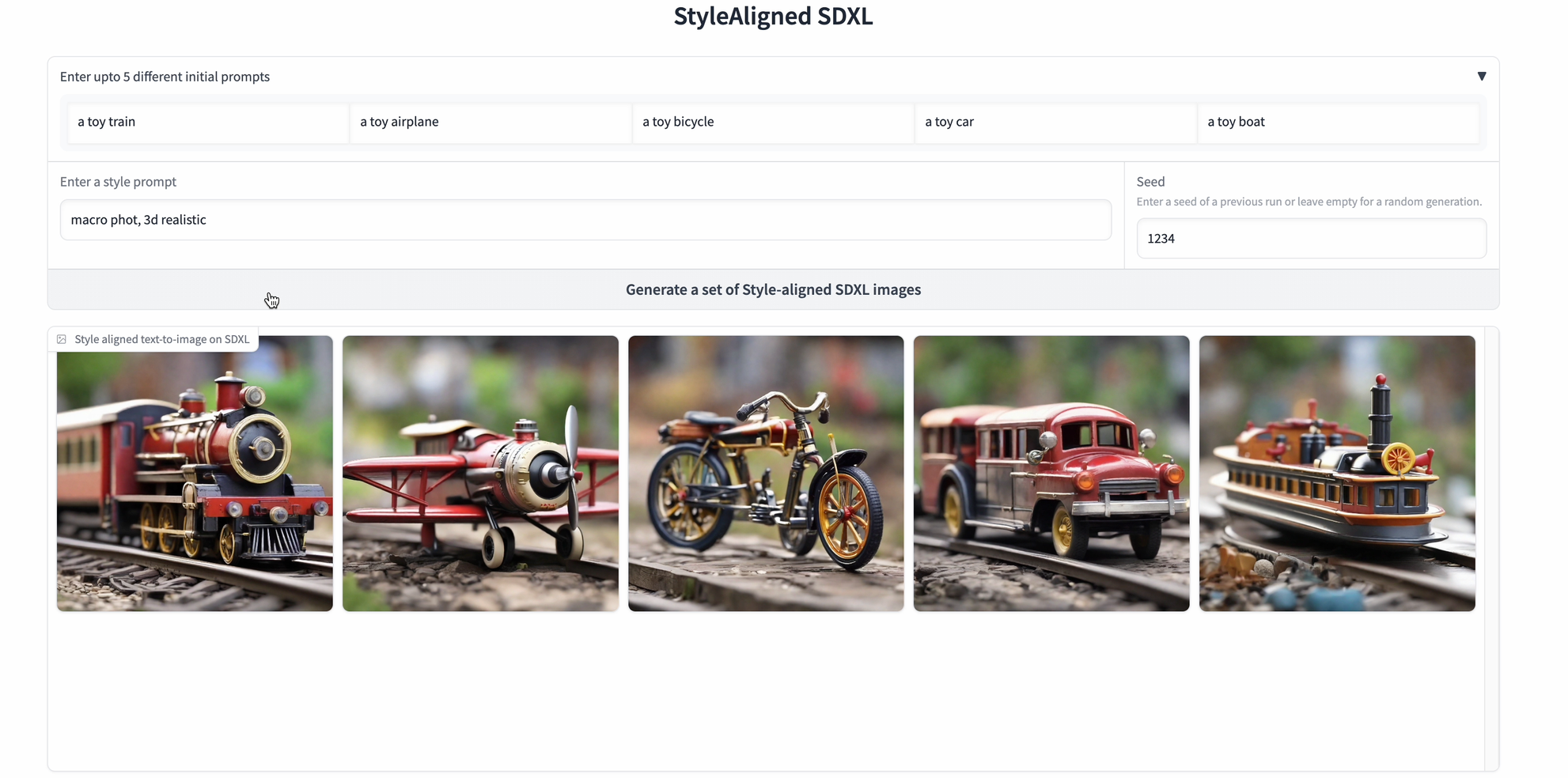
"a toy train. macro photo. 3d game asset",
"a toy airplane. macro photo. 3d game asset",
"a toy bicycle. macro photo. 3d game asset",
"a toy car. macro photo. 3d game asset",
"a toy boat. macro photo. 3d game asset",
]
images = pipeline(sets_of_prompts, generator=None).images
mediapy.show_images(images)This code will set up the diffusion model with a specific scheduler, configure a StyleAligned handler, register the handler by passing certain arguments, and then use the diffusion pipeline to generate images based on a set of prompts and display the results.

- ControlNet depth with StyleAligned over SDXL
from diffusers import ControlNetModel, StableDiffusionXLControlNetPipeline, AutoencoderKL
from diffusers.utils import load_image
from transformers import DPTImageProcessor, DPTForDepthEstimation
import torch
import mediapy
import sa_handler
import pipeline_calls
# init models
#This code sets up a depth estimation model, a control net model, a #variational autoencoder (VAE), and a diffusion pipeline with StyleAligned #configuration.
depth_estimator = DPTForDepthEstimation.from_pretrained("Intel/dpt-hybrid-midas").to("cuda")
feature_processor = DPTImageProcessor.from_pretrained("Intel/dpt-hybrid-midas")
controlnet = ControlNetModel.from_pretrained(
"diffusers/controlnet-depth-sdxl-1.0",
variant="fp16",
use_safetensors=True,
torch_dtype=torch.float16,
).to("cuda")
vae = AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16).to("cuda")
pipeline = StableDiffusionXLControlNetPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
controlnet=controlnet,
vae=vae,
variant="fp16",
use_safetensors=True,
torch_dtype=torch.float16,
).to("cuda")
pipeline.enable_model_cpu_offload()
sa_args = sa_handler.StyleAlignedArgs(share_group_norm=False,
share_layer_norm=False,
share_attention=True,
adain_queries=True,
adain_keys=True,
adain_values=False,
)
handler = sa_handler.Handler(pipeline)
handler.register(sa_args, )Let us break down the code for a better understanding:
depth_estimator: An instance of a depth estimation model is (DPTForDepthEstimation) loaded from a pre-trained model ("Intel/dpt-hybrid-midas"), and moved to the CUDA device.feature_processor: An instance of an image processor (DPTImageProcessor) loaded from a pre-trained model ("Intel/dpt-hybrid-midas").controlnet: An instance of a control net model (ControlNetModel) loaded from a pre-trained model ("diffusers/controlnet-depth-sdxl-1.0"). It uses mixed-precision ("fp16") and is configured to use safe tensors.vae: An instance of an autoencoder with KL divergence (AutoencoderKL) loaded from a pre-trained model ("madebyollin/sdxl-vae-fp16-fix").- Next, the diffusion pipeline is (
StableDiffusionXLControlNetPipeline) loaded from a pre-trained model ("stabilityai/stable-diffusion-xl-base-1.0"). - StyleAligned Handler Setup:
sa_args: Configuration arguments for the StyleAligned approach, specifying options such as attention sharing and AdaIN settings.
handler: An instance of a StyleAligned handler (sa_handler.Handler) created with the configured diffusion pipeline. The handler is then registered with the specified StyleAligned arguments.
The code sets up the pipeline for image processing, depth estimation, control net modeling, and diffusion-based image generation with StyleAligned configuration. The models used here are pre-trained models and the entire pipeline is configured for efficient computation on a CUDA device with mixed-precision support.
Once this code runs successfully move to the next line of code. These lines of code load two images from the example folder. The images are processed through the depth estimator pipeline, and then the resulting depth maps using the mediapy library are displayed. It provides a visual representation of the depth information inferred from the input images.
image = load_image("./example_image/train.png")
depth_image1 = pipeline_calls.get_depth_map(image, feature_processor, depth_estimator)
depth_image2 = load_image("./example_image/sun.png").resize((1024, 1024))
mediapy.show_images([depth_image1, depth_image2])
# run ControlNet depth with StyleAligned
reference_prompt = "a poster in flat design style"
target_prompts = ["a train in flat design style", "the sun in flat design style"]
controlnet_conditioning_scale = 0.8
num_images_per_prompt = 3 # adjust according to VRAM size
latents = torch.randn(1 + num_images_per_prompt, 4, 128, 128).to(pipeline.unet.dtype)
for deph_map, target_prompt in zip((depth_image1, depth_image2), target_prompts):
latents[1:] = torch.randn(num_images_per_prompt, 4, 128, 128).to(pipeline.unet.dtype)
images = pipeline_calls.controlnet_call(pipeline, [reference_prompt, target_prompt],
image=deph_map,
num_inference_steps=50,
controlnet_conditioning_scale=controlnet_conditioning_scale,
num_images_per_prompt=num_images_per_prompt,
latents=latents)
mediapy.show_images([images[0], deph_map] + images[1:], titles=["reference", "depth"] + [f'result {i}' for i in range(1, len(images))])This code block generates images using the ControlNet model conditioned on a reference prompt, target prompts, and depth maps. The results are then visualized using the mediapy library.

We highly recommend users experiment with the notebooks provided to better understand the model and synthesize images.
Launching the Gradio Application
We have included a helper.ipynb notebook which will launch the gradio application on your browser.
- Start by installing the necessary packages
!pip install gradio
!pip install -r requirements.txt
!pip install -U transformers diffusers
!pip install -y torch torchvision torchaudio
!pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121- Launch the gradio application
!sed 's/.launch()/.launch(share=True)/' -i /notebooks/demo_stylealigned_sdxl.py
!python demo_stylealigned_sdxl.py 
The first thing we can do is to try out some prompts to test the image generations using the StyleAligned SDXL model.
- Experiments with different models
Please feel free to modify the code below to experiment with and run various models.
!sed 's/.launch()/.launch(share=True)/' -i /notebooks/demo_desired_model_name.py
!python demo_desired_model_name.py
Closing Thoughts
In this article, we have walked through StyleAligned model for image generation. The demo showcases the effectiveness of StyleAligned for generating high-quality, style-consistent images across a range of styles and textual prompts. This model may find potential application in creative fields such as content creation and designs, e-commerce advertising, gaming, education, and more. Our findings confirm StyelAligned's ability to interpret provided descriptions and reference styles while maintaining impressive synthesis quality. We recommend StyleAligned to users who want to explore text to image models in detail and are also experienced in working with stable diffusion models.
Thanks for reading, and be sure to check out our other articles on Paperspace blogs related to image generation!










