
Bring this project to life
Generating images with Deep Learning is arguably one of the greatest and most versatile applications of this generation of generative, weak AI. From generating quick marketing content to augmenting artist workflows to creating a fun learning tool for AI, we can easily see this ubiquity in action with the widespread popularity of the Stable Diffusion family of models. This is in large part to the Stability AI and Runway ML teams efforts to keep the model releases open sourced, and also owes a huge thanks to the active community of developers creating tools with these models. Together, these traits have made the model incredibly accessible and easy to run - even for people with no coding experience!
Since their release, these Latent Diffusion Model based text-to-image models have proven incredibly capable. Up until now, the only real competition from the open source community was with other Stable Diffusion releases. Notably, there is now an enormous library of fine-tuned model checkpoints available on sites like HuggingFace and CivitAI.
In this article, we are going to cover our favorite open source, text-to-image generative model to be released since Stable Diffusion: PixArt Alpha. This awesome new model boasts an exceptionally low training cost, a innovative training strategy that abstracts critical elements from a typically blended methodology, highly informative training data, and implement a novel T2I Efficient transformer. In this article, we are going to discuss these traits in more detail in order to show what makes this model so promising, before diving into our a modified version of the original Gradio demo running on a Paperspace Notebook.
Click the Run on Paperspace at the top of this notebook or below the "Demo" section to run the app on a Free GPU powered Notebook.
PixArt Alpha: Project Breakdown
In this section, we will take a deeper look at the model's architecture, training methodology, and the results of the project in comparison to other T2I models in terms of training cost and efficacy. Let's begin with a breakdown of the novel model architecture.
Model architecture
The model architecture is familiar to other T2I models, as it is based on the Diffusion Transformer model, but has some important tweaks that offer noticeable improvements. As recorded in the appendix of the paper, "We adopt the DiT-XL model, which has 28 Transformer blocks in total for better performance, and the patch size of the PatchEmbed layer in ViT (Dosovitskiy et al., 2020b) is 2×" (Source). With that in mind, we can build a rough idea of the structure of the model, but that doesn't expose all the notable changes they made.
Let's walk through the process each text-image pair makes through a Transformer block during training, so we can have a better idea of what other changes they made to DiT-XL to garner such substantial reductions in cost.
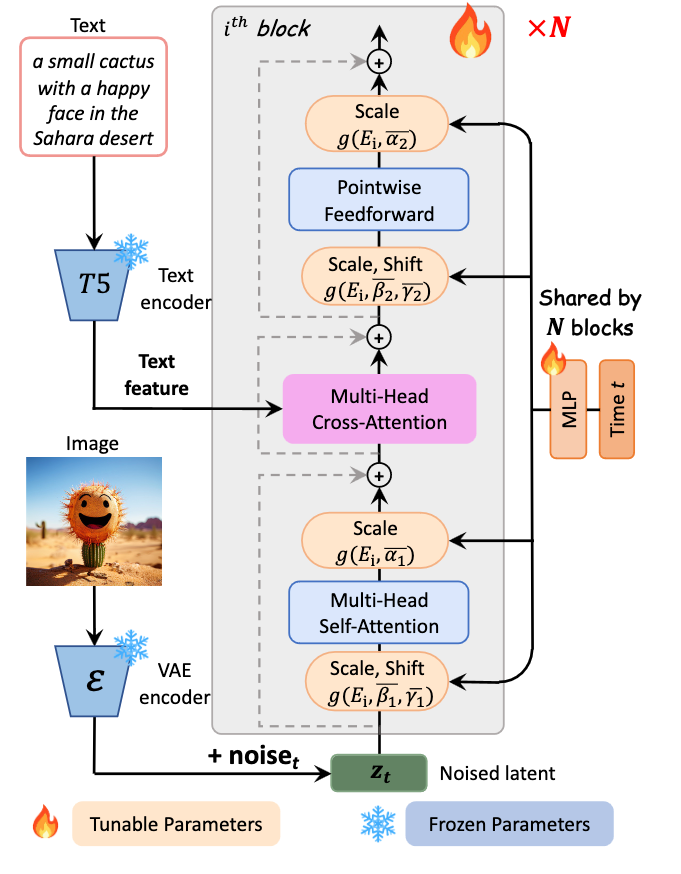
First, we start with our text and our image being entered into a T5 text encoder and Variational AutoEncoder (VAE) encoder modal, respectively. These encoders have frozen parameters, this prevents certain parts of the model from being adjusted during training. We do this to preserve the original traits of these encoders throughout the training process. Here our process splits.
The image data is diffused with noise to create a noised latent representation. There it is scaled and shifted using AdaLN-single layers, which are connected to and can adjust parameters across N different Transformer blocks. This scale and shift value is determined by a block-specific Multi Layer Perceptron (MLP), shown on the right of the figure. It then passes through a self-attention layer and an additional AdaLN-single scaling layer. There it is passed to the Multi-Head Cross Attention layer.
In the other path, the text feature is entered directly to the Multi-Head Cross Attention layer, which is positioned between the self-attention layer and feed forward layer of each Transformer block. Effectively, this allows the model to interact with the text embedding in a flexible manner. The output project layer is initialized at zero to act as an identity mapping and preserve the input for the following layers. In practice, this allows each block to inject textual conditions. (Source)
The Multi-Head Cross Attention Layer has the ability to mix two different embedding sequences, so long as they share the same dimension. (Source). From there, the now unified embedding are passed to an additional Scale + Shift layer with the MLP. Next, the Pointwise Feedforward layer helps the model capture complex relationships in the data by applying a non-linear transformation independently to each position. It introduces flexibility to model complex patterns and dependencies within the sequence. Finally, the embedding is passed to a final Scale layer, and on to the block output.
This intricate process allows these layers to adjust to the inputted features of the text-image pairs over the time of training, and, much like with other diffusion models, the process can be functionally reversed for the purpose of inference.
Now that we have looked at the process a datum takes in training, let's take a look at the training process itself in greater detail.
Training PixArt Alpha
The training paradigm for the project has immense importance because of the impact it has on the cost to train and final performance of the model. The authors specifically identified their novel strategy as being critical for the overall success of the model. They describe this strategy as involving decomposing the task of training the model into three distinct subtasks.
First, they trained the model to focus on learning the pixel distribution of natural images. They trained a class-conditional image generational model for natural images with a suitable initialization. This creates a boosted ImageNet model pre-trained on relevant image data, and PixArt Alpha is designed to be compatible with these weights
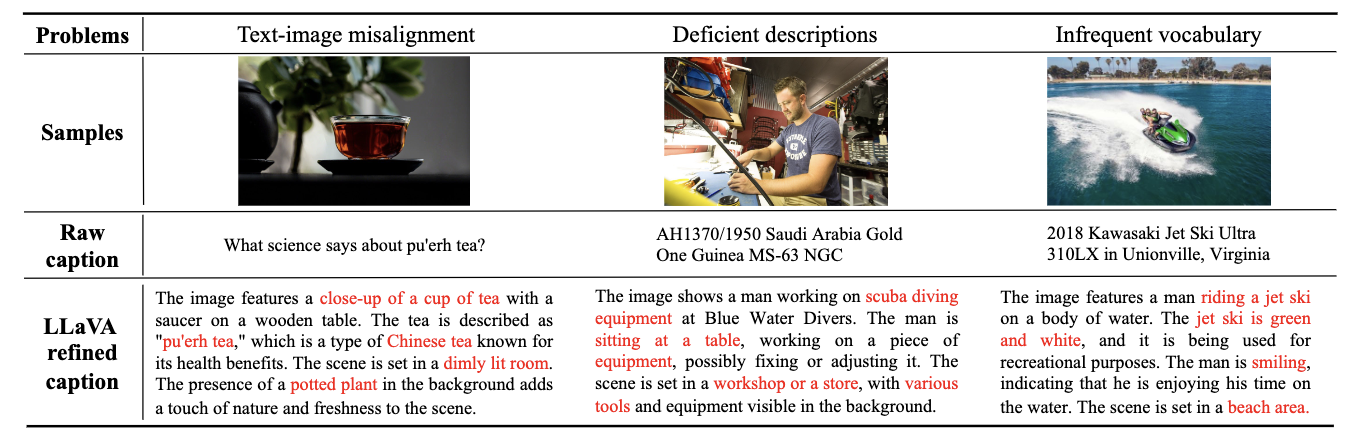
In the second stage, the model is tasked with learning to align the text-image object pairs. In order to achieve an accurate alignment between text concepts and images, they constructed a dataset consisting of text-image pairs using LLaVA to caption samples from the SAM dataset. LLaVA-labeled captions were significantly more robust when it comes to having sufficient valid nouns and concept density for finetuning when compared to LLaVA (for more details, please visit the Dataset construction section of the paper)

Finally, they used the third stage to raise aesthetic quality. In the third training stage, they used augmented "Internal" data from JourneyDB with high "aesthetic" quality. By fine-tuning the model on these, they are able to enhance the final output for aesthetic quality and detail. This internal data they created is reported to be of even higher quality than that created by SAM-LLaVA, in terms of Valid Nouns over Total Distinct Nouns.
Combined, this decoupled pipeline is extremely effective at reducing the training cost and time for the model. Training for the combined quality of these three traits has proven difficult, but by decomposing these processes and using different data sources for each stage, the project authors are able to achieve a high degree of training quality at a fraction of the cost.
Cost and efficacy benefits of PixArt Alpha against competition

Now that we have looked a bit deeper at the model architecture and training methodology & reasoning, let's discuss the final outcomes of the PixArt Alpha project. It's imperative when discussing this model to discuss its incredibly low, comparative cost of training to other T2I models.
The authors of the project have provided these three useful figures for our comparison. Let's identify a few key metrics from these graphics:
- PixArt Alpha trains in 10.8% of the time as Stable Diffusion v1.5 at a higher resolution (512 vs 1024).
- Trains in less than 2% of training time of RAPHAEL, one of the latest closed source releases for the model
- Uses .2% of data used to train Imagen, currently #3 on Paperswithcode.com's recording of top text-to-image models tested on COCO
All together, these metrics indicate that PixArt was incredibly affordable to train compared to competition, but how does it perform in comparison?
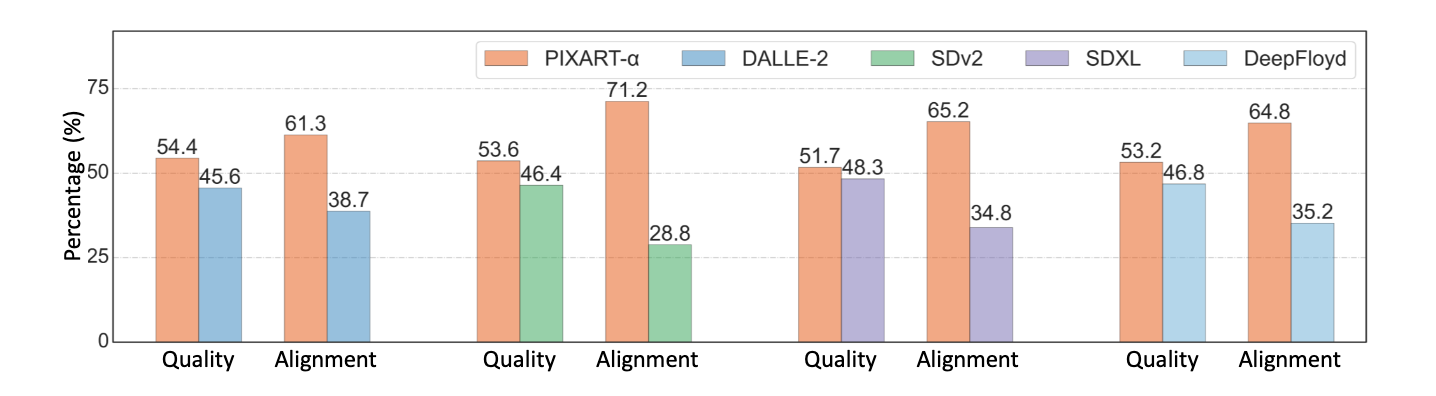
As we can see from the figure above, PixArt Alpha regularly outperforms competitive open source models in terms of both image fidelity and text-image alignment. While cannot compare it to closed source models like Imagen or RAPHAEL, it stands to reason that their performance would be comparable, albeit slightly inferior, given what we know about those models.
Demo
Bring this project to life
Now that we have gotten the model breakdown out of the way, we are ready to jump right into the code demo. For this demonstration, we have provided a sample Notebook in Paperspace that will make it easy to launch the PixArt Alpha project on any Paperspace machine. We recommend more powerful machines like the A100 or A6000 to get faster results, but the P4000 will generate images of equivalent quality.
To get started, click the Run on Paperspace link above or at the top of the article.
Setup
To setup the application environment once our Notebook is spun up, all we need to do is run the first code cell in the demo Notebook.
!pip install -r requirements.txt
!pip install -U transformers accelerateThis will install all of the needed packages for us, and then update the transformers and accelerate packages. This will ensure the application runs smoothly when we proceed to the next cell and run our application.
Running the modified app
To run the application from here, simply scroll the second code cell and execute it.
!python app.pyThis will launch our Gradio application, which has been modified slightly from the demo for PixArt Alpha readers may have seen on their Github or HuggingFace page. Let's take a look at what it can do, discuss the improvements we have added, and then take a look at some generated samples!
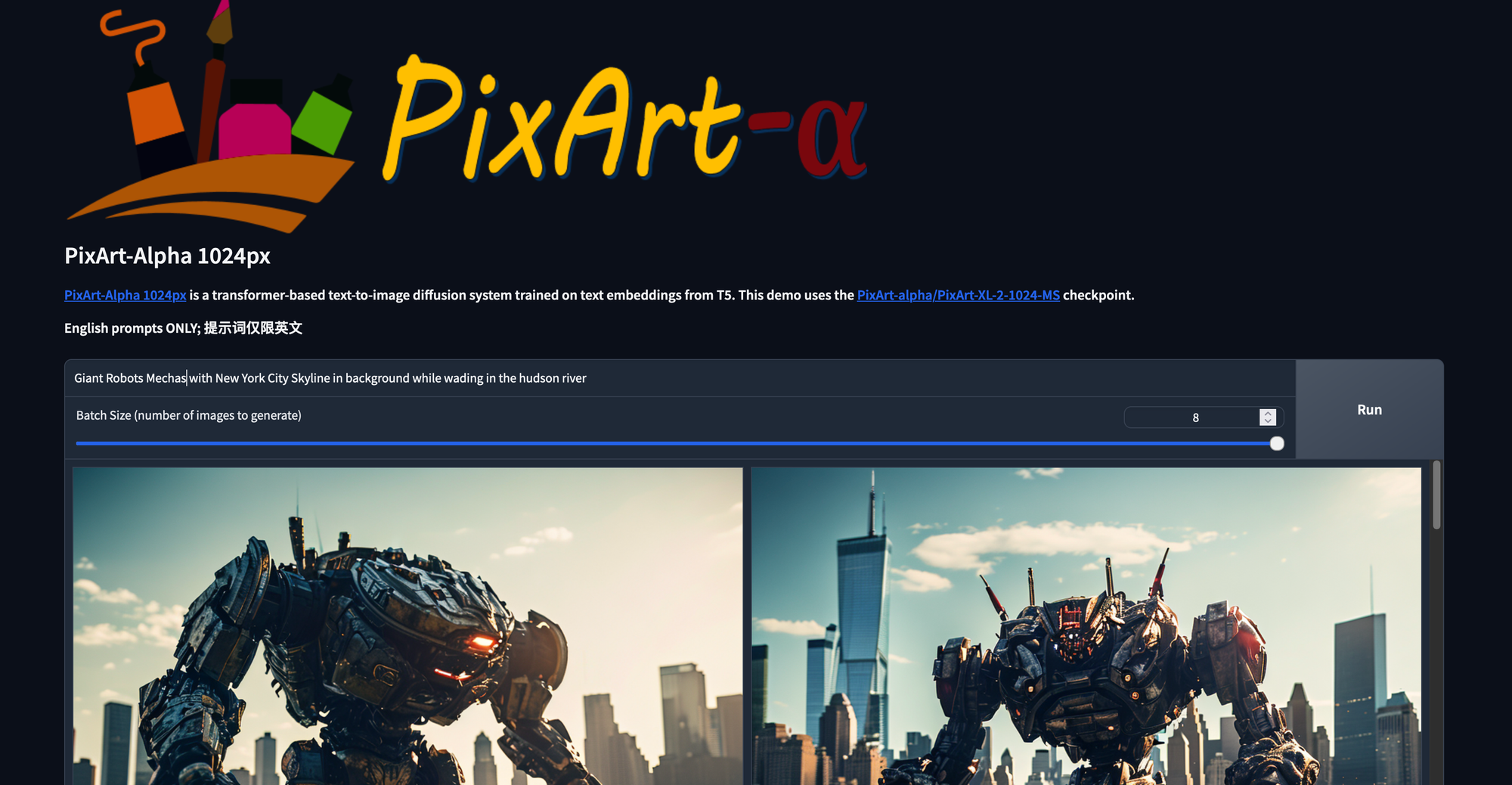
Here is the main page for the web GUI. From here, we can simply type in whatever prompt we desire and adjust the slider to match the desired number of outputs. Note that this solution won't generate multiple images per run of the model, as the current Transformers pipeline seems to only generated unconditional outputs with more than one image generated per run. Nonetheless, we will update the slider to have batch size and looping parameters when the pipeline itself can deal with it. For now, this is the easiest way to view multiple images generated with the same parameters at once.
We have also adjusted the gallery modal within to display all the outputs from a current run. These are then moved to a new folder after the run is complete.
In the section below our output, we can find a dropdown for advanced settings. Here we can do things like:
- Manually set the seed or set it to be randomized
- Toggle on or off the negative prompt, which will act like the opposite of our input prompt
- Enter the negative prompt
- Enter a image style. Styles will affect the final output, and include no style, cinematic, photographic, anime, manga, digital art, pixel art, fantasy art, neonpunk, and 3d model styles.
- Adjust the guidance scale. Unlike stable diffusion, this value needs to be fairly low (recommended 4.5) to avoid any artifacting
- Adjust number of diffusion inference steps
Let's take a look at some fun examples we made.



While the model still clearly has some work to be done, these results show immense promise for an initial release.
Closing thoughts
As shown in the article today, PixArt Alpha represents the first tangible, open source competition to Stable Diffusion to hit the market. We are eager t see how this project continues to develop going forward, and will be returning this topic shortly to teach our readers how to fine-tune PixArt alpha with Dreambooth!










