
The subdomain of Question Answering in NLP is popular because of the wide range of applications in answering questions with a reference document. The solution to this problem is tackled by using a dataset that consists of an input text, a query, and the segment of text or span from the input text which contains the answer to the query. With the help of deep learning models, there has been a significant improvement in achieving human-level predictions from the data.
In this tutorial, we'll cover:
- The Transformer Architecture
- Popular Datasets and Evaluation Metrics
- BERT (Bidirectional Encoder Representations from Transformers)
- ALBERT: A Lite BERT
- ELECTRA
- BART
- Issues with Long Document Question-Answering Using Standard Models
- LONGFORMER: the Long-Document Transformer
You can run the full code for this tutorial on a free GPU from the ML Showcase.
Bring this project to life
The Transformer Architecture
The transformer architecture was proposed in the paper Attention is All You Need. The encoders encode the input text, and the decoder processes the encodings to understand the contextual information behind the sequence. Each encoder and decoder in the stack uses an attention mechanism to process each input along with every other input for weighing their relevance, and generates the output sequence with the help of the decoder. The attention mechanism here enables dynamic highlighting and understanding the features in the input text. The self-attention mechanism in transformers can be illustrated with an example sentence.
A dog came running at me. It had cute eyes.
Here the self-attention mechanism allows the word It to be associated with the word dog, and understands that It does not refer to the word me. This is enabled because the other inputs in the sequence are weighed, and a higher probability of relevance is assigned for these two words.
Popular Datasets and Evaluation Metrics
In this article, we will be following the most common models and datasets for question answering, which are pre-trained with the help of the transformer architecture. The most popular question answering datasets involve SQuAD, CoQA, etc. These datasets are well maintained and regularly updated, thus making them suitable to be trained on by state-of-the-art models. The datasets consist of an input question, a reference text, and the targets.
Evaluation is done with the help of F1 and EM scores. These are calculated using the precision and recall. Precision is the number of True Positives divided by the number of True Positives and False Positives. The recall is the number of True Positives divided by the number of True Positives and False Negatives. The F1 score is:
2*((precision*recall)/(precision+recall))The EM (Exact Match) score measures the percentage of predictions that match any one of the ground truth answers exactly. The ground truth here is the target label in the dataset.
BERT (Bidirectional Encoder Representations from Transformers)
The huggingface transformers library provides nicely wrapped implementations for us to experiment with. Let's begin our experiments by first diving into a BERT model for understanding its performance.
Google Research's BERT is based on the transformer architecture, with an encoder-decoder stack trained on Wikipedia and the Book Corpus, a dataset containing 10,000+ books of different genres.
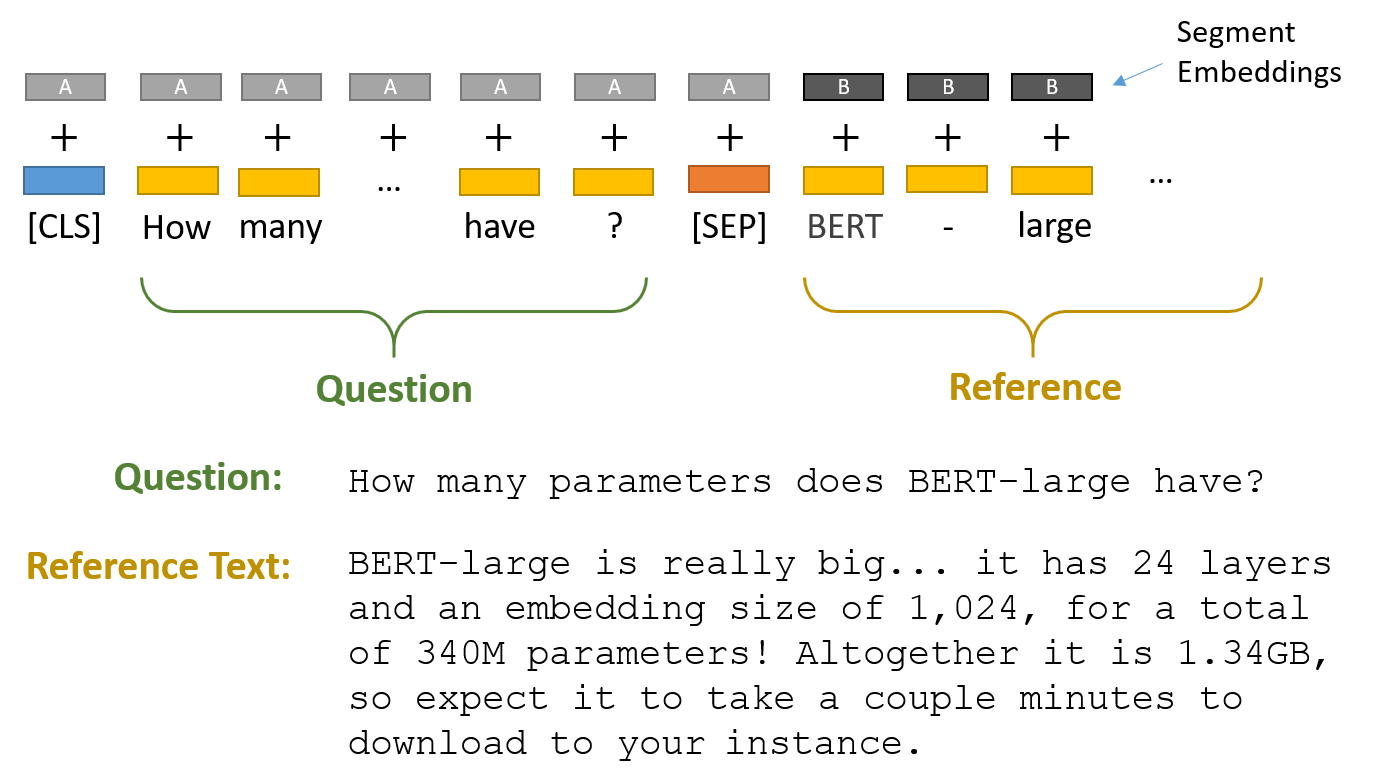
The SQuAD dataset contains only around 150,000 questions. We'll fine-tune a pre-trained model on these, as transfer learning is shown to improve performance given limited data. While BERT is trained on SQuAD, the input question and reference text are separated using a [sep] token. A probability distribution is used for determining the start and end tokens from the reference text, where the span containing the answer is determined by the position of the start and end tokens.
!pip install torch
!pip install transformers
!pip install sentencepiece
from transformers import BertTokenizer,AlbertTokenizer,AutoTokenizer, AutoModelForQuestionAnswering ,BertForQuestionAnswering
import torch
model_name='bert-large-uncased-whole-word-masking-finetuned-squad'
model = BertForQuestionAnswering.from_pretrained(model_name)
Here we have loaded the standard bert-large-uncased-whole-word-masking-finetuned-squad, which is around 1.34 GB in size. Next, we will see how the tokenizer for the same tokenizes our inputs.
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained(model_name)
question = "How heavy is Ever Given?"
answer_text = "The Ever Given is 400m-long (1,312ft) and weighs 200,000 tonnes, with a maximum capacity of 20,000 containers. It is currently carrying 18,300 containers."
input_ids = tokenizer.encode(question, answer_text)
tokens = tokenizer.convert_ids_to_tokens(input_ids)
print(tokens)Output:
['[CLS]', 'how', 'heavy', 'is', 'ever', 'given', '?', '[SEP]', 'the', 'ever', 'given', 'is', '400', '##m', '-', 'long', '(', '1', ',', '312', '##ft', ')', 'and', 'weighs', '200', ',', '000', 'tonnes', ',', 'with', 'a', 'maximum', 'capacity', 'of', '20', ',', '000', 'containers', '.', 'it', 'is', 'currently', 'carrying', '18', ',', '300', 'containers', '.', '[SEP]']The question and answer texts are separated by a [sep] token, and "##" means that the rest of the token should be attached to the previous one, without a space (for decoding or reversal of the tokenization). The usage of "##" ensures that the token with this symbol is directly related to the token just before it.
Next, I am going to wrap our implementation of question-answering in a function, so that we can reuse it for trying out different models in this example with only minor code changes.
def qa(question,answer_text,model,tokenizer):
inputs = tokenizer.encode_plus(question, answer_text, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"].tolist()[0]
text_tokens = tokenizer.convert_ids_to_tokens(input_ids)
print(text_tokens)
outputs = model(**inputs)
answer_start_scores=outputs.start_logits
answer_end_scores=outputs.end_logits
answer_start = torch.argmax(
answer_start_scores
) # Get the most likely beginning of answer with the argmax of the score
answer_end = torch.argmax(answer_end_scores) + 1 # Get the most likely end of answer with the argmax of the score
answer = tokenizer.convert_tokens_to_string(tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end]))
# Combine the tokens in the answer and print it out.""
answer = answer.replace("#","")
print('Answer: "' + answer + '"')
return answer
`qa(question,answer_text,model,tokenizer)`
Output:
Answer: "200 , 000 tonnes"The F1 and EM scores for BERT on SQuAD 1.1 is around 91.0 and 84.3, respectively.
ALBERT: A Lite BERT
For tasks that require lower memory consumption and faster training speeds, we can use ALBERT. It's a lite version of BERT which uses parameter reduction techniques, and thus redues the number of parameters while running training and inference. This helps in the scalability of the model as well.
tokenizer=AlbertTokenizer.from_pretrained('ahotrod/albert_xxlargev1_squad2_512')
model=AlbertForQuestionAnswering.from_pretrained('ahotrod/albert_xxlargev1_squad2_512')
qa(question,answer_text,model,tokenizer)
Output:
Answer: "200,000 tonnes"The input embeddings in ALBERT consist of an embedding matrix in a relatively low dimension (e.g. $128$), and hidden layer dimensions are higher ($768$ as in the BERT case, or more). With reduced matrix size, the projected parameters also reduced, i.e. an 80% reduction can be observed in the parameters. This also comes with the cost of a very minor drop in performance; an 80.3 SQuAD 2.0 score, down from 80.4.
ELECTRA
ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately) is another model which provides a pre-trained approach, where it corrupts the MLM (Masked Language Modeling) by a novel approach; called replaced token detection (RTD). The approach trains two transformer models: a generator and discriminator, which both try to outplay each other. The generator tries to fool the discriminator by replacing the tokens in a sequence, while the discriminator's job is to find the tokens replaced by the generator. Since the task is defined over all tokens rather than the masked part, this approach is more efficient and outperforms BERT in terms of feature extraction.
tokenizer = AutoTokenizer.from_pretrained("valhalla/electra-base-discriminator-finetuned_squadv1")
model = AutoModelForQuestionAnswering.from_pretrained("valhalla/electra-base-discriminator-finetuned_squadv1")
question="What is the discriminator of ELECTRA similar to?"
answer_text='As mentioned in the original paper: ELECTRA is a new method for self-supervised language representation learning. It can be used to pre-train transformer networks using relatively little compute. ELECTRA models are trained to distinguish "real" input tokens vs "fake" input tokens generated by another neural network, similar to the discriminator of a GAN. At small scale, ELECTRA achieves strong results even when trained on a single GPU. At large scale, ELECTRA achieves state-of-the-art results on the SQuAD 2.0 dataset.'
qa(question,answer_text,model,tokenizer)Output:
Answer: "a gan"As per the paper, ELECTRA-base achieves an EM of 84.5 and an F1-score of 90.8 on SQuAD 2.0. The pre-training is also faster compared to BERT, and requires fewer examples to gain the same level of performance.
BART
Facebook Research's BART combines the capabilities of bi-directional (like BERT) and auto-regressive (like GPT and GPT-2) models. An auto-regressive model predicts the future word from a set of words given a context. A noising is done for the input text, either by corrupting some tokens or another. An LM (Language Model) tries to replace the corrupted tokens with original ones by prediction.
tokenizer = AutoTokenizer.from_pretrained("valhalla/bart-large-finetuned-squadv1")
model = AutoModelForQuestionAnswering.from_pretrained("valhalla/bart-large-finetuned-squadv1")
question="Upto how many tokens of sequences can BART handle?"
answer_text="To use BART for question answering tasks, we feed the complete document into the encoder and decoder, and use the top hidden state of the decoder as a representation for each word. This representation is used to classify the token. As given in the paper bart-large achives comparable to ROBERTa on SQuAD. Another notable thing about BART is that it can handle sequences with upto 1024 tokens."
qa(question,answer_text,model,tokenizer)Output:
Answer: " 1024"By combining the best of both worlds, i.e. the features of bi-directional and auto-regressive models, BART provides better performance than BERT (albeit, with a 10% increase in the parameters). Here, BART-large achieves an EM of 88.8, and an F1-score of 94.6.
Issues with Long Document Question-Answering Using Standard Models
As discussed at the beginning of the article, the transformers model uses the help of the self-attention operation to provide meaningful results. As the length of the sequence increases, the computation scales drastically for this mechanism. For example, take a look at the question and text given below:
question="how many pilots did the ship have?"
answer_text="""
Tug boats had spent several hours on Monday working to free the bow of the massive vessel after dislodging the stern earlier in the day.
Marine traffic websites showed images of the ship away from the banks of the Suez Canal for the first time in seven days following an around-the-clock international effort to reopen the global shipping lane.
There are still 422 ships waiting to go through the Suez Canal, Rabie said, adding that the canal's authorities decided the ships will be able to cross the canal on a first come first serve basis, though the ships carrying livestock were permitted to cross in the first convoy of the day.
The average number of ships that transited through the canal on a daily basis before the accident was between 80 to 90 ships, according to Lloyds List; however, the head of the Suez Canal Authority said that the channel will work over 24 hours a day to facilitate the passage of almost 400 ships carrying billions of dollars in freight.
The journey to cross the canal takes 10 to 12 hours and in the event the channel operates for 24 hours, two convoys per day will be able to successfully pass through.
Still, shipping giant Maersk issued an advisory telling customers it could take "6 days or more" for the line to clear. The company said that was an estimate and subject to change as more vessels reach the blockage or are diverted.
The rescue operation had intensified in both urgency and global attention with each day that passed, as ships from around the world, carrying vital fuel and cargo, were blocked from entering the canal during the crisis, raising alarm over the impact on global supply chains.
What it's really like steering the world's biggest ships
What it's really like steering the world's biggest ships
Promising signs first emerged earlier on Monday when the rear of the vessel was freed from one of the canal's banks.
People at the canal cheered as news of Monday's progress came in.
The Panama Maritime Authority said that according to preliminary reports Ever Given suffered mechanical problems that affected its maneuverability.
The ship had two pilots on board during the transit.
However, the owner of the vessel, Japanese shipping company Shoe Kisen insists that there had been no blackout resulting in loss of power prior to the ship’s grounding.
Instead, gusting winds of 30 knots and poor visibility due to a dust storm have been identified as the likely causes of the grounding, which left the boxship stuck sideways in a narrow point of the waterway.
The incident has not resulted in any marine pollution ot injuries to the crew, only some structural damage to the ship, which is yet to be determined.
"""If we use the standard BERT model as we used earlier, an error will be observed, indicating that the long sequence of inputs cannot be processed.
from transformers import BertTokenizer,BertForQuestionAnswering
model_name='bert-large-uncased-whole-word-masking-finetuned-squad'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForQuestionAnswering.from_pretrained(model_name)
qa(question,answer_text,model,tokenizer)Output:
RuntimeError: The size of tensor a (548) must match the size of tensor b (512) at non-singleton dimension 1We need another model which has been pre-trained to include a longer sequence of input documents, and also an architecture that can process the same.
Longformer: the Long-Document Transformer
The problem of longer sequences can be solved (up to an extent) if we use Longformer instead of standard transformer-based models. The standard self-attention is dropped, and instead local-windowed attention with a task-motivated global attention is combined and used. The pre-trained model can handle sequences with up to 4096 tokens, as opposed to 512 in BERT. Longformer outperforms most other models in long document tasks and a significant reduction can be observed in terms of memory and time complexity.
For the above question-answer pair, let's see how longformer performs.
tokenizer = AutoTokenizer.from_pretrained("valhalla/longformer-base-4096-finetuned-squadv1")
model = AutoModelForQuestionAnswering.from_pretrained("valhalla/longformer-base-4096-finetuned-squadv1")
qa(question,answer_text,model,tokenizer)
Output:
Answer: " two"Converting a Model to Longformer
A standard transformer model can be converted into its "long" version. The steps include extending the position embeddings from $512$ to $4096$, and replacing the standard self-attention layers with the longformer attention layer. The code and explanation can be found here.
Conclusion
In this article, we went through various transformer-based models for question answering, and the datasets used to pre-train them. We also saw the varying baselines for each of the models in terms of F1 and EM scores. The improvements in architecture over the years has led to an increase in baseline performances. The performance of such models for long documents can still be improved if we convert them to a Longformer model.












{kind=link}