
In this article, we'll train a PyTorch model to perform super-resolution imaging, a technique for gracefully upscaling images. We'll use the Quilt data registry to snapshot training data and models as versioned data packages.

Super-resolution imaging (right) infers pixel values from a lower-resolution image (left).
The reproducibility crisis
Machine learning projects typically begin by acquiring data, cleaning the data, and converting the data into model-native formats. Such manual data pipelines are tedious to create and difficult to reproduce over time, across collaborators, and across machines. Moreover, trained models are often stored haphazardly, without version control. Taken collectively, the foregoing challenges have been dubbed the reproducibility crisis in machine learning.
It’s so bad it sometimes feels like stepping back in time to when we coded without source control.
—Pete Warden
As developers, we have an abundance of tools for versioning code. GitHub, Docker, and PyPI are three examples. We use these services to share and discover building blocks for applications. The building blocks are versioned and deployable, which makes them highly reproducible.
But what about reusable data? In this article we'll create reusable units of data that deploy like PyPI packages:
$ quilt install akarve/BSDS300
What about storing data on GitHub?
If you've ever tried to store data on GitHub, you may have discovered that large data are not welcome. GitHub limits files to 100MB, and limits repositories to 1GB. GitHub LFS eases these limits, but not by much.
By contrast, Quilt repositories can hold terabytes of data and thousands of files, as shown in this example at the Allen Cell Explorer. Packages stream directly from blob storage. Clients can therefore acquire data as fast as they can read from Amazon S3. Furthermore, Quilt serializes data to columnar formats, like Apache Parquet. Serialization accelerates I/O and accelerates network throughput.
Example: super-resolution imaging with PyTorch and Quilt
Version the training data
In this section, we'll package our test and training sets. If you're already familiar with data packages, or are eager to train the model, skip to the next section, Deploy data to any machine.
We're going train our super-resolution model on The Berkeley Segmentation Dataset and Benchmark[1], BSDS300. To get started, download the the data from Berkeley (22 MB). Unpack the contents into a clean directory and open the BSDS300 folder. You'll see the following:
$ ls
iids_test.txt iids_train.txt images
Optionally, add a README.md file, so that your data package is self-documenting:
# Berkeley Segmentation Dataset (BDS300)
See [BSDS on the web](https://www2.eecs.berkeley.edu/Research/Projects/CS/vision/bsds/).
# Citations
```
@InProceedings{MartinFTM01,
author = {D. Martin and C. Fowlkes and D. Tal and J. Malik},
title = {A Database of Human Segmented Natural Images and its
Application to Evaluating Segmentation Algorithms and
Measuring Ecological Statistics},
booktitle = {Proc. 8th Int'l Conf. Computer Vision},
year = {2001},
month = {July},
volume = {2},
pages = {416--423}
}
```
To convert the above files into a versioned data package, we'll need to install Quilt:
$ pip install quilt
Windows users, first install the Visual C++ Redistributable for Visual Studio 2015. To install Quilt from a Jupyter cell, see Appendix 1.
Next, build a data package from the contents of the current working directory:
$ quilt build YOUR_USERNAME/BSDS300 .
At this point, the package resides on your machine. If you wish to deploy the package to other machines, you'll need a free account on quiltdata.com.
$ quilt login
$ quilt push YOUR_USERNAME/BSDS300 --public
Now anyone in the world can reproduce precisely the same data:
quilt install akarve/BSDS300 -x e472cf0
The -x parameter specifies the SHA-256 digest of the package instance.
Just as PyPI hosts reusable software packages (like pandas, numpy, and torch), Quilt hosts reusable data packages.
Each package has a landing page, which displays documentation, revision history, and more. Below we see the package size (22.2 MB), file statistics (300 .jpg files), and package hash (e472cf0…).
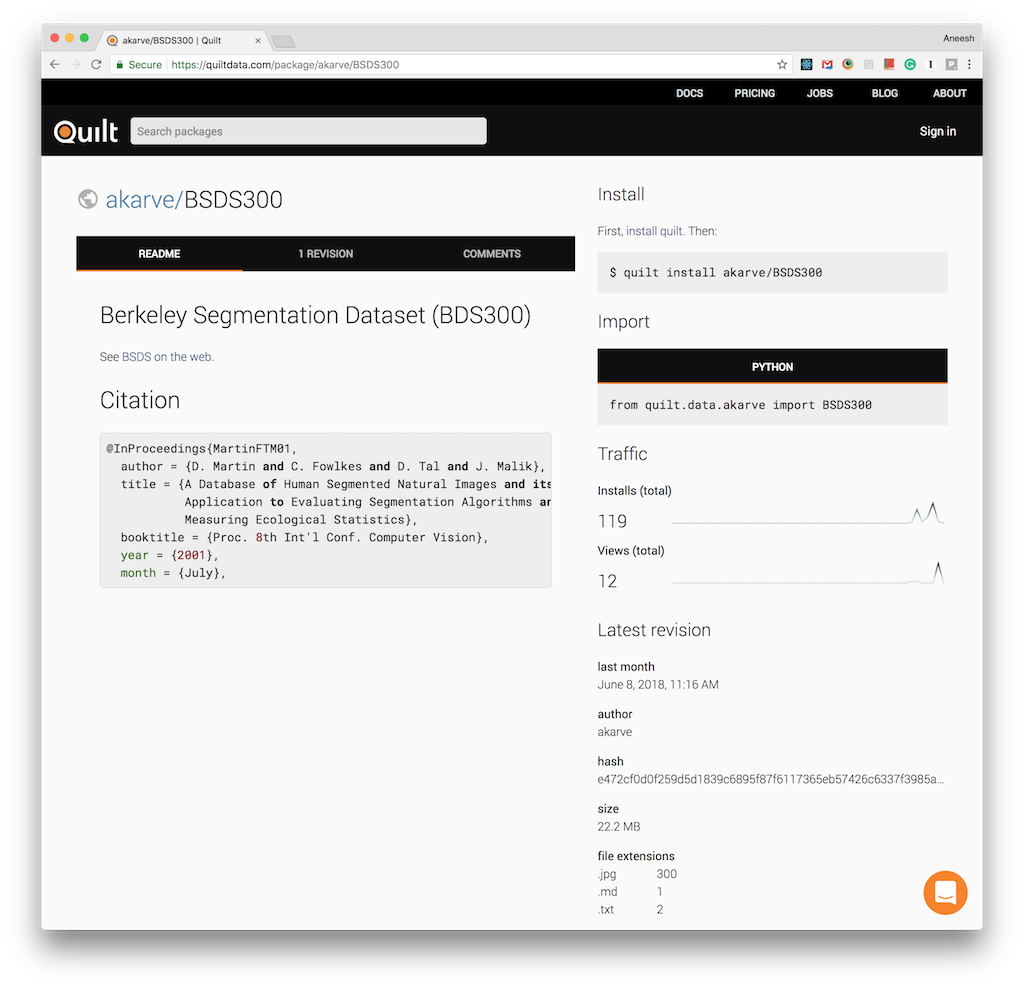
The Berkeley Segmentation Dataset on Quilt.
Deploy data to any machine
Install Quilt on the remote machine, followed by the BSDS300 package.
$ pip install quilt[img]
$ quilt install akarve/BSDS300
(To customize where data packages are stored, see Appendix 2.)
We're now ready to explore the BSDS300 in Python:
In [1]:
from quilt.data.akarve import BSDS300 as bsds
bsds.images
Out [1]:
<GroupNode>
test/
train/
Packages are browsable, like filesystems. bsds.images.test contains images:
In [2]: bsds.images.test
Out[2]:
<GroupNode>
n101085
n101087
n102061
n103070
n105025
…
We can use Quilt's asa= callback to to display bsds.images.test "as a plot".
%matplotlib inline
from quilt.asa.img import plot
bsds.images.test(asa=plot(figsize=(20,20)))

Under the hood, quilt.asa.img.plot() does something like the following for each image:
from matplotlib import image, pyplot
pyplot.imshow(
image.imread(
bsd['images']['test']['n101085']()
))
bsd['images']['test']['n101085']() represents the file bsd/images/test/101085.jpg. Quilt prepends n to the file name so that every package node is a valid Python identifier, accessible with Python's dot operator, or with brackets. The trailing parentheses () instruct Quilt to return the path to the underlying data fragment.
Train a PyTorch model from a Quilt package
Super-resolution imaging gracefully infers pixel values that are missing from the test instances. In order for a model to infer resolution, it requires a training corpus of high-resolution images (in our case, the BSDS300 training set).
So how do we get data from our package into PyTorch?
Quilt provides a higher-order function, asa.pytorch.dataset(), that converts packaged data into a torch.utils.data.Dataset object:
from quilt.data.akarve import BSDS300 as bsds
from quilt.asa.pytorch import dataset
return bsds.images.train(
asa=dataset(
include=is_image,
node_parser=node_parser,
input_transform=input_transform(...),
target_transform=target_transform(...)
))
For a full code sample, see this fork of pytorch-examples. The fork contains all of the code necessary to train and apply our super-resolution model. What's special about the fork? Less code.
With Quilt managing the data, dozens of lines of boilerplate code disappear. There's no longer a need for one-off functions that download, unpack, and load data.
Run the training job
The repository quiltdata/pytorch-examples contains an entrypoint script, train_super_resolution.sh, which calls main.py to install dependencies, train the model, and persist model checkpoints to disk:
#!/usr/bin/bash
export QUILT_PRIMARY_PACKAGE_DIR='/storage/quilt_packages'
cd super_resolution
pip install -r requirements.txt
mkdir -p /storage/models/super_resolution/
N_EPOCHS=$1
echo "Training for ${N_EPOCHS:=10} epochs\n"
# train
python main.py \
--upscale_factor 3 \
--batchSize 4 \
--testBatchSize 100 \
--nEpochs $N_EPOCHS \
--lr 0.001 \
--cuda
You can clone this Paperspace Job to train the model in your own account. Training completes in about 12 minutes on an NVIDIA P4000. If you wish to change where models are stored, see main.py.
Snapshot PyTorch models
In addition to data, you can store models, and their full revision history, in Quilt.
$ quilt build USR/PKG /storage/models/super_resolution/
$ quilt push USR/PKG
With the above-created package, anyone can rehydrate past training epochs.
Inference: super-size my resolution
Now that our model has been trained, we can rehydrate epoch 500 and super-resolve an image from the test set:
$ bash infer_super_resolution.sh 500 304034
Below are the results.

Inferred super-resolution (right) after 500 epochs of training.
An inference job is available here. In order for inference to work, be sure that your model checkpoints are saved in /storage/models/super_resolution (as shown in the training scripts above), or that you update the code to use a different directory. Furthermore, if you trained with --cuda, you'll need to call super_resolve.py --cuda.
Conclusion
We've used Quilt to package data, deploy data to a remote machine, and then train a PyTorch model.
We can think of reproducible machine learning as an equation in three variables:
code + data + model = reproducibility
By adding versioned data and versioned models to our workflow, we make it easier for developers to get consistent results over time, across machines, and across collaborators.
Acknowledgments
Thanks to the developers of the original super_resolution example, to the curators and creators of the BSDS300, to Dillon Erb and Adam Sah for reviewing drafts of this article, and to Paperspace for providing compute resources.
Appendices
1: Install Quilt in a Jupyter notebook
For reasons detailed by Jake Vanderplas, it's complicated to install packages from inside ad Jupyter notebook. Here's how to do it correctly:
import sys
!{sys.executable} -m pip install quilt
2: Install packages in a specific directory
If you wish for your data packages to live in a specific directory, for example on a shared drive, create a quilt_packages directory. If you're using Paperspace Gradient, the persistent /storage directory is an ideal home for data packages.
$ mkdir -p /storage/quilt_packages
Use an environment variable to tell Quilt where to search for packages:
%env QUILT_PRIMARY_PACKAGE_DIR=/storage/quilt_packages
3: Show me the files
Quilt de-duplicates files, serializes them to high-speed formats, and stores them under a unique identifier (the file's SHA-256 hash) in quilt_packages. As a result of de-duplication, files that are repeated across data packages are stored just once on disk. Data packages that include the same file, e.g. foo.csv, use a single reference to the foo.csv fragment in quilt_packages.
All of the above improves performance and reduces disk footprint, but sometimes you want to work with the underlying files. To accomplish this, use quilt.export:
quilt.export("akarve/BSDS300", "SOME_DIRECTORY")
You can now point your machine learning code at SOME_DIRECTORY and everything just works. Here's an example of exporting an image to infer its resolution with our PyTorch model.
The BSDS300 dataset is sourced from
@InProceedings{MartinFTM01, author = {D. Martin and C. Fowlkes and D. Tal and J. Malik}, title = {A Database of Human Segmented Natural Images and its Application to Evaluating Segmentation Algorithms and Measuring Ecological Statistics}, booktitle = {Proc. 8th Int'l Conf. Computer Vision}, year = {2001}, month = {July}, volume = {2}, pages = {416--423} }↩︎








