
Introduction
The ultimate goal of NLU research is to create machines that understand language as well as humans. This is challenging because humans use a variety of skills when trying to understand a single statement. First, a person must be fluent in the language to understand the statement and grasp its surface meaning. Second, they must be able to understand the language in its present context by using their prior knowledge.
This helps to clarify the meaning of the statement and to determine whether details are missing. Third, they should be able to ask a question to fill in any gaps. Finally, once they have a thorough understanding of the language, they should be able to articulate their understanding.
We believe that these abilities are critical for any NLU system that aims to provide humans with trustworthy answers when they ask them questions or engage in conversations with them.
Limitations of LLMs and potential solutions
Recently, LLMs have been taught using large amounts of text scraped from the web. They have demonstrated linguistic competence by reading comprehension, translating languages, and generating text to complete stories, poems, or code (Brown et al., 2020; Chen et al., 2021). However, they may not be sufficient for solving problems that require complex reasoning. Common sense reasoning and mathematical word problems have both been shown to expose the weaknesses of LLMs such as GPT-3 (Floridi and Chiriatti, 2020).
Even with techniques such as chain-of-thought prompting (Wei et al., 2022), such systems still make errors resulting from incorrect computations or omitted reasoning processes in the solution, making it difficult to rely on them alone. Although LLMs can be primed to provide reasons for their responses, the explanations and responses they provide are not always consistent (Wei et al., 2022). This casts doubt on the validity of such explanations. Without a clean break in logic, it's hard to evaluate how well the models are performing and to identify gaps in understanding that could be filled by incorporating common sense. We need improved NLU systems that use reasoning to address these issues.
In light of this insight, the authors propose the STAR (Semantic-parsing Transformer and ASP Reasoner) framework, which mimics the way humans process language. To perform the necessary reasoning and inference, STAR first maps a sentence to the semantics it represents, then augments it with common-sense information relevant to the concepts involved - just as humans do. To perform semantic parsing (translating sentences into predicates that encapsulate their semantics), the STAR framework uses LLMs while handing off reasoning to an Answer Set Programming (ASP) system.
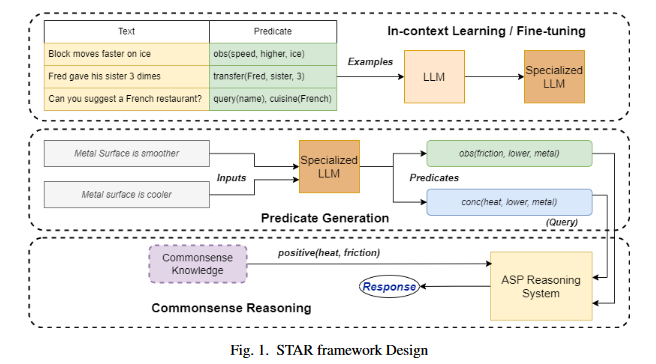
Experiments
- Experiments are conducted using modified versions of GPT-3 (Brown et al., 2020) to infer hypotheses from text. A specialized LLM can be trained using either fine-tuning or in-context learning with a limited set of text-predicate pair. In advance, ASP is used to encode common sense information about these predicates. A query is either explicitly specified for the problem or similarly generated from the problem using LLMs. (Arias et al., 2018)
- The query is executed on the s(CASP) (Arias et al. (2018)) goal-directed ASP system against the LLM-generated predicates and ASP-coded commonsense
knowledge to generate a response.
In this paper, the researchers apply the STAR framework to three different NLU applications:
- A system for solving qualitative reasoning problems
- A system for solving mathematical word problems, and
- A system representing a hotel concierge interacting with a human user seeking a restaurant recommendation.
All three tasks require different types of reasoning. The system needs to perform several stages of reasoning, including qualitative relationships and arithmetic operations for qualitative and mathematical reasoning tasks, respectively. The conversational bot task, on the other hand, requires the system to interact with the user to find, "understand," and infer missing information.
- Davinci (175B parameters) and Curie (6.7B parameters) are the two main variants of GPT-3 used in their studies. To evaluate the effectiveness of STAR, they predict responses using both models and then compare their predictions to the results from the framework. For the smaller LLM, which may be weaker at reasoning, the data show that STAR significantly improves response prediction accuracy.
- In both question-answering tasks, they are able to build proof trees for the generated answer so that the results can be understood by humans. When the models are just run with the LLMs, it is impossible to see the limitations and potential design changes; the knowledge predicates make this possible. They find that STAR performs significantly better in the conversational bot task, which requires deep reasoning, both in its ability to elicit information from the user and in its ability to provide restaurant suggestions that are accurate with respect to the database of restaurants it owns.
- However, when Davinci is used specifically to recommend restaurants, it modifies the information about those restaurants based on user interaction. Because this method uses s(CASP) for reasoning, the researchers can work with a large database of restaurants. Since there is a limitation on maximum prompt size, this is impossible when LLMs are used across the entire chat bot. As a result, the proposed solution is scalable, unlike an LLM-only solution.
Large Language Models
Until recently, transformer-based deep learning models were trained and tuned on task-specific datasets before being applied to NLP tasks (Casola et al., 2022). Large language models ushered in a new era in which language models could be trained to perform any task with only a small number of demonstrations( in-context learning).
- Brown et al. (2020) released GPT-3, an LLM with nearly 175 billion parameters that was trained on a large corpus of filtered online text, on which the well-known ChatGPT (OpenAI (2022)) is built.
- This model proved competitive in numerous tasks such as question answering, semantic parsing (Shin and Van Durme (2022)), and machine translation. However, such LLMs are prone to making basic errors in tasks like semantic (commonsense) and mathematical reasoning (Floridi and Chiriatti (2020); Wei et al. (2022)).
- Specifically, the researchers use GPT-3 for semantic parsing and rely on ASP for inference. Because LLMs undergo extensive pre-training, their proponents argue that they can be used to automatically extract information from text in the same way that humans can. In fact, the same set of predicates should be retrieved regardless of how the text is presented, even if it uses ungrammatical forms.
- It is possible to infer the predicate loves(alice,bob) from sentences like "Alice loves Bob," "Alice is in love with Bob," and "loves Alice Bob." Implicit predicates such as female(alice), male(bob), and person(alice), among others, might also be inferred. Using a small number of training examples, Da Vinci and Curie are able to accurately extract predicates from sentences.
Answer Set Programming and the s(CASP) system
The s(CASP) system (created by Arias et al. (2018)) is an answer set programming (Brewka et al. (2011)) system that allows predicates, restrictions over non-ground variables, uninterpreted functions, and, most significantly, a top-down, query-driven execution approach. These properties enable it to deliver answers with non-ground variables (potentially containing constraints among them) and calculate partial models by providing just the fragment of a stable model required to support the answer to a particular query.
The s(CASP) system supports constructive negation based on a disequality constraint solver, and unlike Prolog’s negation as failure and ASP’s default negation, not p(X) can return bindings for X on success, i.e., bind-
ings for which the call p(X) would have failed. Additionally, s(CASP) system’s interface with a constraint solver (over reals) allows for sound non-monotonic reasoning with constraints
It is possible to express complex commonsense information in ASP, and the s(CASP) query-driven predicate ASP system can be use to query that knowledge (Gupta (2022); Xu et al. (2023); Gelfond and Kahl (2014)). (Gelfond and Kahl (2014); Gupta (2022)) state that it is feasible to emulate commonsense knowledge by using:
- default rules
- integrity constraints, and
- various potential worlds.
Using default rules allows you to jump to a conclusion when there are no exceptions to the rule. For example, "a bird generally flies unless it is a penguin." Default rules are used here. Therefore, if someone were to tell us that Tweety is a bird, our first thought would be that he flies. If, in the future, we find out that Tweety is really a penguin, we will no longer believe that he can fly. According to Gelfond and Kahl (2014), elaboration-tolerant ways of encoding knowledge involve default norms that are supplemented by exceptions.
flies(X) :- bird(X), not abnormal bird(X).
abnormal bird(X) :- penguin(X).
Integrity constraints make it possible for us to specify invariants and scenarios that are impossible. It is physically impossible for a person to both sit and stand at the same time, for instance.
false :- person(X), sit(X), stand(X).
Finally, the existence of multiple possible worlds enables us to design alternate universes, each of which may share some aspects but have others that are fundamentally different. The world of children's books and the real world have many similarities; for instance, in both worlds, birds are able to fly; yet, in the world of children's books, birds are able to speak normally, while in the real world, they are unable to do so.
Modeling the vast majority of our commonsense knowledge requires the usage of default rules. Integrity constraints are helpful for assessing whether or not the information that was extracted is consistent. Multiple possible worlds allow us to perform assumption-based reasoning. For instance, given the information that "Alice loves Bob," we may infer that either Bob likewise loves Alice or he does not love Alice.
Qualitative Reasoning
The ability of a model to reason about the attributes of entities and events in the real world is tested through the use of qualitative reasoning. To test the answering of questions about the qualitative relationships of a set of physical attributes, Tafjord et al. (2019) presented the QuaRel dataset, which serves as an ideal test bed for this method. In this study, the authors use the STAR framework to improve upon previous attempts on the QuaRel dataset (Tafjord et al., 2019). Furthermore, they show that the STAR framework yields significant performance improvements over the direct use of the LLMs to question answering.
QuaRel is a dataset of 2771 questions organized into 19 categories, such as "friction", "heat", "speed", "time", etc. The association between these characteristics has to be taken into account if one wants to provide adequate answers to these questions. In each case, an observation is made about the two worlds in which one world has a greater (or lesser) value for a particular property. This observation requires a (common sense) inference about additional qualities that are present in both worlds. By making this inference, we can narrow down the possible answers to one.
In the following example, the question is taken directly from the dataset. In this particular illustration, the two different worlds are referred to as "carpet" and "floor". The inference that can be drawn from this study is that the distance that a toy vehicle travels in World1 (Floor) is greater. Therefore, the model must conclude that the amount of resistance or friction in World2 (carpet) would be greater, and this should lead to the selection of Option A as the correct answer.
Example :
Question: Alan noticed that his toy car rolls further on a wood
floor than on a thick carpet. This suggests that:
(world1: wood floor, world2: thick carpet)
(A) The carpet has more resistance (Solution)
(B) The floor has more resistance
Along with each question, Tafjord et al. (2019) gives a logical form that represents the semantics of the question. We use this form to extract the predicates that are required for our technique. The supplied logical form for the question that was presented before (example 3.1) is as follows:
qrel(distance, higher, world1) → qrel( f riction, higher, world2) ; qrel( f riction, higher, world1).The predicate qrel(distance, higher, world1) refers to the observation that the distance is higher in world1, while qrel( f riction, higher, world2) and qrel( f riction, higher, world1) refer to the conclusions drawn in the two answer options, respectively.
Predicate Generation Step
The authors make use of GPT-3 to transform the natural language query that is part of the Quarel dataset, along with its two answers, into appropriate predicates. Instead of relying only on in-context learning, they make use of the training dataset that they have at ther disposal to fine-tune the two GPT-3 model variations that we are utilizing for the QuaRel. These variants are known as Davinci and Curie.
The input prompt consists of the question (including answer options), followed by the world descriptions. The world descriptions are given so that the model can establish links between the two worlds and the ones in the generated predicates (obs and conc). Here are some examples of tuning prompts and their corresponding completion formats:
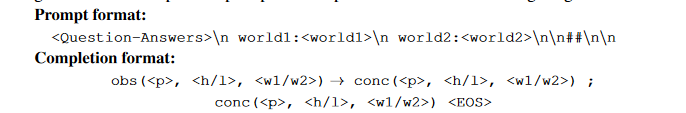
where p is a property, h/l is either higher or lower and w1/w2 is either world1 or world2. After fine-tuning on the training set using the prompt and completion pairs, we use the prompt to generate the completion during testing. The token helps cut off the generation when apt, avoiding completions that are either too long or too short. The extracted obs and conc predicates are then used by the logic program to determine the correct answer.
Commonsense reasoning step
The common sense knowledge that is necessary to answer the questions is stored in ASP in the form of facts and rules. First, the authors established a foundation for the 19 attributes using facts such as:
property(friction). property(heat). property(speed).Next, we will define the relationships between the attributes, making note of their positive and negative correlations as well as the symmetry, and then we will go on to the next step:
qplus(friction, heat). qminus(friction, speed).
qplus(speed, distance). qminus(distance, loudness).
positive(X, Y) :- qplus(X, Y). negative(X, Y) :- qminus(X, Y).
positive(X, Y) :- qplus(Y, X). negative(X, Y) :- qminus(Y, X).In the context of the QuaRel dataset, there are only two different worlds. Therefore, if a property has a higher value in world1, it must have a lower value in world2, and vice versa. We encapsulate this reasoning by using the opposite predicates and the rules listed below:
opposite_w(world1,world2). opposite_v(higher,lower).
opposite_w(world2,world1). opposite_v(lower,higher).
conc(P, V, W) :- obs(P, Vr, Wr), property(P),
opposite_w(W,Wr), opposite_v(V,Vr).It is necessary for us to take into consideration all four possible scenarios if we are to accurately represent the relationship that exists between each set of properties. If the properties P and Pr are positively correlated then
- if P is greater in world W, Pr must likewise be higher in W, and
- if P is higher in world W, Pr must be lower in the other world Wr.
In a similar vein, if P and Pr have a negative correlation, then
- if P is higher in world W, then Pr must be lower in W, and
- if P is higher in world W, then Pr must be higher in the other world Wr.
It is important to note that the higher/lower relations can be flipped in any of the examples described above. The following guidelines can be used to represent these four possibilities in logical form:
conc(P,V,W) :- obs(Pr,V,W), property(P), property(Pr),
positive(P,Pr).
conc(P,V,W) :- obs(Pr,Vr,Wr), property(P), property(Pr),
opposite_w(W,Wr), opposite_v(V,Vr), positive(P,Pr).
conc(P,V,W) :- obs(Pr,Vr,W), property(P), property(Pr),
opposite_v(V,Vr), negative(P,Pr).
conc(P,V,W) :- obs(Pr,V,Wr), property(P), property(Pr),
opposite_w(W,Wr), negative(P,Pr).A proper conclusion (conc) may be verified using this body of knowledge once a factual assertion is made in the form of an observation (obs). Checking for entailment of the two alternative conclusions leads us to the solution for the issue in the following example:
assert(obs(distance, higher, world1)), conc( f riction, higher, world2). → True
and
assert(obs(distance, higher, world1)), conc( f riction, higher, world1). → FalseResults and Evaluation
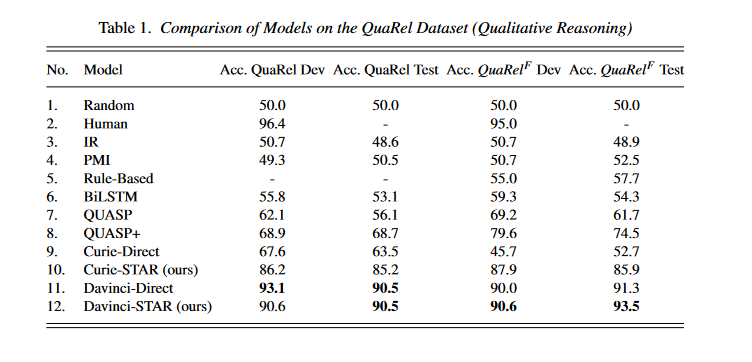
Table 1 shows a comparison between the results of our models and those of Tafjord et al. (2019). Four different QuaRel datasets were evaluated for their accuracy (QuaRelF is the subset of the dataset that contains only questions about friction). The first eight rows show how well the baseline models proposed by Tafjord et al. (2019) perform.
After fine-tuning on the QuaRel training set, the Curie-Direct and DaVinci-Direct rows show the performance of the Curie and DaVinci models that directly predict the answer. The Curie-STAR and DaVinci-STAR rows show the results for our method, which involves first generating the predicates and then reasoning using ASP and commonsense knowledge. For each dataset, the highest accuracy values are highlighted.
Conclusion
Davinci-STAR outperforms the state-of-the-art on QuaRel, and it also outperforms Davinci-Direct on three of the four datasets compared. Table 1 also shows the dramatic increase in accuracy of the Curie model on all datasets. This leads us to conclude that while Davinci has some reasoning ability, Curie does not.
Therefore, our framework helps to close the gap by using an external line of reasoning. Interestingly, Davinci-Direct performs better than Davinci-STAR on the QuaRel-Dev dataset.
Some properties (such as "smoke" instead of "heat" because the question mentions smoke) are generated by the LLM even if they do not exist in the domain, as the researchers discovered. A training set enriched with relevant examples (such as one that associates the presence of smoke with the property of heat) can correct such errors. It's possible that the training data will include a wider range of questions about friction, since this is the attribute that makes up the bulk of QuaRel's queries.








