
Introduction
The transformer model was initially introduced in 2017 for a machine translation task, and since then, several models have been built based on the original transformer model's inspiration to solve a wide range of problems in various industries. While some models have used the vanilla transformer design, others have just used the transformer model's encoder or decoder module. Some have gone further to develop whole new versions of the architecture.
As a consequence, depending on the architecture used, the workload and performance of transformer-based models might differ. Nonetheless, self-attention is a critical and extensively utilized component of transformer models, since it is required for their operation. All transformer-based models use the self-attention mechanism and multi-head attention, which often comprise the architecture's core learning layer. Given the importance of self-attention, the involvement of the attention process in transformer models is critical.
Attention mechanism
Because of its capacity to focus on key bits of information, the attention mechanism has received widespread attention since its inception in the 1990s. Using attention, certain image portions are identified to be more relevant than others during image processing. As a result, the attention mechanism was developed as an original approach in computer vision tasks, with the goal of emphasizing key components depending on their context in the application. When used in computer vision, this approach achieved remarkable results, driving its wider use in other domains such as language processing.
An attention-based neural network that was given the name "transformer" was developed to solve the shortcomings of previous neural networks in recording long-range dependencies in sequences, particularly in language translation tasks (Vaswani et al., 2017). The performance of the attention mechanism was enhanced by the introduction of a self-attention mechanism into the transformer model. This enabled the attention mechanism to better capture local characteristics and reduce its dependence on information obtained from the outside. Query (Q), Key (K), and Value (V) are the three basic parameter matrices that are used in the "Scaled Dot Product Attention" that is utilized in the original transformer design to perform the attention mechanism.
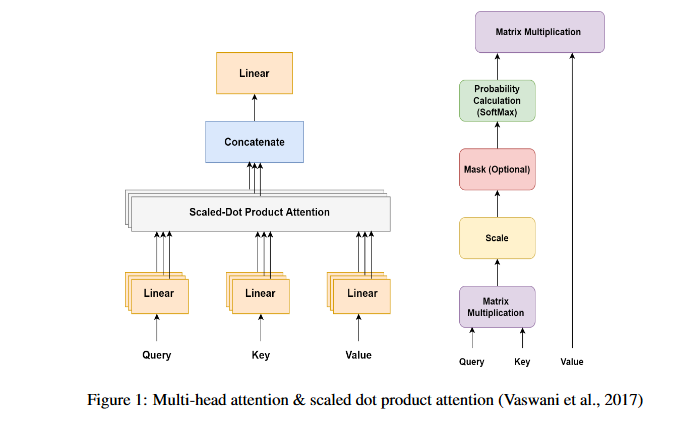
These matrices store encoded representations of the sequence's inputs (Vaswani et al., 2017). As shown in Figure 1, the attention process culminates in a probability score calculated by the weighted sum of the three matrices, which is then subjected to the SoftMax function. The scaled dot product attention function may be calculated using the formula:
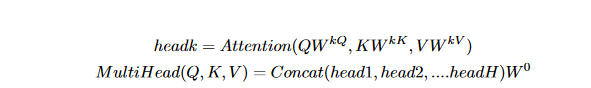
Matrix V represents the values vectors, whereas matrices Q and K represent the Query and Key vectors, respectively.
Multi-head attention
The application of the scaled dot-product attention function in parallel within the multi-head Attention module is essential for extracting the maximum dependencies among different segments in the input sequence. Each head denoted by k performs the attention mechanism based on its own learnable weights W kQ, W kK , and W kv . The attention outputs calculated by each head are subsequently concatenated and linearly transformed into a single matrix with the expected dimension (Vaswani et al.,2017)
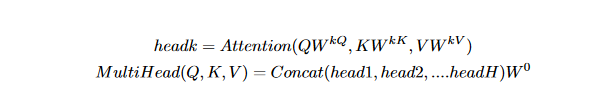
Using multi-head attention helps the neural network to learn and capture various aspects of the sequential information it is fed as input. As a result, the representation of the input contexts is improved due to the fusion of information from various aspects of the attention mechanism within a certain range, which may be either brief or lengthy. According to Vaswani et al. (2017), the benefits of this strategy include improved network performance as a consequence of the attention mechanism's ability to jointly operate.
Architecture of the transformer model
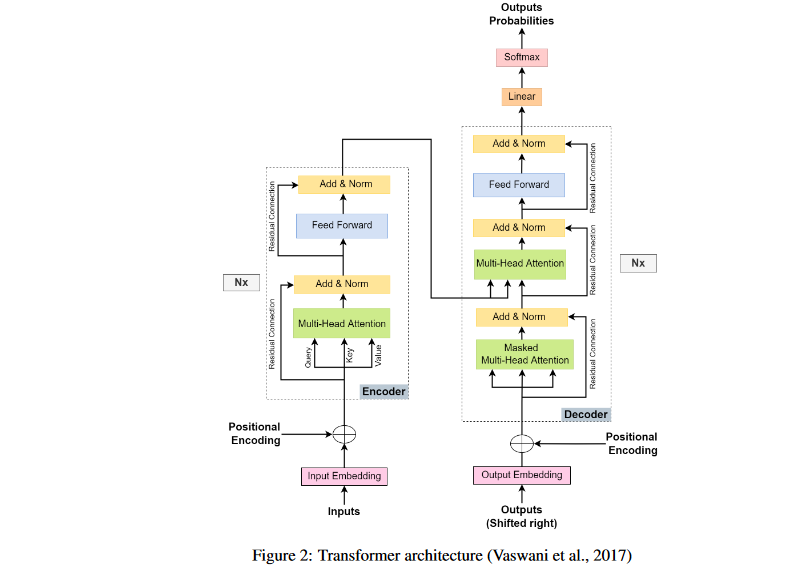
Processing sequential data was the main motivation for the development of the transformer model, which was first constructed on the attention mechanism (Vaswani et al., 2017). The extensive usage of transformers can be attributed to their exceptional performance, particularly in reaching state-of-the-art benchmarks for natural language processing (NLP) translation models. The use of attention processes is an integral part of the overall design of the transformer model for sentence translation tasks. This can be shown in Figure 2. Nevertheless, the design of the transformer might be susceptible to changes for various purposes; this is determined by the unique needs of each application.
Based on the auto-regressive sequence transduction model, the first transformer architecture was designed with the encoder and decoder as its central processing nodes. Depending on the nature of the work at hand, these modules may be run numerous times. The attention mechanism is integrated across several layers in each module. In particular, the transformer design executes the attention mechanism in parallel numerous times, which is why there are multiple "Attention Heads" (Vaswani et al., 2017).
The following sections contain breakdowns of the components for the encoder and decoder modules in the transformer architecture.
Encoder module
- The Feed-Forward Layer and the Multi-Head Attention Layer are the two main components that make up the stacked module that is included inside the transformer design. According to Vaswani et al. (2017), it also features residual connections surrounding both layers, in addition to two Add and Norm layers, both of which play important roles in the process.
- When translating text, the Embedding and Position Encoding layers are used to build an embedding input that is sent on to the encoder module. The embedding input is used to generate the Query (Q), Key (K), and Value (V) matrices, as well as positional information. These matrices are then sent into the "Multi-Head Attention" layer.
- the Feed-Forward layer takes care of the potential problem of rank collapse in the the computation process. When applied at each step, a normalization layer standardizes the weights used in the gradient computation inside each layer, hence reducing the dependencies across layers.
- As shown in Figure 2, the residual connection is applied to each output of the attention layer as well as the feed-forward layer in order to solve the problem of vanishing gradients.
Decoder module
- The decoder module in the transformer architecture functions in a manner that is similar to that of the encoder module, but with the addition of several extra layers, such as Masked Multi-Head Attention. The decoder includes Masked Multi-Head Attention layers in addition to the Feed-Forward, Multi-Head Attention, Residual connection, and Add and Norm layers .
- These layers exclude future predictions by using the scaled dot product and Mask Operations. Instead, they only examine previous outputs.
- The Attention technique is used not once but twice throughout the decoder: one for locating attention between the encoding inputs and the desired output, and another for computing attention between pieces of the desired output. After the attention vectors are generated, the feed-forward unit processes them so that the layer outputs can be understandable.
- The result of the generated decoding is then captured by the Linear and SoftMax layers at the top of the decoder. These layers are responsible for computing the final output of the transformer design. This method is carried out an infinite number of times until the last token of a sentence is located.
Conclusion
In the Transformer design, the event horizon, singularity, and mass are all crucial components. Since its inception in 2017, the Transformer design has undergone several iterations and split off into numerous versions, allowing it to be used to applications outside of language processing, such as time series forecasting, protein structure prediction, and source code synthesis. The Transformer architecture is effective because to its ability to process and train more data in less time, its flexibility in dealing with a wide variety of sequential data types, and its utility in spotting anomalies.
Reference :
A Deep Dive Into the Transformer Architecture — The Development of Transformer Models: https://towardsdatascience.com/a-deep-dive-into-the-transformer-architecture-the-development-of-transformer-models-acbdf7ca34e0










