Updated May 9, 2022: This blog post contains references to the now deprecated Paperspace jobs. If you are interested in a similar functionality on Paperspace, please check out Gradient Workflows in our docs.
A very brief introduction to LSTMs
There are various types of neural network architectures. Depending on your task, the data you have at hand and the output you want to generate, you can choose or create different network architectures and design patterns. If your dataset contains images or pixels, then a Convolutional Neural Networks could be what you need. If you are trying to train a network on a sequence of inputs, then a Recurrent Neural Networks (RNN) might work. RNNs are a kind of artificial neural network that achives really good results when your goal is to recognize patterns in sequences of data. And when working with text data any model that calculates the probability of the next character given the previous character is called a language model 1
RNNs are very useful if your input is, for example, a corpus of text or a musical composition and you are trying to predict meaningful sequences out of it. Long Short-Term Memory networks, or LSTMs, are just a special type of RNN that can perform better when learning about “long-term dependencies".
For example, if you have a large dataset of text you can train an LSTM model that will be able to learn the statistical structure of the text data. You can then sample from that model and create sequences of meanigul characters that will look like the original training data. So in other words, if you are trying to predict the last word in the following sentence:
“I grew up in France … I speak fluent [ ] ”,
LSTMs can help figure this out. By learning about the context of the sentence, based on the training data, it can suggest that the word that follows is "French" 2
We will use the LSTM generative capacity to create an interactive online demo where you can sample characters from a trained model and generate new sequences of text based on what you write.
A brief introduction to ml5.js
The good news about LSTMs is that there are a lot of good ways to easily get started using them without going too deep of a dive in to the technical underpinnings. One such ways is with ml5.js.
ml5.js is a new JavaScript library that aims to make machine learning approachable for a broad audience of artists, creative coders, and students. The library provides access to machine learning algorithms and models in the browser, building on top of TensorFlow.js with no other external dependencies. The project is currently being maintained at NYU ITP by a community of teachers, residents and students. You can learn more about the history of ml5.js in this article or in this Twitter thread.
This tutorial will use the ml5.LSTMGenerator() method to load a pre-trained LSTM model which we will develop throughout this article, with Python and GPU accelerated computing, and use it to generate new sequences of characters in Javascript.
Curious? Here is a demo of what we will be building. This examples uses a model trained on a corpus of Ernest Hemingway. Start typing something and the model will suggest new lines based on your writing:
Setting up
LSTMs take a long time to train so we will use a P5000 GPU graphics card to speed things up. The only requirement to run this tutorial is to have Node.js installed and a Paperspace account.
The training code for this tutorial is based on char-rnn-tensorflow which in turn was inspired from Andrej Karpathy's char-rnn.
Install the Paperspace node API
We will use the Paperspace Node API. You can easily install it with npm:
npm install -g paperspace-node
or with Python:
pip install paperspace
(you can also install binaries from the GitHub releases page if you prefer).
Once you have created a Paperspace account you will be able to login in with your credentials from your command line:
paperspace login
Add your Paperspace email and password when prompted.
Training Instructions
1) Clone the repository
The code for this project can be found here. Start by cloning or downloading the repository:
git clone https://github.com/Paperspace/training-lstm.git
cd training-lstm
This will be the root of our project.
2) Collect your data
LSTMs work well when you want to predict sequences or patterns from a large dataset. Try to gather as much clean text data as you can! The more the better.
Once you have your data ready, create a new folder inside /data and called it anyway you want. Inside that new folder just add one file called input.txt that contains all your training data.
(A quick tip to concatenate many small disparate .txt files into one large training file: ls *.txt | xargs -L 1 cat >> input.txt)
For this example, we are going to use some of Zora Neale Hurston books as our source text, since they are available for free on Project Gutenberg. You can find the input.txt file we will use here.
3) Run your code on Paperspace
The code to train the LSTM is contained inside the project you just downloaded. The only file we will need to modify is run.sh. This file sets all the parameters we need:
python train.py --data_dir=./data/zora_neale_hurston \
--rnn_size 128 \
--num_layers 2 \
--seq_length 50 \
--batch_size 50 \
--num_epochs 50 \
--save_checkpoints ./checkpoints \
--save_model /artifacts
Here we are setting all your hyperparameters: input data, the amount of layers of the network, the batch size, number of epochs and where to save the checkpoints and final model. We will use the default settings for now, but check the Tuning the model section to learn more about how to best train your network. The only line you will need to modify will be the --data_dir=./data/bronte to point to your own dataset (ie: --data_dir=./data/MY_OWN_DATA
Now we can start the training process. Just type:
paperspace jobs create --container tensorflow/tensorflow:1.5.1-gpu-py3 --machineType P5000 --command 'bash run.sh' --project 'LSTM training'
This means we want to create a new paperspace job using as a base container a Docker image that comes with Tensorflow 1.5.1 and Python 3 installed (this way we don't need to worry about installing dependencies, packages or managing version). We also want to use a machineType P5000 and we want to run the command bash run.sh to start the training process. This project will be called LSTM training
If you typed this right (or copied it correctly), the training process should start and you should see something like this:
Uploading training-lstm.zip [========================================] 18692221/bps 100% 0.0s
New jobId: j8k4wfq65y8b6
Cluster: PS Jobs on GCP
Job Pending
Waiting for job to run...
Job Running
Storage Region: GCP West
Awaiting logs...
Here we go! Reading text file...
{"chart": "loss", "axis": "Iteration"}
{"chart": "loss", "x": 0, "y": 4.431717}
0/4800 (epoch 0), train_loss = 4.432, time/batch = 0.447
Model saved to ./checkpoints/zora_neale_hurston/zora_neale_hurston!
{"chart": "loss", "x": 1, "y": 4.401691}
1/4800 (epoch 0), train_loss = 4.402, time/batch = 0.060
{"chart": "loss", "x": 2, "y": 4.337208}
2/4800 (epoch 0), train_loss = 4.337, time/batch = 0.059
{"chart": "loss", "x": 3, "y": 4.193798}
3/4800 (epoch 0), train_loss = 4.194, time/batch = 0.058
{"chart": "loss", "x": 4, "y": 3.894172}
4/4800 (epoch 0), train_loss = 3.894, time/batch = 0.056
This might take take a while to run, LSTMs are known for talking time to train. A good thing is that you don't need to monitor the complete process, but you can check how it is going by typing:
paperspace jobs logs --tail --jobId YOUR_JOB_ID
If you login into your Paperspace accout you can also follow the training process, under the Gradient tab, more interactively:
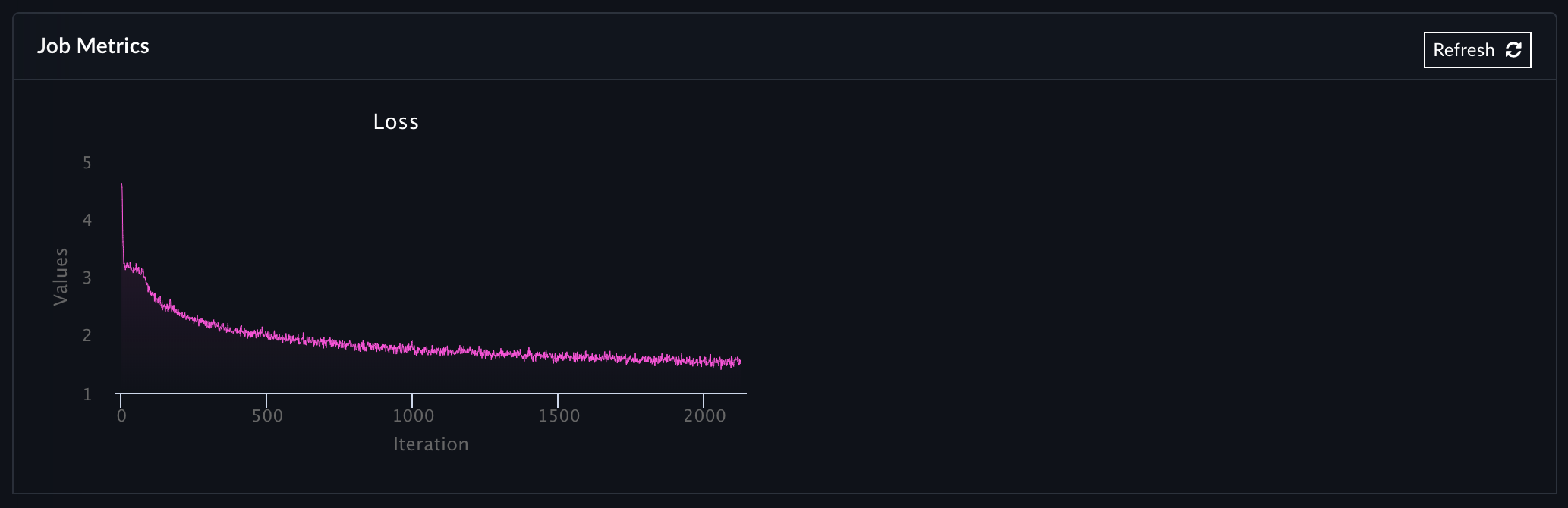
Once the training process is completed you should see the following log:
Model saved to ./checkpoints/zora_neale_hurston/zora_neale_hurston!
Converting model to ml5js: zora_neale_hurston zora_neale_hurston-18
Done! The output model is in /artifacts
Check https://ml5js.org/docs/training-lstm for more information.
4) Use the model in ml5.js
Now we can sample from the model in JavaScript with ml5js. The model was saved inside the /artifacts folder of the job. So we first need to download it. From the root of the project change directory into /ml5js_example/models and the run:
paperspace jobs artifactsGet --jobId YOUR_JOB_ID
This will download all the files we will need that containin your trained model.
Now open the sketch.js file and change the name of your model in the following line:
const lstm = ml5.LSTMGenerator('./PATH_TO_YOUR_MODEL', onModelReady);
The rest of the code is fairly straight forward. Once we create our lstm method with ml5js, we can make it sample the model by using the following function:
const data = {
seed: 'The meaning of life is ',
temperature: 0.5,
length: 200
};
lstm.generate(data, function(results){
/* Do something with the results */
});
We are almost ready to test the model. The only thing left is to start a server to view our files. If you are using Python 2:
python -m SimpleHTTPServer
If you are using Python 3:
python -m http.server
Visit http://localhost:8000 and if everything went well you should see the demo:
There you go! We trained a multi-layer recurrent neural network (LSTM, RNN) for character-level language using Python, with GPU acceleration, ported the resulting model to JavaScript and use it in an interactive demo to create sequences of text with ml5js.
5) Tuning the model
Tuning your models might hard because there are a lot of parameters and variables involded. A good starting point can be to follow the original's repository recommendations. But in general, here are some good insights to consider given the size of the training dataset:
- 2 MB:
- rnn_size 256 (or 128)
- layers 2
- seq_length 64
- batch_size 32
- dropout 0.25
- 5-8 MB:
- rnn_size 512
- layers 2 (or 3)
- seq_length 128
- batch_size 64
- dropout 0.25
- 10-20 MB:
- rnn_size 1024
- layers 2 (or 3)
- seq_length 128 (or 256)
- batch_size 128
- dropout 0.25
- 25+ MB:
- rnn_size 2048
- layers 2 (or 3)
- seq_length 256 (or 128)
- batch_size 128
- dropout 0.25
Resources
Learning more about LSTMs
- Understanding LSTMs, by Christopher Olah
- The Unreasonable Effectiveness of Recurrent Neural Networks, by Andrej Karpathy.