
Activation functions have seen a massive resurgence in terms of advancements in research and formulation of novel activation functions. Some of these approaches have had different motivations or intuition behind the formula. While some relied on Neural Architecture Search (NAS) to find optimal activation functions based on performance and computational budget constraints (like that of Swish), others focused on more theoretical grounds of improved information propagation and smoothing properties exerted on the loss landscapes of deep neural networks (like that of Mish), some also primarily focused on performance solely (like that of Funnel Activation) while few others were designed primarily for specific niche domains like Super Resolution or Image Reconstruction (like SIREN and XUnit). However, synchronous to activation functions, especially in the domain of computer vision (CV), attention mechanisms have seen a significant uprising with different approaches trying to achieve somewhat the same goal of improving feature representation in intermediate feature maps. However, attention has in many ways remained a separate entity as compared to activation functions while abstractly they can generalize to each other. In this blog post, we will take a look at a paper titled "Attention as Activation" by Dai. et. al., which attempts to unravel this unknown face of the dice, by essentially combining attention with activation and integrating it into standard deep convolutional neural network architectures.
To follow, we will first take a look at the motivating groundwork behind the method proposed in the paper called Attentional Activation (ATAC), followed by an in-depth breakdown of the structure of ATAC and its similarities with that of Squeeze-and-Excitation networks, and finally, wrap it by providing the code and skimming through the results in the paper.
Table of Contents
- Motivation
- ATAC
- Code
- Results
- Conclusion
- References
Bring this project to life
Abstract
Activation functions and attention mechanisms are typically treated as having different purposes and have evolved differently. However, both concepts can be formulated as a nonlinear gating function. Inspired by their similarity, we propose a novel type of activation units called attentional activation (ATAC) units as a unification of activation functions and attention mechanisms. In particular, we propose a local channel attention module for the simultaneous non-linear activation and element-wise feature refinement, which locally aggregates point-wise crosschannel feature contexts. By replacing the well-known rectified linear units by such ATAC units in convolutional networks, we can construct fully attentional networks that perform significantly better with a modest number of additional parameters. We conducted detailed ablation studies on the ATAC units using several host networks with varying network depths to empirically verify the effectiveness and efficiency of the units. Furthermore, we compared the performance of the ATAC units against existing activation functions as well as other attention mechanisms on the CIFAR-10, CIFAR-100, and ImageNet datasets. Our experimental results show that networks constructed with the proposed ATAC units generally yield performance gains over their competitors given a comparable number of parameters.
Motivation
Attention mechanisms have been a significant area of research in the domain of computer vision lately and have significantly contributed towards pushing the state of the art in different tasks. While activation functions also remain a popular area of research, the appeal for ReLU, the longstanding default activation function, has been highly overwhelming for many novel activation functions with strong theoretical backgrounds that have been proposed to conquer over ReLU. However, both attention mechanisms and activation functions have the capacity to generalize to each other. The authors make a very interesting point which essentially states that while attention mechanisms are aimed to capture long range dependencies, activation functions heavily rely on local context and are often simple pointwise gating mechanism, thus not necessarily improving on the feature representation constructed by the previous convolutional layers in that architecture.
In this work, we propose the attentional activation (ATAC) unit to tackle the above shortcomings, which depicts a novel dynamic and context-aware activation function. One of our key observation is that both the attention mechanism and the concept of a activation function can be formulated as a nonlinear adaptive gating function. More precisely, the activation unit is a non-context aware attention module, while the attention mechanism can be seen as a context-aware activation function. Besides introducing nonlinearity, our ATAC units enable networks to conduct a layerwise context-aware feature refinement:
1) The ATAC units differ from the standard layout of ReLUs and offer a generalized approach to unify the concepts of activation functions and attention mechanisms under the same framework of non-linear gating functions.
2) To meet both, the locality of activation functions and the contextual aggregation of attention mechanisms, we propose a local channel attention module, which aggregates point-wise cross-channel feature contextual information.
3) The ATAC units make it possible to construct fully attentional networks that perform significantly better with a modest number of additional parameters.
ATAC
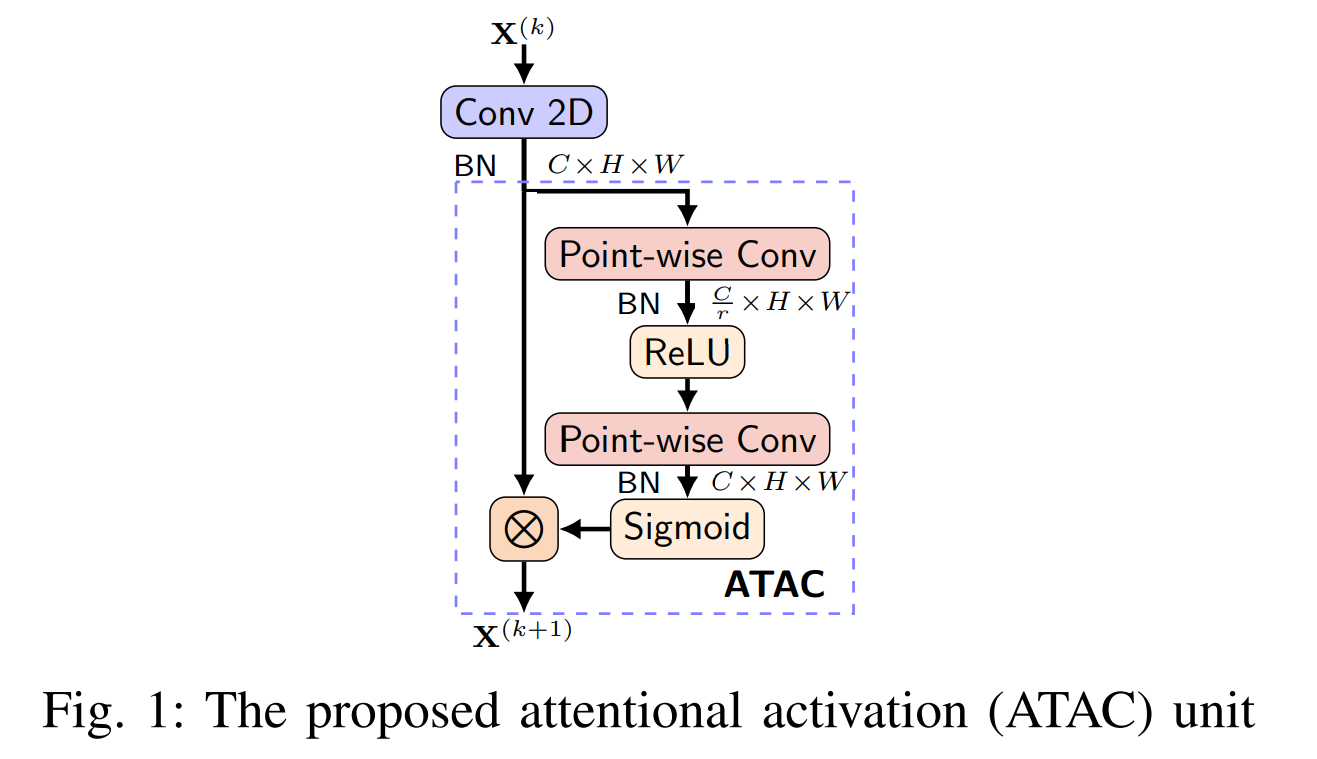
At first glance, ATAC essentially looks to be Squeeze-and-Excitation networks. And you're absolutely right in making that assumption. It is indeed a Squeeze-and-Excitation block with a small tweak of no Global Average Pool at the start and used as a replacement of the ReLU activation functions in the convolution layer blocks. So without further adieu, let's take a look at the structure. So for a given input tensor $X \in \mathbb{R}^{C \ast H \ast W}$ which was the output of a prior convolution and batch normalization layer, first the tensor is reduced along the channel dimension by a predefined reduction ratio $r$ which results in a tensor $\hat{X} \in \mathbb{R}^{\frac{C}{r} \ast H \ast W}$ by using a pointwise ($1 \ast 1$) convolution. This is followed by a normalization (Batch Norm) layer and a ReLU activation. Lastly the tensor is then upsampled along the channel dimension back to the shape of original tensor using a pointwise convolution which outputs the tensor $\tilde{X} \in \mathbb{R}^{C \ast H \ast W}$. Then a sigmoid activation is applied on this tensor before multiplying it element wise to the actual input $X$.
Note: For more clarity on Squeeze-and-Excitation networks, please go through my blog post on the same which can be found here.
Code
The following code snippet provides the PyTorch code and MXNet code for the ATAC activation module which can be used to replace ReLU or any other standard activation function used in deep convolutional neural network architectures.
MXNet implementation:
from __future__ import division
from mxnet.gluon.block import HybridBlock
from mxnet.gluon import nn
class ChaATAC(HybridBlock):
def __init__(self, channels, r, useReLU, useGlobal):
super(ChaATAC, self).__init__()
self.channels = channels
self.inter_channels = int(channels // r)
with self.name_scope():
self.module = nn.HybridSequential(prefix='module')
if useGlobal:
self.module.add(nn.GlobalAvgPool2D())
self.module.add(nn.Conv2D(self.inter_channels, kernel_size=1, strides=1, padding=0,
use_bias=False))
self.module.add(nn.BatchNorm())
if useReLU:
self.module.add(nn.Activation('relu'))
self.module.add(nn.Conv2D(self.channels, kernel_size=1, strides=1, padding=0,
use_bias=False))
self.module.add(nn.BatchNorm())
self.module.add(nn.Activation('sigmoid'))
def hybrid_forward(self, F, x):
wei = self.module(x)
x = F.broadcast_mul(x, wei)
return xPyTorch implementation:
import torch
import torch.nn as nn
import torch.nn.functional as F
class ATAC(nn.Module):
def __init__(self, channels, r, useReLU):
super(ATAC, self).__init__()
self.relu = useReLU
if self.relu is True:
self.act = nn.ReLU()
self.channels = channels
self.inter_channels = int(channels // r)
self.conv = nn.Conv2d(channels, inter_channels, 1,1,0)
self.bn = nn.BatchNorm2d(inter_channels)
self.conv2 = nn.Conv2d(inter_channels, channels, 1,1,0)
self.bn2 = nn.BatchNorm2d(channels)
def forward(self, x):
out1 = self.bn(self.conv(x))
if self.relu is True:
out1 = self.act(out1)
out2 = self.bn2(self.conv2(out1))
return x * torch.sigmoid(out2)To run ResNet models equipped with ATAC activation function units (for instance a ResNet-18) on CIFAR datasets use the following command in the jupyter environment in Paperspace Gradient, link to which is provided at the start of this post.
CIFAR-10
python train_cifar_full.py --project ATAC --name atac --version 2 --arch 1CIFAR-100
python train_cifar100_full.py --project ATAC --name atac --version 2 --arch 1Note: You would require a Weights & Biases account to enable WandB Dashboard logging.
Results
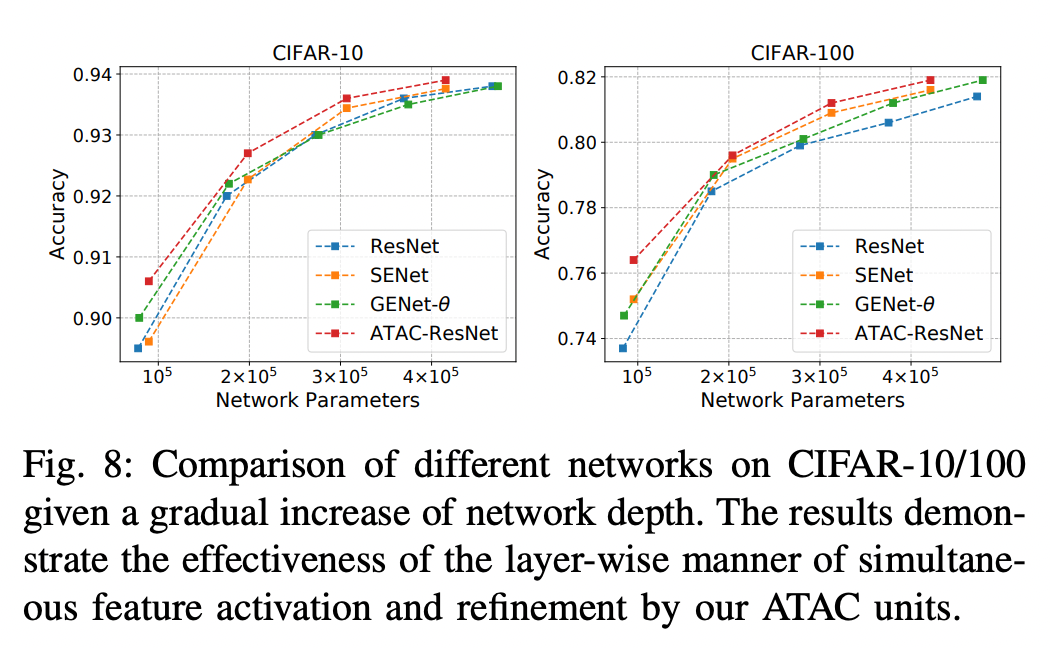
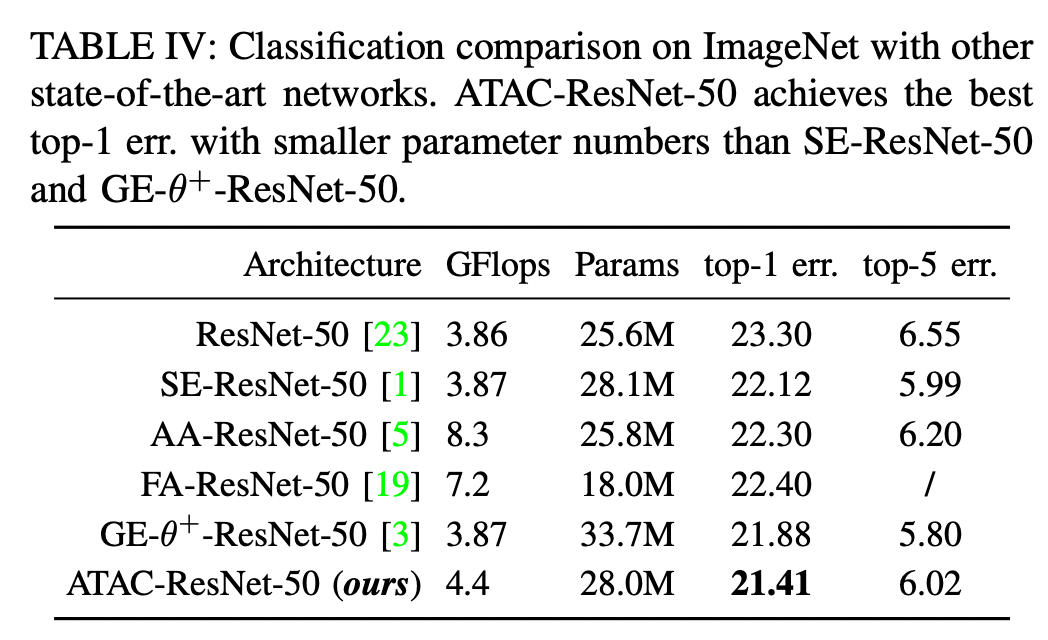

Conclusion
Considering the novelty of this paper is more in the way of applying ATAC rather than the design of the structure itself, it's fair to say that it does open some new avenues towards how we interpret attention and distinguish them from activations. However, the major drawback here is the increase in FLOPs and parameters. The overall method is extremely computationally costly and is unadvisable for training under budget constraints.








