

Introduction
Self-supervised approaches have completed many different types of NLP tasks.
Denoising autoencoders trained to recover text when a random subset of words has been masked off has proven to be the most effective method.
Gains have been proven in recent work by enhancing the masking distribution, masking prediction order, and context for replacing mask tokens.
Although promising, these approaches are often limited in scope to just a few distinct tasks (such as span prediction, span creation, etc.).
What is the BART Transformer Model in NLP?
This paper introduces BART, a pre-training method that combines Bidirectional and Auto-Regressive Transformers. BART is a denoising autoencoder that uses a sequence-to-sequence paradigm, making it useful for various applications. Pretraining consists of two phases: (1) text is corrupted using an arbitrary noising function, and (2) a sequence-to-sequence model is learned to reconstruct the original text.
BART's Transformer-based neural machine translation architecture can be seen as a generalization of BERT (due to the bidirectional encoder), GPT (With the left-to-right decoder), and many other contemporary pre-training approaches.
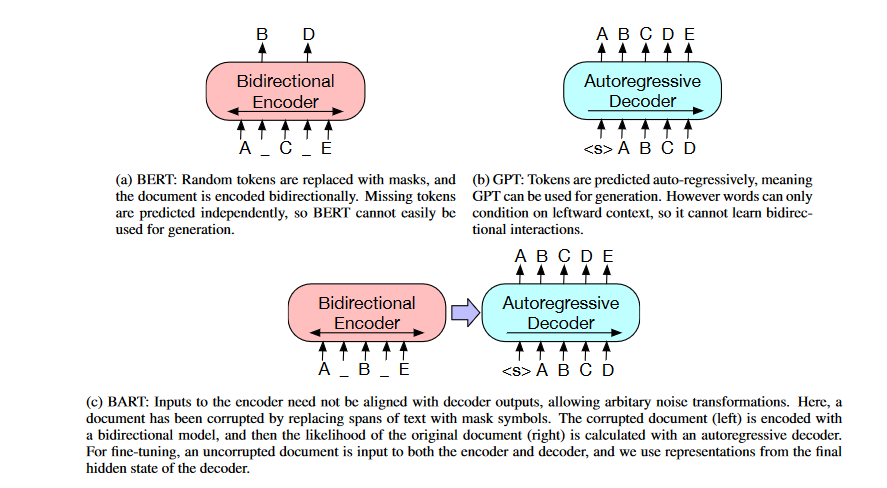
In addition to its strength in comprehension tasks, BART's effectiveness increases with fine-tuning for text generation. It generates new state-of-the-art results on various abstractive conversation, question answering, and summarization tasks, matching the performance of RoBERTa with comparable training resources on GLUE and SQuAD.
Architecture
Except changing the ReLU activation functions to GeLUs and initializing parameters from (0, 0.02), BART follows the general sequence-to-sequence Transformer design (Vaswani et al., 2017). There are six layers in the encoder and decoder for the base model and twelve layers in each for the large model.
Similar to the architecture used in BERT, the two main differences are that (1) in BERT, each layer of the decoder additionally performs cross-attention over the final hidden layer of the encoder (as in the transformer sequence-to-sequence model); and (2) in BERT an additional feed-forward network is used before word prediction, whereas in BART there isn't.
Pre-training BART
To train BART, we first corrupt documents and then optimize a reconstruction loss, which is the cross-entropy between the decoder's output and the original document. In contrast to conventional denoising autoencoders, BART may be used for any type of document corruption.
The worst-case scenario for BART is when all source information is lost, which becomes analogous to a language model. The researchers try out several new and old transformations, but they also believe there is much room for creating even more unique alternatives.
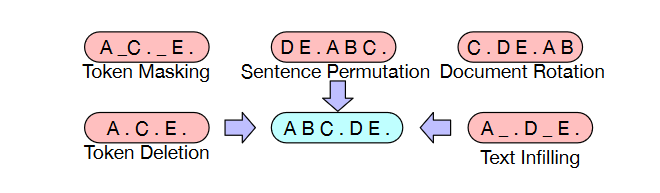
In the following, we will outline the transformations they performed and provide some examples. Below is a summary of the transformations they used, and an illustration of some of the results is provided in the figure.
- Token Masking: Following BERT, random tokens are sampled and replaced with MASK elements.
- Token Deletion: Random tokens are deleted from the input. In contrast to token masking, the model must predict which positions are missing inputs.
- Text Infilling: Several text spans are sampled, with span lengths drawn from a Poisson distribution (λ = 3). Each span is replaced with a single MASK token. Text infilling teaches the model to predict how many tokens are missing from a span.
- Sentence Permutation: A document is divided into sentences based on full stops, and these sentences are shuffled in random order.
- Document Rotation: A token is chosen uniformly at random, and the document is rotated to begin with that token. This task trains the model to identify the start of the document.
Fine-tuning BART
Several potential uses for the representations BART generates in subsequent processing steps exist:
- Sequence Classification Tasks: For sequence classification problems, the same input is supplied into the encoder and decoder, and the final hidden states of the last decoder token is fed into the new multi-class linear classifier.
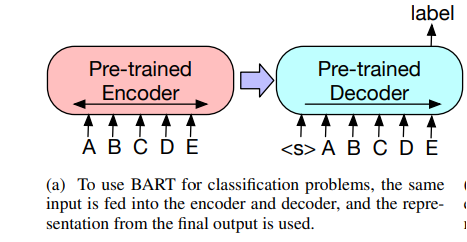
- Token Classification Tasks: Both the encoder and decoder take the entire document as input, and from the decoder's top hidden state, a representation of each word is derived. The token's classification relies on its representation.
- Sequence Generation Tasks: For sequence-generating tasks like answering abstract questions and summarizing text, BART's autoregressive decoder allows for direct fine-tuning. Both of these tasks are related to the pre-training goal of denoising since they involve the copying and subsequent manipulation of input data. Here, the input sequence serves as input to the encoder, while the decoder generates outputs in an autoregressive manner.
- Machine Translation: The researchers investigate the feasibility of using BART to enhance machine translation decoders for translating into English. Using pre-trained encoders has been proven to improve models, while the benefits of incorporating pre-trained language models into decoders have been more limited. Using a set of encoder parameters learned from bitext, they demonstrate that the entire BART model can be used as a single pretrained decoder for machine translation. More specifically, they swap out the embedding layer of BART's encoder with a brand new encoder using random initialization. When the model is trained from start to end, the new encoder is trained to map foreign words into an input BART can then translate into English. In both stages of training, the cross-entropy loss is backpropagated from the BART model's output to train the source encoder. In the first stage, they fix most of BART's parameters and only update the randomly initialized source encoder, the BART positional embeddings, and the self-attention input projection matrix of BART's encoder first layer. Second, they perform a limited number of training iterations on all model parameters.
BART Model for Text Summarization
It takes much time for a researcher or journalist to sift through all the long-form information on the internet and find what they need. You can save time and energy by skimming the highlights of lengthy literature using a summary or paraphrase synopsis.
The NLP task of summarizing texts may be automated with the help of transformer models. Extractive and abstractive techniques exist to achieve this goal. Summarizing a document extractively involves finding the most critical statements in the text and writing them down. One may classify this as a type of information retrieval. More challenging than literal summarizing is abstract summarization, which seeks to grasp the whole material and provide paraphrased text to sum up the key points. The second type of summary is carried out by transformer models such as BART.
HuggingFace gives us quick and easy access to thousands of pre-trained and fine-tuned weights for Transformer models, including BART. You can choose a tailored BART model for the text summarization assignment from the HuggingFace model explorer website. Each submitted model includes a detailed description of its configuration and training. The beginner-friendly bart-large-cnn model deserves a look, so let's look at it. Either use the HuggingFace Installation page or run pip install transformers to get started. Next, we'll follow these three easy steps to create our summary:
from transformers import pipeline
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")Transformers model pipeline should be loaded first. Module in the pipeline is defined by naming the task and the model. The term "summarization" is used, and the model is referred to as "facebook/bart-large-xsum." If we want to attempt something different than the standard news dataset, we can use the Extreme Summary (XSum) dataset. The model was trained to generate one-sentence summaries exclusively.
The last step is constructing an input sequence and putting it through its paces using the summarizer() pipeline. In terms of tokens, the summary length can also be adjusted using the function's optional max_length and min_length arguments.
from transformers import pipeline
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
ARTICLE = """ New York (CNN)When Liana Barrientos was 23 years old, she got married in Westchester County, New York.
A year later, she got married again in Westchester County, but to a different man and without divorcing her first husband.
Only 18 days after that marriage, she got hitched yet again. Then, Barrientos declared "I do" five more times, sometimes only within two weeks of each other.
In 2010, she married once more, this time in the Bronx. In an application for a marriage license, she stated it was her "first and only" marriage.
Barrientos, now 39, is facing two criminal counts of "offering a false instrument for filing in the first degree," referring to her false statements on the
2010 marriage license application, according to court documents.
Prosecutors said the marriages were part of an immigration scam.
On Friday, she pleaded not guilty at State Supreme Court in the Bronx, according to her attorney, Christopher Wright, who declined to comment further.
After leaving court, Barrientos was arrested and charged with theft of service and criminal trespass for allegedly sneaking into the New York subway through an emergency exit, said Detective
Annette Markowski, a police spokeswoman. In total, Barrientos has been married 10 times, with nine of her marriages occurring between 1999 and 2002.
All occurred either in Westchester County, Long Island, New Jersey or the Bronx. She is believed to still be married to four men, and at one time, she was married to eight men at once, prosecutors say.
Prosecutors said the immigration scam involved some of her husbands, who filed for permanent residence status shortly after the marriages.
Any divorces happened only after such filings were approved. It was unclear whether any of the men will be prosecuted.
The case was referred to the Bronx District Attorney\'s Office by Immigration and Customs Enforcement and the Department of Homeland Security\'s
Investigation Division. Seven of the men are from so-called "red-flagged" countries, including Egypt, Turkey, Georgia, Pakistan and Mali.
Her eighth husband, Rashid Rajput, was deported in 2006 to his native Pakistan after an investigation by the Joint Terrorism Task Force.
If convicted, Barrientos faces up to four years in prison. Her next court appearance is scheduled for May 18.
"""
print(summarizer(ARTICLE, max_length=130, min_length=30, do_sample=False))Output:
[{'summary_text': 'Liana Barrientos, 39, is charged with two counts of "offering a false instrument for filing in the first degree" In total, she has been married 10 times, with nine of her marriages occurring between 1999 and 2002. She is believed to still be married to four men.'}]Another option is to use BartTokenizer to generate tokens from text sequences and BartForConditionalGeneration for summarizing.
# Importing the model
from transformers import BartForConditionalGeneration, BartTokenizer, BartConfigAs a pre-trained model, " bart-large-cnn" is optimized for the summary job.
The from_pretrained() function is used to load the model, as seen below.
# Tokenizer and model loading for bart-large-cnn
tokenizer=BartTokenizer.from_pretrained('facebook/bart-large-cnn')
model=BartForConditionalGeneration.from_pretrained('facebook/bart-large-cnn')Assume you have to summarize the same text as in the example above. You can make advantage of the tokenizer's batch_encode_plus() feature for this purpose. When called, this method produces a dictionary that stores the encoded sequence or sequence pair and any other information provided.
How can we restrict the shortest possible sequence that can be returned?
In batch_encode_plus(), set the value of the max_length parameter. To get the ids of the summary output, we feed the input_ids into the model.generate() function.
# Transmitting the encoded inputs to the model.generate() function
inputs = tokenizer.batch_encode_plus([ARTICLE],return_tensors='pt')
summary_ids = model.generate(inputs['input_ids'], num_beams=4, max_length=150, early_stopping=True)The summary of the original text has been generated as a sequence of ids by the model.generate() method. The function model.generate() has many parameters, among which:
- input_ids: The sequence used as a prompt for the generation.
- max_length: The max length of the sequence to be generated. Between min_length and infinity. Default to 20.
- min_length: The min length of the sequence to be generated. Between 0 and infinity. Default to 0.
- num_beams: Number of beams for beam search. Must be between 1 and infinity. 1 means no beam search. Default to 1.
- early_stopping: if set to True beam search is stopped when at least num_beams sentences finished per batch.
The decode() function can be used to transform the ids sequence into plain text.
# Decoding and printing the summary
summary = tokenizer.decode(summary_ids[0], skip_special_tokens=True)
print(summary)The decode() convert a list of lists of token ids into a list of strings. Its accepts several parameters among which we will mention two of them:
- token_ids: List of tokenized input ids.
- skip_special_tokens : Whether or not to remove special tokens in the decoding.
As a result, we get this:
Liana Barrientos, 39, is charged with two counts of offering a false instrument for filing in the first degree. In total, she has been married 10 times, with nine of her marriages occurring between 1999 and 2002. At one time, she was married to eight men at once, prosecutors say.Summarizing Documents with BART using ktrain
ktrain is a Python package that reduces the amount of code required to implement machine learning. Wrapping TensorFlow and other libraries, it aims to make cutting-edge ML models accessible to non-experts while satisfying the needs of experts in the field. With ktrain's streamlined interface, you can handle a wide variety of problems with as little as three or four "commands" or lines of code, regardless of whether the data being worked with is textual, visual, graphical, or tabular.
Using a pretrained BART model from the transformers library, ktrain can summarize text. First, we'll create TransformerSummarizer instance to perform the actual summarizing. (Please note that the installation of PyTorch is necessary to use this function.)
from ktrain.text.summarization import TransformerSummarizer
ts = TransformerSummarizer()Let's go ahead and write up an article:
article = """ Saturn orbiter and Titan atmosphere probe. Cassini is a joint
NASA/ESA project designed to accomplish an exploration of the Saturnian
system with its Cassini Saturn Orbiter and Huygens Titan Probe. Cassini
is scheduled for launch aboard a Titan IV/Centaur in October of 1997.
After gravity assists of Venus, Earth and Jupiter in a VVEJGA
trajectory, the spacecraft will arrive at Saturn in June of 2004. Upon
arrival, the Cassini spacecraft performs several maneuvers to achieve an
orbit around Saturn. Near the end of this initial orbit, the Huygens
Probe separates from the Orbiter and descends through the atmosphere of
Titan. The Orbiter relays the Probe data to Earth for about 3 hours
while the Probe enters and traverses the cloudy atmosphere to the
surface. After the completion of the Probe mission, the Orbiter
continues touring the Saturnian system for three and a half years. Titan
synchronous orbit trajectories will allow about 35 flybys of Titan and
targeted flybys of Iapetus, Dione and Enceladus. The objectives of the
mission are threefold: conduct detailed studies of Saturn's atmosphere,
rings and magnetosphere; conduct close-up studies of Saturn's
satellites, and characterize Titan's atmosphere and surface."""We can now summarize this article by using TransformerSummarizer instance:
ts.summarize(article)Conclusion
Before diving into the BART architecture and training data, this article outlined the challenge BART is trying to answer and the methodology that leads to its outstanding performance. We also looked at a demo inference example using HuggingFace, ktrain and BART's Python implementation. This review of theory and code will give you a great headstart by allowing you to build a powerful Transformer-based seq2seq model in Python.
References
https://huggingface.co/transformers/v2.11.0/model_doc/bart.html
https://arxiv.org/abs/1910.13461
https://www.projectpro.io/article/transformers-bart-model-explained/553
https://github.com/amaiya/ktrain
https://www.machinelearningplus.com/nlp/text-summarization-approaches-nlp-example/








