
Bring this project to life
Data collection is an infrequently talked about topic in the machine learning/deep learning space. While there are a number of preloaded datasets on libraries such as PyTorch and Scikit-Learn, one might need to collect and curate custom datasets for a specific project.
There are a number of ways to go about data collection such as taking readings from data collection instruments or manually recording observations where suitable. In a computer vision context, the low hanging fruit for data collection is scraping pre-existing images from web pages.
In this article, we will be exploring how a simple web scraper is built using the BeautifulSoup library. Using this scraper, we will attempt to collect and curate a custom image dataset for a computer vision project.
The Concept of Web Scraping
Web scraping is the process of extracting data from web pages. Tools used in the web scraping process are called web scrapers (or just scrapers). Technically, the scraper looks through a web page's source code and grabs data according to html tags or some other means. In the Python ecosystem, there are numerous libraries that can be used for web scraping such as BeautifulSoup, Selenium and Scrapy. However, in this article, we shall be focusing on building scrapers using BeautifulSoup.
Web Scraping Ethics
A lot has been made of the whole process of web scraping and its overall legality. In fact, its been so contentious that there have been actual court cases centered on the subject matter.
In a ruling by the US Ninth Circuit of Appeals, it was reaffirmed that scraping publicly accessible data on the internet is not a violation of the CFAA (Computer Fraud and Abuse Act). Essentially, what that means is that scraping information which is publicly displayed to everyone visiting a web page is legal, however, scraping private data would be deemed illegal.
That being said, websites could as well, for their personal reasons, prefer to prevent web scraping entirely. A neat way to check if scraping is allowed on a particular web page is to check its robots.txt file. A robots.txt file provides information to web crawlers (eg Google, Bing) on which folders they are allowed to access and display in search results, scrapers basically piggyback on this as a sort of permission document.
Consider the web page above, to access its robot.txt file all that needs to be done is to add '/robots.txt' to the web page's address bar as seen below.

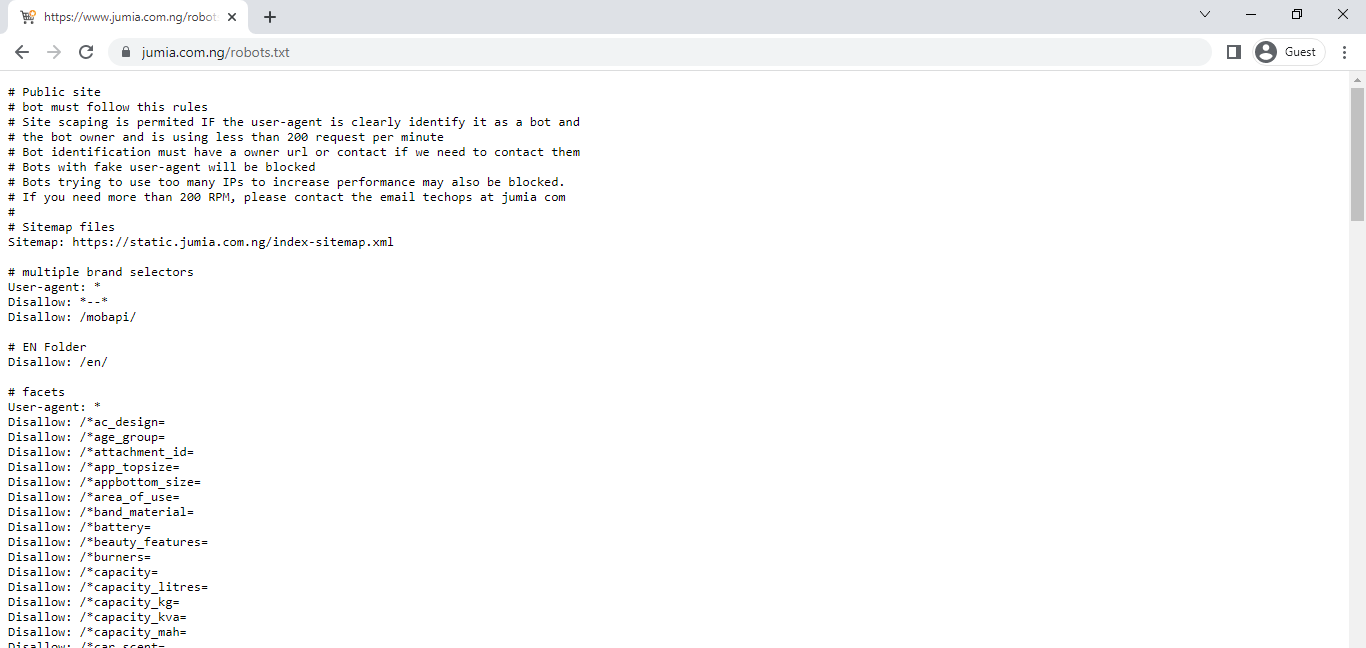
When that is done, all that's left is to hit the enter key and the robots.txt file for the page will be displayed as illustrated below. From the file, it is quite evident that this particular website does not frown at web scraping albeit some restrictions are placed. Bare in mind that not all robots.txt files are this detailed as regards a website's attitude towards scraping. One thing to look out for are the 'Disallow' arguments in the file, websites that list multiple 'Disallow' arguments only disallow scraping in select folders (those listed). A website that restricts scraping in its entirety will have an argument such as 'Disallow: /' and if there is full scraping access, then it'll simply be 'Disallow: '.
After all is said and done, websites could still prevent bots (scrapers) from accessing their web pages. If you however decided to go ahead and scrape data from these kind of pages (there are ways around anti-scraper tech), ensure that you remain ethical and refrain from overloading their servers with requests.
BeautifulSoup & HTML Parsing
Parsing is the process of separating strings into their constituent components so as to allow for easy analysis. This is essentially what the BeautifulSoup library does as it pulls a web page's html and 'separates' them based on their tags so they can be accessed and analyzed separately.
Consider the sample html below, it is made up of strings enclosed in tags such as html, title, body, h1 and p. If this html is supplied as an argument in beautifulsoup, we will be able to access each tag individually and do whatever we want with the strings that they hold.
<html>
<title>Mock Webpage</title>
<body>
<h1>Web Scraping</h1>
<p>This article is all about web scraping</p>
<p>We will be using BeautifulSoup</p>
</body>
</html>Attempting to create a beautifulsoup element from the html above, for the sake of simplicity copy the html, format them as Python strings (by putting them in quotes) and create an object as seen below. Next, create a beautifulsoup element using the 'html.parser' argument.
# article dependacies
from bs4 import BeautifulSoup
from urllib.request import urlopen
from urllib.request import Request
from tqdm import tqdm
import requests
import os
import timefrom bs4 import BeautifulSoup
# create html object
html = """
<html>
<title>Mock Webpage</title>
<body>
<h1>Web Scraping</h1>
<p>This article is all about web scraping</p>
<p>We will be using BeautifulSoup</p>
</body>
</html>
"""
# create beautifulsoup element
bs = BeautifulSoup(html, 'html.parser')Now that a beautifulsoup element has been produced, we can simply call tags as attributes of the element so as to access them. A couple of attribute calls are made below.
# extract the title tag
bs.title
>>>> <title>Mock Webpage</title># extract the h1 tag
bs.h1
>>>> <h1>Web Scraping</h1># extract the p tag
bs.p
# notice that just the first tag is returned
>>>> <p>This article is all about web scraping</p># extract all p tags
bs.find_all(p)
>>>> [<p>This article is all about web scraping</p>,
<p>We will be using BeautifulSoup</p>]# extract only the string in the title tag
bs.title.get_text()
>>>> Mock WebpageBeautifulSoup & Web Page Scraping
From the previous section we know that if we get html into beautifulsoup in a suitable format we can begin to extract information from it. When it comes to actual web pages hosted on servers, we need to find a way to actually access their html in a Python environment. To do that we need to use the urllib library in tandem with beautifulsoup.
from urllib.request import urlopen
from urllib.request import Request
url = 'actual link'
# header to mimick web browser
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Charset': 'ISO-8859-1,utf-8;q=0.7,*;q=0.3',
'Accept-Encoding': 'none',
'Accept-Language': 'en-US,en;q=0.8',
'Connection': 'keep-alive'}
# make request to server
request = Request(url, headers=headers)
# open request and create beautifulsoup element
html = urlopen(request)
bs = BeautifulSoup(html.read(), 'html.parser')From the code block above, we have imported both the urlopen function and the Request method from urllib. Firstly, we make a request to the server where the web page is hosted using the Request method. Notice that we have specified new headers for our request, this is done to provide the illusion that an actual web browser is making that request to the server (this is simply one of the basic methods of avoiding anti-scrapers).
Lastly, we simply open the response gotten from the server (housed in the request object) using the urlopen function then create a beautifulsoup element as we did in the previous section. The 'read()' attribute is used on the html object so as to allow beautifulsoup to access its contents as it is not in string format.
Scraping Images off a Web page
Bring this project to life
Scraping Images
Using all of the knowledge we have accrued up till this point, we can now attempt to scrape images off a web page. Images are usually domiciled in 'src' links, or some variation of them, housed in 'img' tags in html. Every single image on a web page will be tagged the same way, in order to extract only images of interest, we need to differentiate them somehow. For demonstration purposes, let's use the e-commerce website Jumia.
Assume that we would like to build a binary classification model capable of distinguishing between men's athletic shoes and boots. Navigating to any of the linked pages, right clicking and then clicking on inspect reveals the page's html (personally used Google Chrome in this instance).
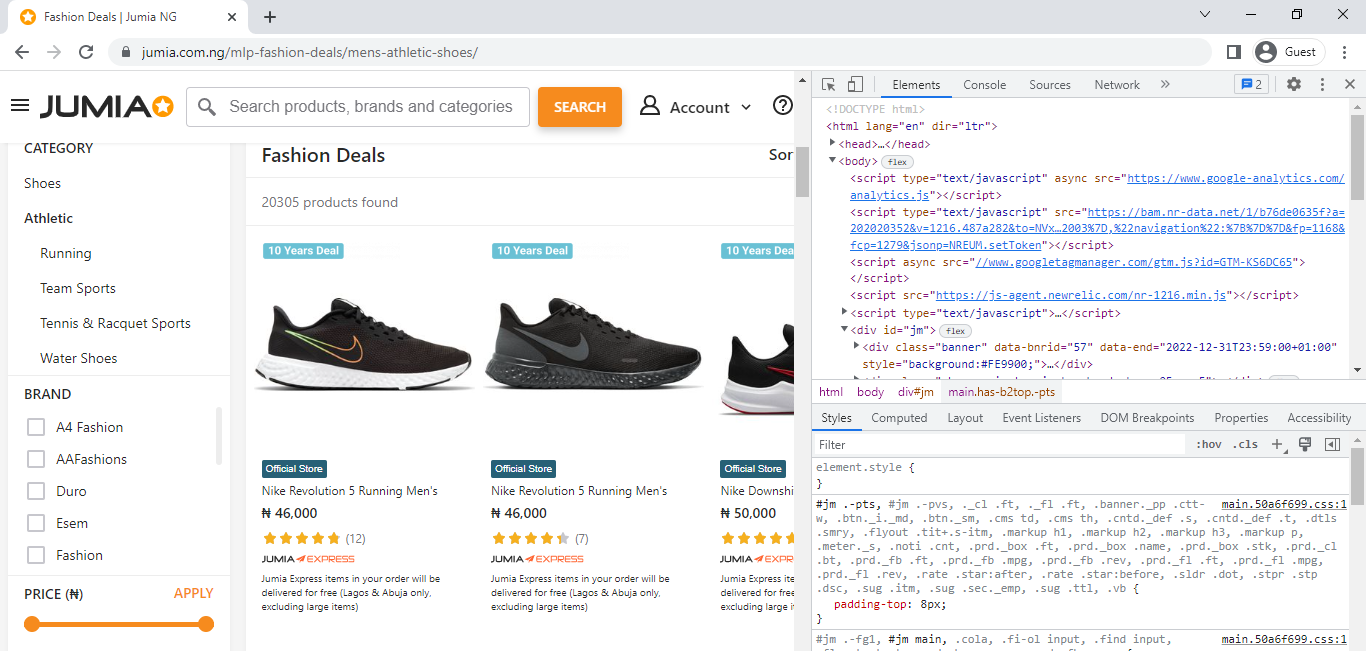
Tags and Attributes
Right clicking on the images in the shoe catalog listing reveals that they are all housed in 'img' tags and the images themselves can be found in data-src links. One more thing to note is that they all have the same class attribute (class = "img"). Inspecting other images not in the listing reveals that they have different class attributes.
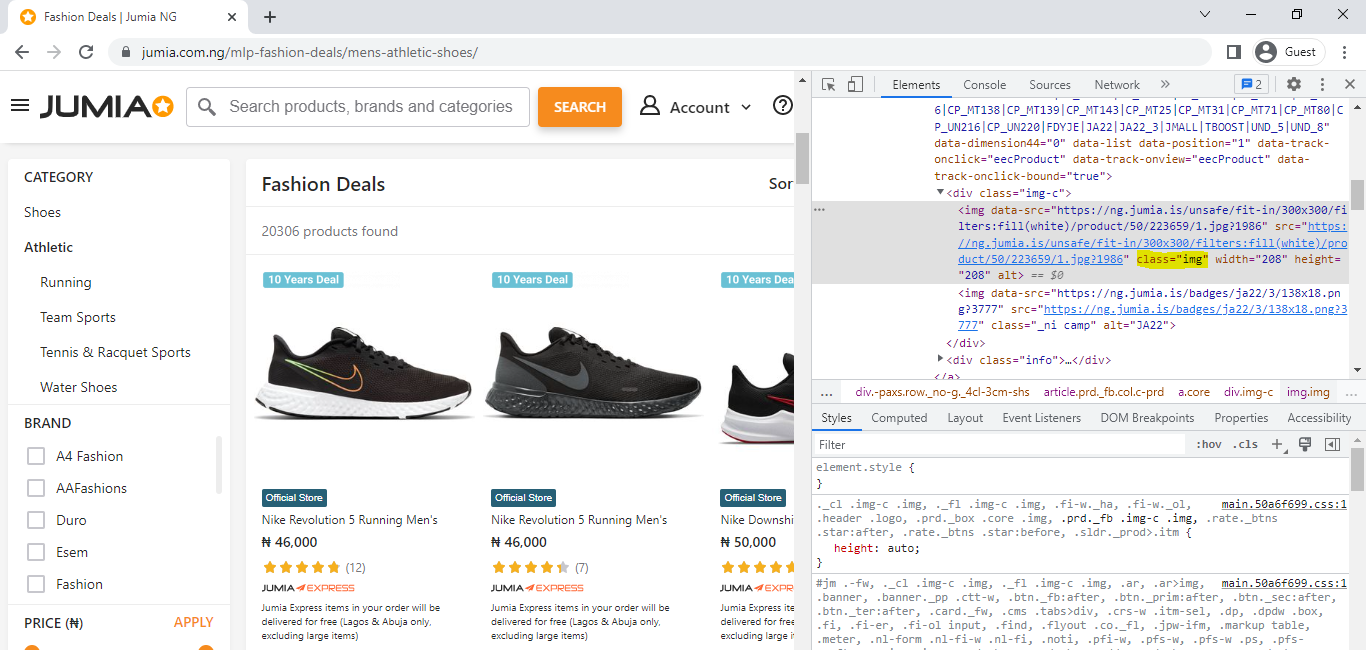
This massively simplifies our task. All we need to do is to parse this page using beautifulsoup then extract all img tags which have the "img" class. To do this we can simply replicate the code from the previous section on scraping web pages but this time we will use a real url. In order to scrape multiple pages, navigate to page 2 and copy the url, you'll notice that the page number is specified, all we need to do is to modify this in someway so that we can iterate through multiple pages.
# copy link from page 2 and edit 2 to 1 to access the first page
url = 'https://www.jumia.com.ng/mlp-fashion-deals/mens-athletic-shoes/?page=1#catalog-listing'
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Charset': 'ISO-8859-1,utf-8;q=0.7,*;q=0.3',
'Accept-Encoding': 'none',
'Accept-Language': 'en-US,en;q=0.8',
'Connection': 'keep-alive'}
request = Request(url, headers=headers)
html = urlopen(request)
bs = BeautifulSoup(html.read(), 'html.parser')
# extract all img tags with class img
interest = bs.find_all('img', attrs={'class':'img'})We now have all the catalog images in the object "interest". In order to extract the data-src links, all we need to do is to call the data-src attribute on each item in the list.
# extracting links using list comprehension
links = [listing['data-src'] for listing in interest]Downloading from src Links
Using the extracted links, we can now attempt to extract the images present in them using the requests library.
import requests
# instantiating counter
count = 0
# downloading images
for link in tqdm(links):
with open(f'athletic_{count}.jpg', 'wb') as f:
response = requests.get(link)
image = response.content
f.write(image)
count+=1Building a Web Scraper
Putting everything we know about web scraping at this point together, we can now build a scraper which will do all the above outlined steps automatically. For our scraper, we will create a Python class with methods to replicate the scraping processes as discussed previously.
class WebScraper():
def __init__(self, headers, tag: str, attribute: dict,
src_attribute: str, filepath: str, count=0):
self.headers = headers
self.tag = tag
self.attribute = attribute
self.src_attribute = src_attribute
self.filepath = filepath
self.count = count
self.bs = []
self.interest = []
def __str__(self):
display = f""" CLASS ATTRIBUTES
headers: headers used so as to mimic requests coming from web browsers.
tag: html tags intended for scraping.
attribute: attributes of the html tags of interest.
filepath: path ending with filenames to use when scraping images.
count: numerical suffix to differentiate files in the same folder.
bs: a list of each page's beautifulsoup elements.
interest: a list of each page's image links."""
return display
def __repr__(self):
display = f""" CLASS ATTRIBUTES
headers: {self.headers}
tag: {self.tag}
attribute: {self.attribute}
filepath: {self.filepath}
count: {self.count}
bs: {self.bs}
interest: {self.interest}"""
return display
def parse_html(self, url):
"""
This method requests the webpage from the server and
returns a beautifulsoup element
"""
try:
request = Request(url, headers=self.headers)
html = urlopen(request)
bs = BeautifulSoup(html.read(), 'html.parser')
self.bs.append(bs)
except Exception as e:
print(f'problem with webpage\n{e}')
pass
def extract_src(self):
"""
This method extracts tags of interest from the webpage's
html
"""
# extracting tag of interest
interest = self.bs[-1].find_all(self.tag, attrs=self.attribute)
interest = [listing[self.src_attribute] for listing in interest]
self.interest.append(interest)
pass
def scrape_images(self):
"""
This method grabs images located in the src links and
saves them as required
"""
for link in tqdm(self.interest[-1]):
try:
with open(f'{self.filepath}_{self.count}.jpg', 'wb') as f:
response = requests.get(link)
image = response.content
f.write(image)
self.count+=1
# pausing scraping for 0.4secs so as to not exceed 200 requests per minute as stipulated in the web page's robots.txt file
time.sleep(0.4)
except Exception as e:
print(f'problem with image\n{e}')
time.sleep(0.4)
passMethods in the web scraper class above handle exceptions using try/except blocks. This is done so as to guide against exceptions raised due to broken links or missing files which are prevalent on the web. Now that the web scraper has been defined, lets instantiate an object named 'scraper' which will be a member of that class.
# instantiating web scraper class
scraper = WebScraper(headers=headers, tag='img', attribute = {'class':'img'},
src_attribute='data-src', filepath='shoes/athletic/atl', count=0)As it is, the scraper object defined above can only scrape one page/url at a time. In a bid to make it more robust and allow it to scrape multiple pages, we need to wrap it in a function which will allow it to iterate through several pages. For the function to work, we need to copy the url from any page other than page 1 then format it as an f string as seen in the code block below. The reason for doing this is so we have access to the page reference embedded in the url.
def my_scraper(scraper, page_range: list):
"""
This function wraps around the web scraper class allowing it to scrape
multiple pages. The argument page_range takes both a list of two elements
to define a range of pages or a list of one element to define a single page.
"""
if len(page_range) > 1:
for i in range(page_range[0], page_range[1] + 1):
scraper.parse_html(url=f'https://www.jumia.com.ng/mlp-fashion-deals/mens-athletic-shoes/?page={i}#catalog-listing')
scraper.extract_src()
scraper.scrape_images()
print(f'\npage {i} done.')
print('All Done!')
else:
scraper.parse_html(url=f'https://www.jumia.com.ng/mlp-fashion-deals/mens-athletic-shoes/?page={page_range[0]}#catalog-listing')
scraper.extract_src()
scraper.scrape_images()
print('\nAll Done!')
passWith everything setup, we can now go ahead to scrape images from the first five pages using the code below. The cool thing about the way we have set up our scraper is that one could easily access src links on a page by page basis simply by calling 'scraper.interest' which will return a nested list, with each internal list containing each page's src links. On your own, you can attempt to scrape the first five pages from the boots listing as well.
import os
# creating directory to hold images
os.mkdir('shoes')
os.mkdir('shoes/athletic')
# scraping the first five pages
my_scraper(scraper=scraper, page_range=[1, 5])Downsides of using BeautifulSoup
As evident from the previous sections, BeautifulSoup is a powerful web scraping tool. However, the one downside it has is the fact that it is not always sufficient for scraping dynamic web pages. Think of dynamic web pages as pages where clicking buttons display more content on the same page. For those kind of pages, the Selenium library is a safe bet.
Final Remarks
In this article, we explored the concept of web scraping in general. We then focused on scraping images using the BeautifulSoup library. Using the knowledge we had accrued, we proceeded to build a web scraper capable of scraping images from several pages in one go.
Essentially, the same process would apply if one intends to scrape non-image data from pages as well, as long as tags and attributes of interests are identified from a page's html, a scraper to scrape any kind of desired data can be built.











