
SciSpace (formerly known as Typeset) is a software company making scientific research more collaborative and accessible.
In addition to providing valuable tools for researchers to trace the lineage of scientific articles, SciSpace is an end-to-end integrated research platform with modern workflows to help scholars write and publish research effortlessly.
We were excited to get the chance to sit down with Rohan Tondulkar, a Senior Research Scientist at SciSpace, to dive into some of the machine learning work his team is undertaking.
Let’s get started!
Paperspace: SciSpace is a platform for researchers and publishers. To help our readers understand the product a little bit better, can you tell us about some common use cases for your users?
Tondulkar: The idea behind SciSpace is to bring every stakeholder in the research ecosystem — readers, researchers, professors, publishers, and universities — under one roof and to provide them with an interconnected suite of applications to make scientific knowledge and data flow together seamlessly.
Science enthusiasts and researchers rely on our Discover module to search, access, and read scientific manuscripts. We have over 270 million research papers from across domains on our platform. Combined with powerful search filters and personalized recommendations, we make literature search significantly more straightforward and quicker.
Besides that, students and researchers use our Write solution to create, edit, proofread, typeset, and format their manuscripts. We offer 30,000+ journal templates, enabling researchers to format their manuscripts according to the latest journal guidelines within seconds.
Publishers use our built-in OJS module and automated XML-first production workflows to simplify the production process and improve the visibility of their articles.
Paperspace: One of the daunting things about working with scientific literature is that the corpus is … expansive, to say the least. What kind of scale are we really talking about? What kind of datasets do you get to work with on a daily basis?
Tondulkar: We deal with massive datasets daily. We allow users to search 270 million research articles along with metadata for each, such as references, citations, etc. and the total runs into billions of data points. We have nearly 50 million Open Access PDFs that must be processed for every task. Every feature we develop has to cater to this huge data.
Paperspace: Your job title is Senior Research Scientist – can you tell us a little more about what you do? What kinds of challenges is your team tackling, and how does that fit into the wider mission of the company?
Tondulkar: We have a small ML Research team of six led by Dr. Tirthankar Ghosal, a Ph.D. from IIT Patna and an expert in scholarly document processing. The team was built to explore and deploy various NLP features for enhancing the discoverability and making it easier to digest scientific articles. The research community is then able to get more value from these papers and connect the dots faster.
As a Senior Research Scientist, I have a broader role that covers an end-to-end ML stack. My responsibilities include researching and experimenting on various problem statements, coordinating work within the team, setting up deployment pipelines, resolving scalability issues, quality checking model outputs, and making services available for our models.
Our team works on many unique and interesting problems, including generating extractive and abstractive summaries of research articles. We also build semantic search tools, recommendation systems, and perform large-scale citation analysis. And there's a lot more in the pipeline!
Paperspace: As a GPU cloud provider we notice a large amount of interest in NLP use cases and applications. What can you tell us about using accelerated GPU compute to train NLP models?
Tondulkar: Since the advent of GPUs for machine learning use cases, we have also seen a surge in innovation in NLP. It has only increased in recent years with the ease of availability of GPUs during training and deployment. Various GPU providers like Paperspace, AWS, and Google Cloud, to name a few, have played an essential role in helping researchers get their models trained and deployed at a super fast pace.
While more powerful GPUs are being developed, the NLP models (e.g. GPT-3) are also growing in size and performance. The availability of GPUs at a low cost makes it easier than ever for big and small companies to use and develop top-performing models. This has already helped grow various startups based on AI/NLP and has immense future potential as we see more and more use cases and problem statements being solved by ML.

“Our team needs to perform experiments on various problem statements. This involves training large deep learning models using PyTorch, TensorFlow, Hugging Face, etc. on millions of data points. So we needed a platform that could scale to multiple users and projects. We explored numerous options to suit us best to perform the experiments — Paperspace, Google Colab, AWS Sagemaker, and Vast.ai.
We found that Paperspace was the most convenient and cost-efficient option for us as researchers. The fact that Paperspace provides more control by allowing the selection of GPU/CPU machines combined with on-demand use of GPUs helped significantly optimize the cost.”
Rohan Tondulkar, Senior Research Scientist, SciSpace
Paperspace: How does Paperspace come into the picture? Is there a particular reason that your team started working with Paperspace machines?
Tondulkar: Our team needs to perform experiments on various problem statements. This involves training large deep learning models using PyTorch, TensorFlow, Hugging Face, etc. on millions of data points. So we needed a platform that could scale to multiple users and projects. We explored numerous options to suit us best to perform the experiments — Paperspace, Google Colab, AWS Sagemaker, and Vast.ai.
We found that Paperspace was the most convenient and cost-efficient option for us as researchers. The fact that Paperspace provides more control by allowing the selection of GPU/CPU machines combined with on-demand use of GPUs helped significantly optimize the cost.
Other features like creating datasets and integrating with Git have been beneficial to us. We have found the environment in Paperspace to be stable and easy to set up. Thanks to Paperspace, we can perform these experiments reliably and systematically.
Paperspace: What are some of the unexpected or expected challenges that your team has when it comes to building production-scale ML applications?
Tondulkar: One of our biggest challenges is to get good datasets to train our models. As we operate in a niche space, very few suitable datasets are publicly available. Also, our models must perform equally well on research articles from various domains — AI, mathematics, physics, chemistry, medicine, and others, which is a very challenging task. The models go through rigorous quality checks to ensure this.
Generating output from big ML models can be a bit time-consuming. It is a big challenge to generate output for millions of research articles quickly and cost-effectively.
Paperspace: If our readers would like to check out SciSpace and get involved with the community, how would you recommend they start?
Tondulkar: Feel free to visit our website, typeset.io (we were formerly known as Typeset.io). From there you can learn all about our offerings. And if you'd like to read some of the latest research on your favorite research topics, you can start on the Topics page. So far we have around 50 million full-text PDFs available on the platform.
You can follow us on Twitter at @Scispace_. We regularly share curated lists of trending research papers, summaries of trailblazing articles, research writing and publishing best practices, and actively interact with our community of researchers and professors. You can also check out our LinkedIn page to learn more about our work culture, future plans, and other initiatives.
Paperspace: Anything else you’d like to give a shout-out to?
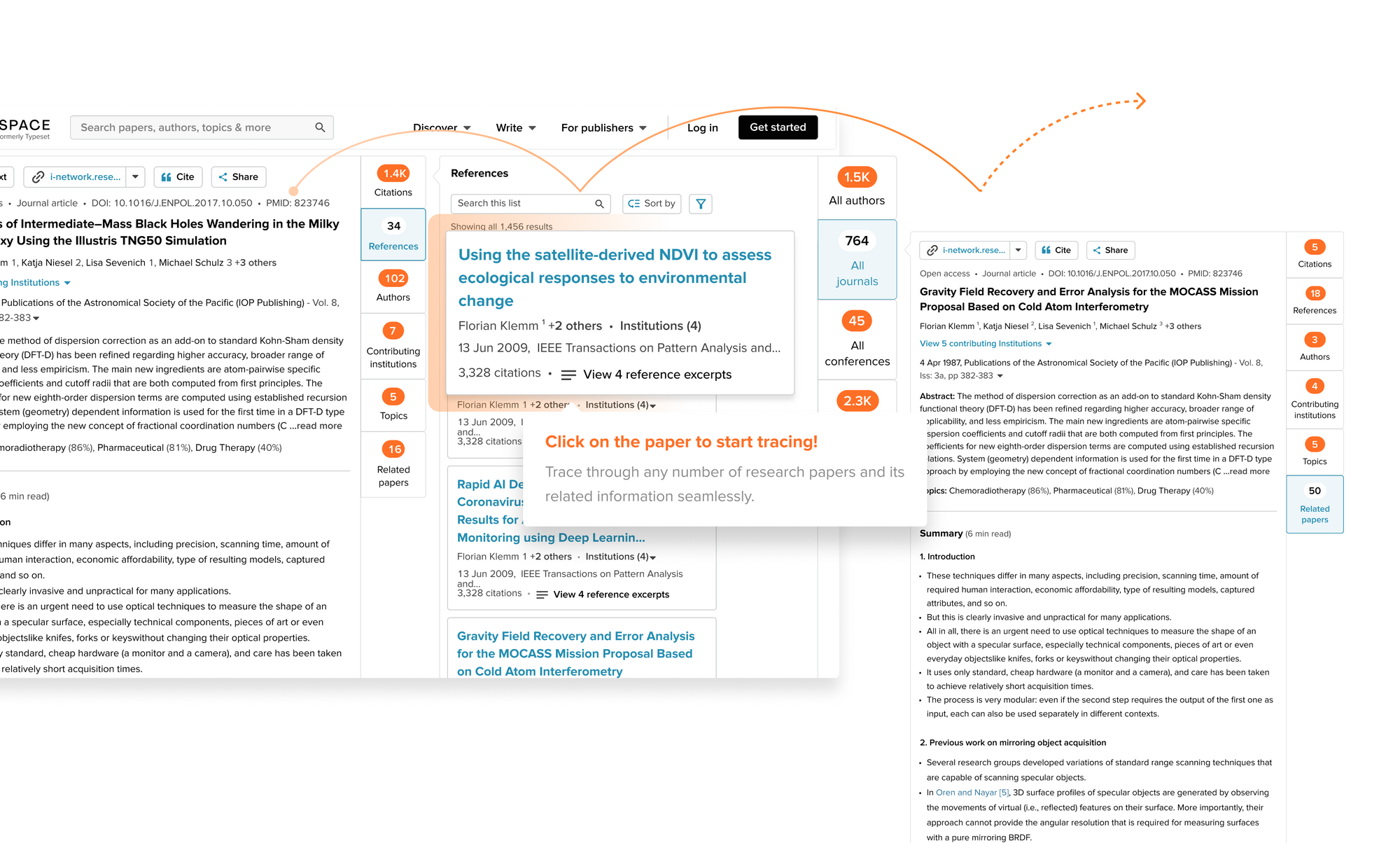
Tondulkar: Be sure to check out our Trace feature. Trace is a new addition to our paper discovery engine that is intuitive and unique in the industry. You'll be able to delve deep into a topic without losing track of your progress. Try it out here on a recent article covering BERT!
For more information on SciSpace, be sure to check out https://typeset.io/.











