
Bring this project to life
Machine learning models cannot handle categorical variables. Therefore, if the dataset contains categorical variables, we need to convert them to numeric variables. There are various ways to convert categorical values to numbers. Each approach has its own tradeoffs and implications for the feature set. Often, this encoding process makes use of the data engineering technique hot encoding using dummy variables. Let’s look at this technique in greater detail.
In this article we will learn about One-hot encoding with examples, its implementation and how to handle multi categorical data using One-hot encoding. We will also learn the difference between One-hot encoding and label encoding.
What is One-hot Encoding?
The process of converting categorical data (having data represented by different categories) into numerical data (i.e 0 and 1) is called One-hot Encoding. There is often a need to convert the categorical data into numeric data, so we can use One-hot Encoding as a possible solution. Categorical data is converted into numeric data by splitting the column into multiple columns. The numbers are replaced by 1s and 0s, depending on which column has what value. In each column, which will be titled with the convention “is_<color>”, the values for each row will be binary representations of whether that color characterization is present in the fruit.
For example, here we have a dataset in which we have one column ‘Fruit’, which contains categorical data.
Original dataset:
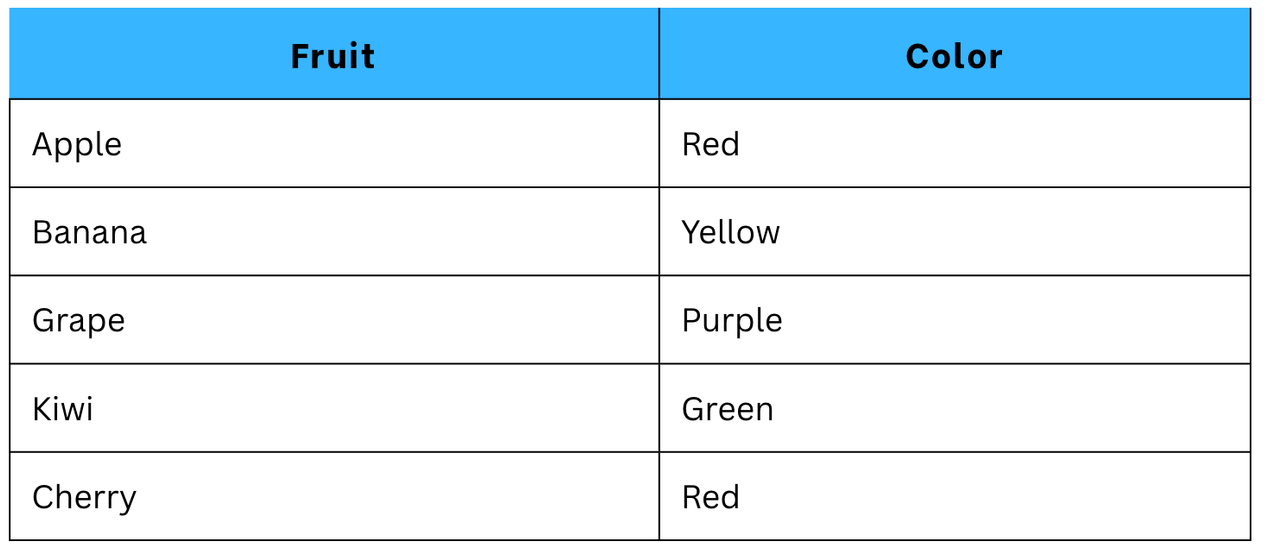
Here we have our original dataset. To get it in numerical format, we have to convert it by applying One-hot Encoding technique. There, 4 more columns will be added in the dataset. This is because 4 categories of labels are there.
After One-hot Encoding:
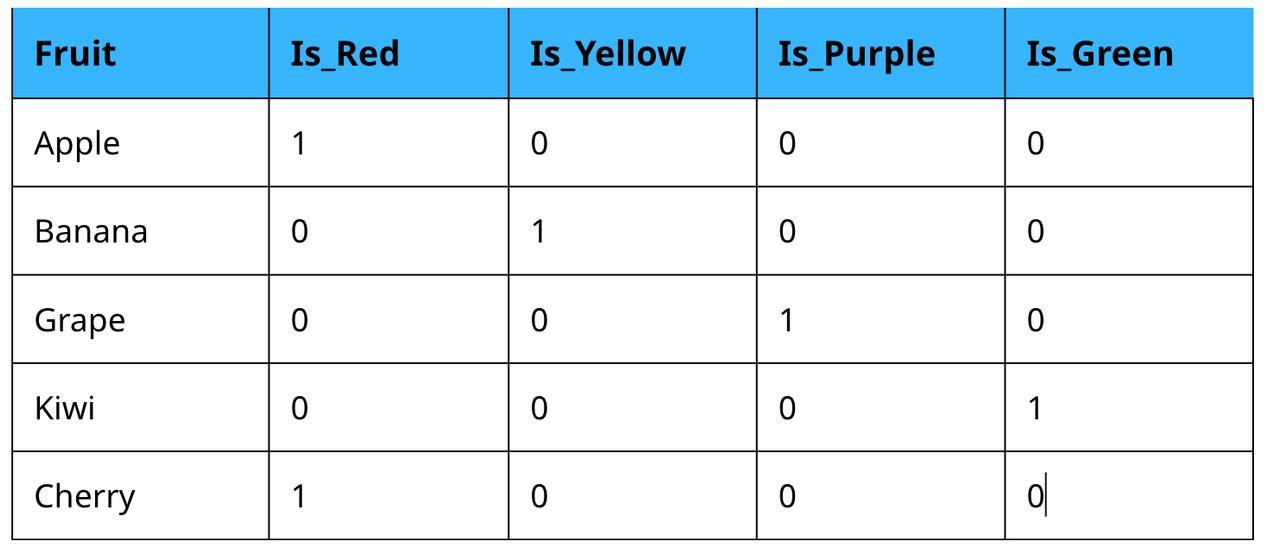
What is Label Encoding?
Till now we have seen how to handle categorical data. But what if our labeled data have some order? And what if there are many categorical labels in the dataset?
Label encoding is the process of converting categorical features into numerical features(i.e 0, 1, 2, 3, etc). Label encoding involves converting each value in a column to a number. Lets look at an example:
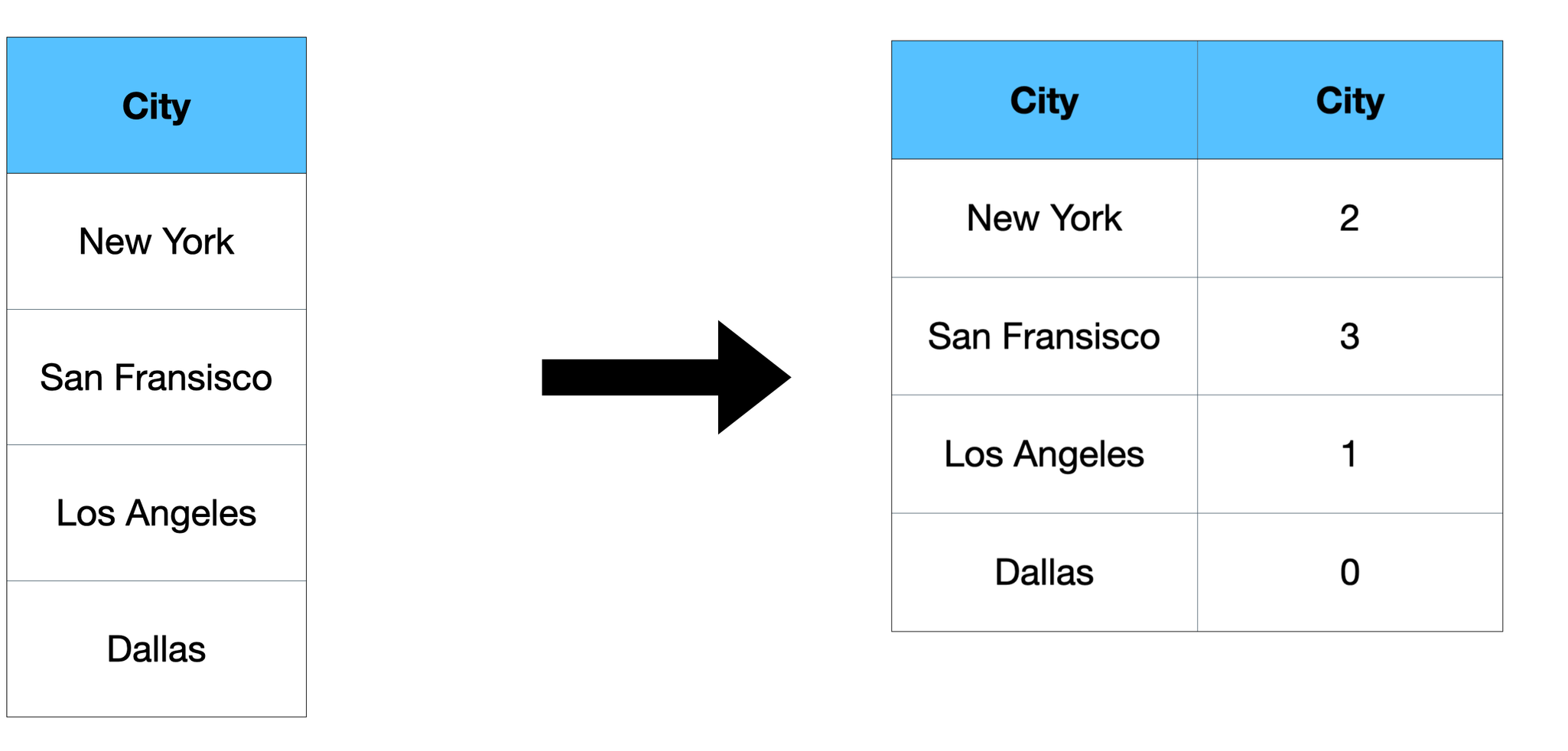
So different numbers are assigned to different city names unlike a separate column for each city as we did in One-hot Encoding.
Therefore in situations like the example above, we can consider using techniques such as label encoding, which can help reduce the number of labels while preserving the essential information in the categorical data. We will now look at what label encoding is.
Difference between One-hot encoding and Label Encoding
Aspect | One-hot Encoding | Label Encoding |
|---|---|---|
Representation | Represents categorical variables using binary vectors, i.e. 0 and 1. | Represents categorical variables by assigning a unique integer to each category. |
Number of columns | Increases dimensionality with binary columns. The number of columns equals the number of unique categories. | Results in a single column of integers. Each integer represents a different category. |
Ordinal information | Each category is treated as independent, and no inherent order is imposed. | The assigned integer values carry a meaningful order, indicating the relative positioning of categories. |
Model sensitivity | One-hot encoding is particularly advantageous for models that can efficiently handle high-dimensional data. Examples of such models include decision trees, random forests, and deep learning models | Label encoding is suitable for algorithms, like decision trees or linear regression, that can naturally interpret and utilize the ordinal information encoded in integers. |
When to use One-hot encoding and Label Encoding?
The data coding method is selected accordingly. For example, in the example above, we encoded various state names into numeric data. This categorical data has no relationship between rows. Then we can use Label encoding.
Label encoders are used when:
- One-hot encoding can be memory intensive, so use this technique when the number of categories can be very large.
- Order does not matter for categorical functions.
One-hot encoders are used when:
- For categorical features, when label order is not important.
- Number of labels is less. As for each label, there will be a separate column.
- Preventing machine learning models from incorrectly assuming an order among categorical features.
Dummy Variable Trap
The Dummy Variable Trap occurs when different input variables perfectly predict each other – leading to multicollinearity.
Multicollinearity occurs when two or more independent variables in a regression model are highly correlated. As we have seen in the above example, for every label we will have a separate column. These newly created binary features are called dummy variables. This is also called dummy encoding. The number of dummy variables is determined by the number of categories present. It may sound a little complicated. But don't worry, we’ll explain it with an example.
Let's say we have a dataset in the "Country" category that also includes various countries such as India, Australia, Russia, and America. Within those, we have three labels/categories in the ‘Town’ column, so we will have three columns for three different dummy variables. These columns are ‘monroe township’, ‘robinsville’, ‘west windsor’.
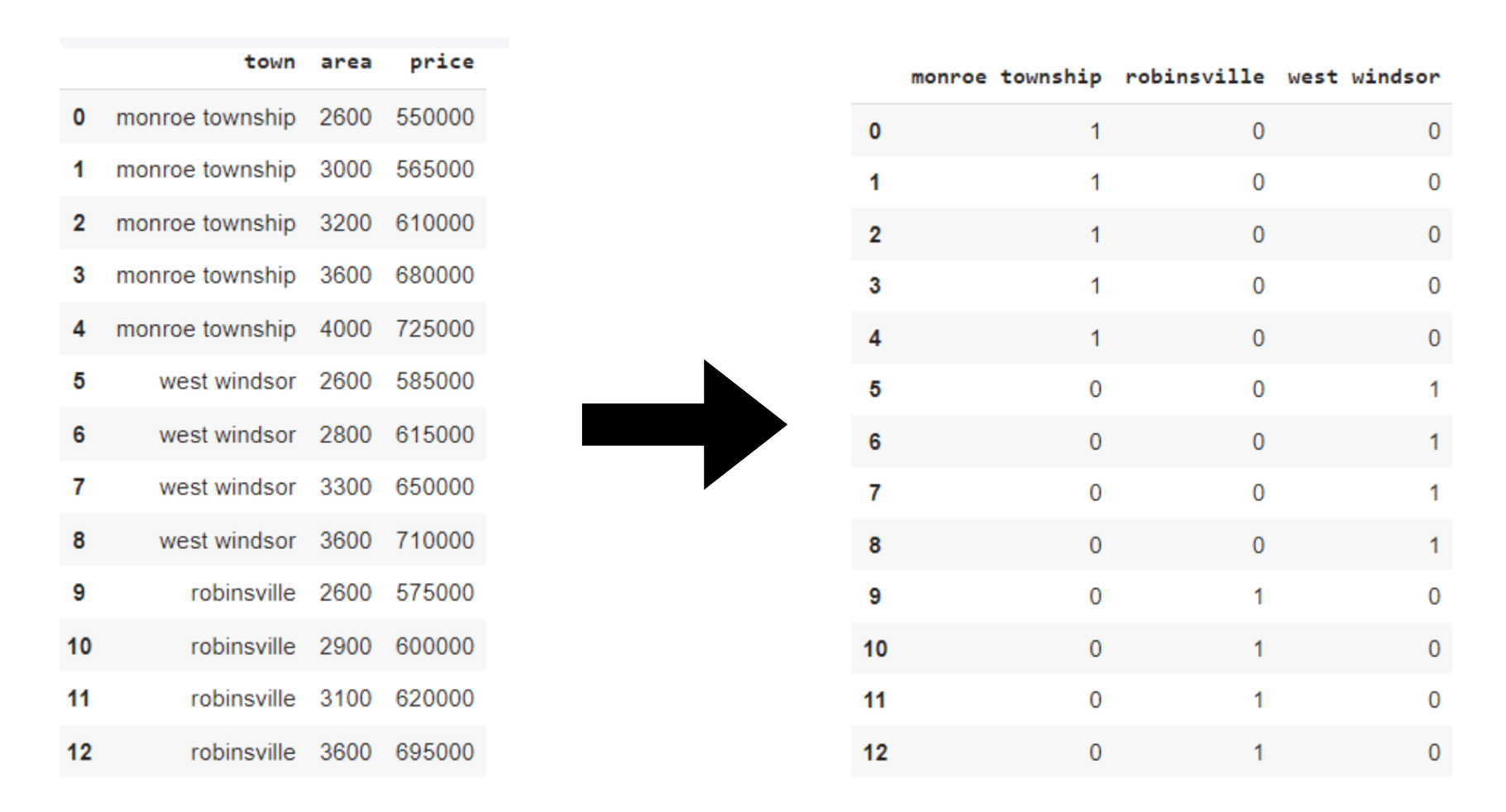
Then merge these three columns with the original dataset. As we have different dummy features representing the same information as the ‘town’ column, so to remove redundancy, we can drop the ‘town’ column.
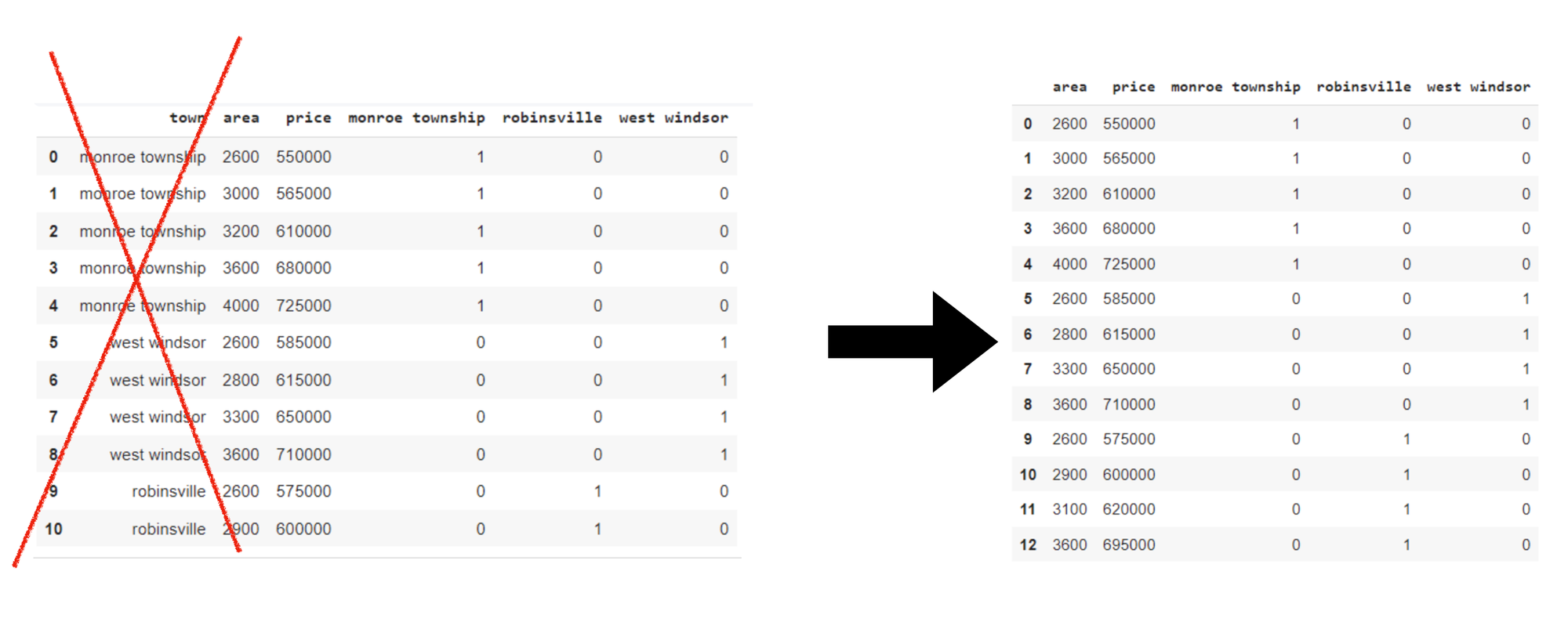
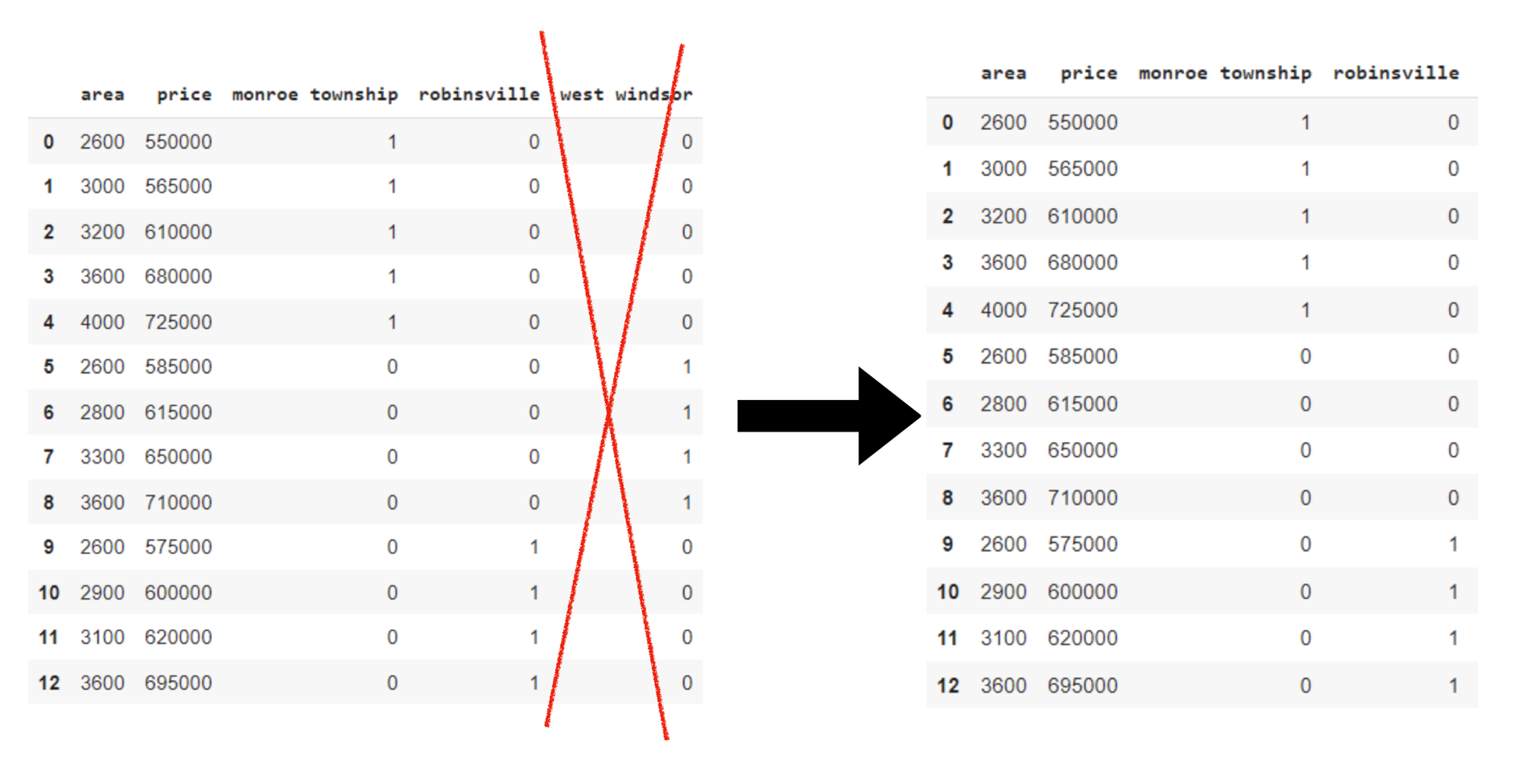
In this example, certain columns can introduce issues with creating dummy variables. This can be called a dummy variable trap. To avoid a dummy variable trap, we drop the ‘west windsor’ column here. This is done to prevent multicollinearity. Will dropping columns lead to significant information loss? The answer is usually NO. Even if we have deleted ‘west windsor’. We can still get the information about it from the remaining variables.
Let's now implement the example above example. Suppose we want to predict the house price. We are using the ‘home price.csv’ dataset (available on Github) in which ‘Town’ is a categorical feature, which we have to convert to a numerical feature/variable.
import pandas as pd
df = pd.read_csv("home price.csv") # loading the dataset
dummies = pd.get_dummies(df.town)
merged = pd.concat([df,dummies],axis=1) # merging dummy variable
final = merged.drop(['town'], axis=1) # merging the ‘Town’ column
final = final.drop(['west windsor’], axis=1) # dropping anyone dummy variable.Here dropping ‘west windsor’Explanation: Dummy variables for the town column is created. Then, dummy variable columns are added to the end of your original DataFrame. To avoid multicollinearity, one of the dummy variable columns, 'west windsor' is dropped.
How One-hot Encoding handles Multi-categorical data?
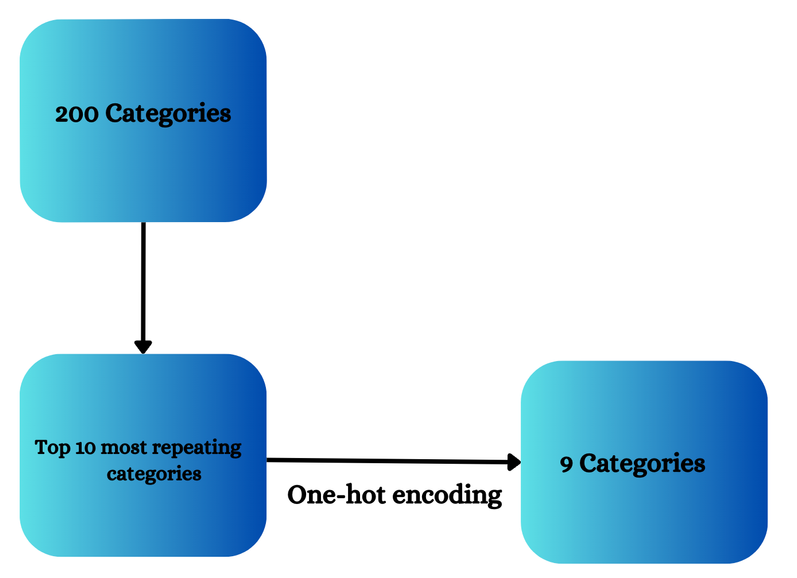
Does One-hot encoding handle multi-labeled data? The answer is YES. Now we will see how. Suppose 200 categories are present in a feature then only those 10 categories which are the top 10 repeating categories will be chosen and one-hot encoding is applied to only those categories.
After applying One-hot encoding we will delete one column to prevent dummy variable trapping and will have 9 categories.
Now we will see this can be implemented with a practical example. We have taken mercedesbenz.csv (available on Github). We have chosen this dataset as it contains multiple categories.
import pandas as pd
import numpy as np
df = pd.read_csv('mercedesbenz.csv', usecols=['X1', 'X2'])
df.head()
counts = df['X1'].value_counts().sum() # Counting number of labels for ‘X1’ column
top_10_labels = [y for y in df.X1.value_counts().sort_values(ascending=False).head(10).index] # checking the top 10 labels
df.X1.value_counts().sort_values(ascending=False).head(10) # arranging the labels in ascending order
df=pd.get_dummies(df['X1']).sample(10) #applying One-hot encodingExplanation: In this X1 and X2 columns contain multiple labels.So first we will check the number of labels and how many times they are repeating. Arrange them in ascending order and then apply One-hot encoding.
Challenge!
Assignment: Try converting the other categorical features of X2 column to numerical features using one-hot encoding (I only converted X1 column features). Try implementing chosen algorithm and check its prediction accuracy.
Demo
Bring this project to life
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
# Read the dataset
df = pd.read_csv("home price.csv")
# One-Hot Encoding
dummies = pd.get_dummies(df['town'])
merged_one_hot = pd.concat([df, dummies], axis=1)
final_one_hot = merged_one_hot.drop(['town'], axis=1)
final_one_hot = final_one_hot.drop(['robinsville'], axis=1)
# Label Encoding
label_encoder = LabelEncoder()
df['town_encoded'] = label_encoder.fit_transform(df['town'])
final_label_encoded = df.drop(['town'], axis=1)
# Separate features and target for One-Hot Encoding
X_one_hot = final_one_hot.drop('price', axis=1)
y_one_hot = final_one_hot['price']
# Separate features and target for Label Encoding
X_label_encoded = final_label_encoded.drop('price', axis=1)
y_label_encoded = final_label_encoded['price']
# Split the data into train and test sets for One-Hot Encoding
X_train_one_hot, X_test_one_hot, y_train_one_hot, y_test_one_hot = train_test_split(X_one_hot, y_one_hot, test_size=0.2, random_state=42)
# Split the data into train and test sets for Label Encoding
X_train_label_encoded, X_test_label_encoded, y_train_label_encoded, y_test_label_encoded = train_test_split(X_label_encoded, y_label_encoded, test_size=0.2, random_state=42)
# Model using One-Hot Encoded data
model_one_hot = LinearRegression()
model_one_hot.fit(X_train_one_hot, y_train_one_hot)
predictions_one_hot = model_one_hot.predict(X_test_one_hot)
score_one_hot = r2_score(y_test_one_hot, predictions_one_hot)
# Model using Label Encoded data
model_label_encoded = LinearRegression()
model_label_encoded.fit(X_train_label_encoded, y_train_label_encoded)
predictions_label_encoded = model_label_encoded.predict(X_test_label_encoded)
score_label_encoded = r2_score(y_test_label_encoded, predictions_label_encoded)
# Compare results
print("R-squared score for One-Hot Encoded data:", score_one_hot)
print("R-squared score for Label Encoded data:", score_label_encoded)
Explanation:
In this code sample, we are preprocessing the categorical features available in ‘home price’ dataset. We have taken the same example (explained above), so that we can easily relate to it. Both One-hot encoding and label encoding are used. We implemented One-hot encoding and did the following:
- Dummy variables are created
- Merged with the original dataset
- Certain columns are dropped to avoid multicollinearity
Label encoding is applied using scikit-learn's LabelEncoder, introducing a new 'town_encoded' column In label encoding the following steps are performed:
- Introduced a new 'town_encoded' column
- Data is split into dependent and independent variables for both encoding methods
- Train test split is performed (for both One-hot encoding and label encoding)
Comparison for One-hot encoding and label encoding is performed by applying Linear regression models trained on both one-hot encoded and label-encoded datasets, and their predictive performance is evaluated using R-squared scores.
Closing thoughts
Congratulations on making it to the end! We must have understood what one-hot encoding is, why it is used, and how to use it. One-hot and label encoding are the techniques to preprocess the data.
These two are the widely used techniques, so we have to decide which technique to implement for each type of data: One-hot or label encoding. I hope this article helped we in learning One-hot encoding.









