
Defining Uncertainty in Machine Learning
Machine learning has come a long way in recent years, and it's now used for applications from image recognition to natural language processing. Nonetheless, machine learning models still have room for improvement and often display uncertainty in their predictions. Robust and reliable models need an understanding of the sources of uncertainty in machine learning. Two major sources of uncertainty in machine learning will be covered here: aleatoric uncertainty and epistemic uncertainty.
Uncertainty estimation is important in machine learning for several reasons:
- Robust Decision Making: When it comes to making decisions, having some wiggle room can actually help us be more confident in our choices. If we know how reliable a prediction is, we can figure out when to go with it or if we need more information. For example, in autonomous vehicles, uncertainty estimation helps determine when to rely on the model's predictions or when to seek additional information.
- Model Evaluation: Understanding the uncertainty of machine learning models is essential for evaluating their reliability and performance. Measures of uncertainty provide light on a model's ability to generalize and reveal hidden biases or failure scenarios.
- Risk Management: For fields like medicine and finance, knowing the uncertainty behind forecasts isn't just useful - it's necessary. When advising on health issues or investments, professionals have to be upfront about the uncertainties, so clients can prepare accordingly. Quantifying the risk empowers people to adjust their actions based on how reliable the prediction is.
Aleatoric uncertainty
Aleatoric uncertainty, also known as statistical uncertainty, refers to the inherent randomness or variability in the outcome of an experiment or the data itself. In machine learning, aleatoric uncertainty comes from the noise in the data that the model can't get rid of. The model tries to estimate this uncertainty during training. It is worth noting that, more data doesnt help because the randomness is baked into the system. Like flipping coins - you'll never reduce the uncertainty in heads or tails by flipping more coins. That inherent variability is always there.
When we think about aleatoric uncertainty, we can think about a machine learning model that's supposed to predict how much a house costs based on stuff like bedrooms, bathrooms, and square footage. The model might nail down the price on some houses but there's always some wiggle room in the data that it just can't account for. For example, the model may not be able to accurately predict the price of a house that has unique features not present in the training data. In this scenario, the model's aleatoric uncertainty would capture the inherent variability in the data and indicate that the prediction may be less reliable.
For this case, the model may output a probability distribution over the possible prices, with a higher variance indicating higher aleatoric uncertainty. The variance can be calculated using the following formula:

where N is the number of samples, yi is the true value, and μi is the predicted value for the i-th sample.
Epistemic Uncertainty
Epistemic uncertainty is about not having enough knowledge or understanding of something. It's like when a model doesn't have enough data so it can't make good predictions. More data usually helps reduce this type of uncertainty. In machine learning, the model tries to estimate this uncertainty during training. You can think of it as the uncertainty that would go down if we had more training data
It can be estimated by training multiple models on different subsets of the data and measuring the variability of their predictions. One common approach is to use Bayesian neural networks, which can capture the uncertainty in the model's parameters
To show what epistemic uncertainty is, we can think about a machine learning model trying to classify pictures of dogs and cats. The model may be able to accurately classify some images, but there may be some images that the model cannot classify correctly. The epistemic uncertainty captures that lack of knowledge - it says the prediction might not be so reliable. For example, if the model was only trained on a small number of pictures of cats and dogs, it won't have seen many variations of cats or dogs. So, its epistemic uncertainty will be higher, meaning the prediction might not be as trustworthy.
The model may output a probability distribution over the possible classes, with a higher variance indicating higher epistemic uncertainty. The epistemic uncertainty can be calculated using the following formula:
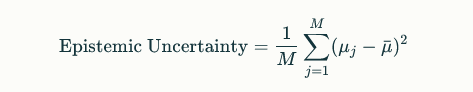
where M is the number of models, μj is the predicted value for the j-th model, and μˉμˉ is the average predicted value across all models.
Differences and Relevance in Machine Learning Models
Aleatoric and epistemic uncertainty have different implications for machine learning models. Aleatoric uncertainty has to do with the fact that, the data can be messy and limited. Knowing how unsure a model is because of aleatoric uncertainty, can help make better decisions based on what the model predicts. For example, in medical diagnosis, a model that can estimate its aleatoric uncertainty can provide more reliable predictions and help doctors make better-informed decisions.
Epistemic uncertainty is about how limited the model itself is. If a model has high epistemic uncertainty, it might not work that well in some cases. Its predictions shouldn't always be fully trusted then. Figuring out and dealing with epistemic uncertainty can help get more robust and reliable machine learning models.
Common Evaluation Metrics Used to Measure Uncertainty in ML Models
Calibration: Calibration measures the agreement between the predicted probabilities and the observed frequencies of the events. A well-calibrated model makes predictions that are spot on with the real world results and this is super important in domains like medical diagnoses or self-driving cars where the model's predictions are used to make decisions with significant consequences.
To check calibration, you plot the models predicted probabilities against the actual observed frequencies. If the model is well-calibrated, the plot should be a calibration curve that closely follows the diagonal line, indicating a good agreement between the predicted probabilities and the observed frequencies.
Log-likelihood: Log-likelihood tells you how well the model fits the data it was trained on. A high log-likelihood means your model fits the data like a glove. This is useful when you want your model to make accurate probability estimates like for financial forecasts or risk assessment.
You get log-likelihood by taking the log of the likelihood function, which basically gives the probability of the observed data given the model's parameters.
Entropy: Entropy basically tells you how random or uncertain a model's predictions are. A higher entropy indicates higher uncertainty in the predictions.. This makes entropy super useful for stuff like natural language processing or image classification where the model's predictions are used to make decisions with multiple possible outcomes.
Practical Examples
To further illustrate the concepts of aleatoric and epistemic uncertainty, consider the following practical examples:
- Machine learning models can be tricky to understand, especially when it comes to different types of uncertainty. Take autonomous driving as an example. Here, a model tries to detect stuff on the road, like pedestrians or other cars. The uncertainty that comes from the data itself - like different lighting or the presence of occlusion- is called aleatoric uncertainty. But there's also uncertainty that comes from the model not fully understanding the situation like how pedestrians behave in different scenarios: This is epistemic uncertainty.
- We can see a similar thing in medical imaging, where models try to detect cancer. The model's aleatoric uncertainty would capture the inherent variability in the data, such as the quality of the images or the presence of artifacts. The model also faces epistemic uncertainty from not fully understanding how cancer progresses in different patients.
- In natural language processing, a machine learning model may be trained to generate text based on a given prompt. The model's aleatoric uncertainty would capture the inherent variability in the data, such as the ambiguity of the prompt or the presence of noise in the input. The model can also run into epistemic uncertainty from not completely getting the nuances of language and culture.
In all these cases, the models wrestle with inherent variability in the data itself as well as gaps in their own knowledge. Disentangling these different shades of uncertainty can help us understand the limits of AI systems.
Conclusion
Being able to tell these two types of uncertainty apart is super important. It helps us make better decisions using the model's predictions, since we know where the uncertainty is coming from. And it also lets us figure out how to make our models more robust and reliable overall. If we see we have a lot of epistemic uncertainty, we know we need to get more data or optimize the model architecture. Whereas if it's aleatoric, we know that randomness will always be there and we just have to account for it.
Really digging into these two types of uncertainty can help us to build better machine learning models. We can make them more trustworthy and useful for real-world applications. Its a key piece of developing reliable AI.










