
Gradient is designed to be an end-to-end data science platform, and as such covers all stages of data science, from initial viewing of raw data through to models deployed in production with applications attached.
Therefore, it is of benefit to show working examples of end-to-end data science on Gradient.
Nvidia's GPU-accelerated recommender system, Merlin, is one such example. One of Nvidia's Use Case Frameworks, it has some excellent notebooks containing end-to-end work, and showcases a particularly large range of tools working together to interact with data at scale and provide actionable outputs.
Major parts of end-to-end data science shown in this blog entry are:
- ETL/ELT at scale
- Feature engineering
- Feature store
- Synthetic data
- Model training of deep learning recommenders
- Save model
- Deployment
- Ensemble of models: solve deployment preprocessing
Additionally, other detail methods such as approximate nearest neighbors search, single-hot and multi-hot encoding of categorical features, and frequency thresholding (less than a given number of occurrences of a class are mapped to same index).
The various stages such as data preparation, model training, and deployment, are done on GPU, and thus highly accelerated.
Tools included in the working notebook examples are:
- Nvidia Merlin NVTabular large-scale ETL workflows, including larger-than-memory datasets, feature engineering, and data preparation
- Nvidia RAPIDS cuDF for large dataframes in the familiar Pandas API
- Dask open-source Python library for parallel computing
- Apache Parquet column-oriented data storage format
generate_data()synthetic data in Merlin- Feast feature store
- Merlin Models recommender models including deep learning
- Merlin Systems operators and library to help integrate models with other parts of the end-to-end workflow
- Nvidia Triton Inference Server deployments into production
plus others such as Faiss fast similarity search, Protobuf text files, and GraphViz.
Let's take a brief look at Nvidia Merlin, followed by how to run it on Gradient, and the three end-to-end examples provided.
Nvidia Merlin

Merlin is Nvidia's end-to-end recommender system designed for GPU-accelerated work at a production scale.
As such, it is specialized for recommenders as opposed to, for example, computer vision or NLP text models. Recommenders are nonetheless a common use case in data science, and require their own frameworks to achieve optimal results like any other sub-domain of Deep Learning.
It solves many of the issues that arise when attempting end-to-end data science at scale, for example:
- Data preparation is done on the GPU, giving large speedups (NVTabular)
- Large data can be handled in a familiar API without having to add parallelism into the code (cuDF)
- An efficient column-oriented file storage format is used that is much faster than plain text files (Parquet)
- A feature store is included so that feature engineering is organized, simplified and reusable (Feast)
- Real training data can be augmented by synthetic data when needed, an increasingly popular component of AI work (Merlin
generate_data()) - Distributed model training enables better models to be trained faster (HugeCTR)
- Models are optimized for inference and can be deployed into production in a robust manner (Triton Inference Server)
- Preprocessing of incoming raw data in a deployment is solved by deploying the multiple components of a typical recommender as an ensemble (Triton ensembles)
The easiest way to run it is to use Nvidia's provided GPU-enabled Docker containers. By running on Gradient, many of the barriers to setting these up and using them, such as obtaining GPU hardware and setting up Docker, are removed.
Running it on Gradient
Because Merlin is supplied as Docker containers, plus a GitHub repository, it can be immediately run on Gradient using our runtimes, which combine these two components.
Create Notebook
After signing in, create a Project, then a Notebook.
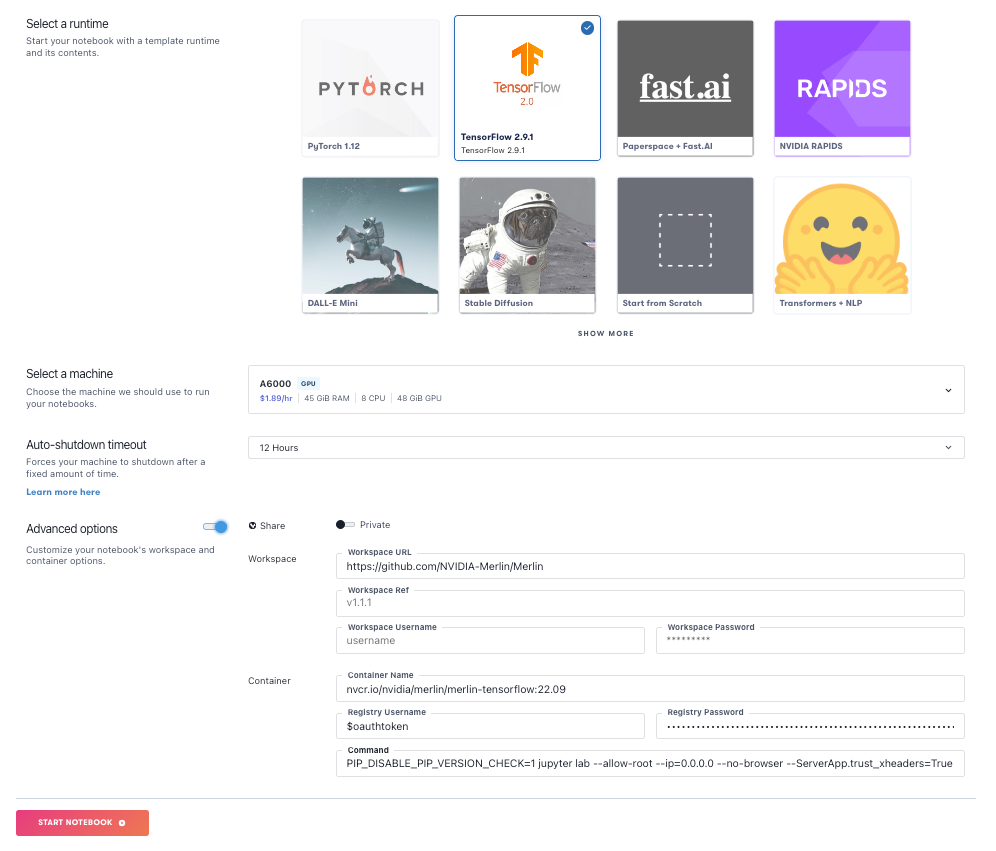
Choose a GPU machine to run it on. We used the Ampere A6000 with 48GB of RAM, but others, like the A100, may work. This is an expensive package to run, so be considerate of the high GPU costs when choosing a machine type and the possibility of OOM error if using a less powerful machine.
Select the TensorFlow recommended runtime (TensorFlow 2.9.1 at the time of writing). Under Advanced Options, for workspace enter https://github.com/NVIDIA-Merlin/Merlin, and for image, enter nvcr.io/nvidia/merlin/merlin-tensorflow:22.10 .
You can also launch the Notebook with a click (if you are a Growth account user, see link for details) using the link below:
Bring this project to life
Extra step needed: Nvidia API Key
For many containers and repositories, that's all there is to it! You are ready to go.
For this one, however, there is one extra step: Nvidia NGC Catalog Docker images require you to sign in to Nvidia first to download them. Luckily, Paperspace makes this easy because of its capability to sign into credentialed Docker registries.
So, under Advanced Options, for Registry Username enter $oauthtoken (this actual string, no substitution), and under Registry Password, paste in your Nvidia NGC Catalog API key.

It is also possible to create a Gradient Notebook programmatically in the usual way (including the API key), using the Gradient command line interface.
For more on Gradient Notebooks and their creation, see the documentation.
The Examples
The Nvidia Merlin repository supplies three main examples:
- Multi-stage recommender
- MovieLens dataset
- Scaling data with Criteo
Here we will not go into depth about how the recommenders are working, but:
(a) Talk about how common issues encountered in end-to-end work at scale are solved
(b) Provide a few notes and pointers for best running of the examples on Gradient. In fact they are remarkably easy to run for what they are achieving, but the odd detail here and there is worth mentioning.
General Setup
Some things to note for general Gradient Notebook setup:
- We ran the Notebooks on an A6000 single GPU. Other GPUs should work, although some with less memory may not do so well.
- If an out-of-memory error is encountered, resetting the kernel of the Jupyter notebook in question, or of other run notebooks, should clear the used GPU memory and allow things to run. You can check GPU memory usage via the GUI left-hand navigation bar metrics tab, or
nvidia-smion the terminal. - We recommend running each of Multi-stage, MovieLens, and Scaling Criteo in its own separate Gradient Notebook, so it remains clear which output came from which example. All 3 can use the same Github repository and Docker container, as given above under Create Notebook.
- When the notebooks are run, you may see occasional warnings such as NUMA codes or deprecated items. These may be from Gradient, or from the original examples, and are not critical to seeing the notebooks run through.
Example 1: Multi-Stage
The multi-stage recommender example can be found here, and consists of two Jupyter notebooks: 01-Building-Recommender-Systems-with-Merlin.ipynb and 02-Deploying-multi-stage-RecSys-with-Merlin-Systems.ipynb.
It demonstrates how to build a recommender system pipeline using four stages: retrieval, filtering, scoring and ordering. The figure from the first notebook shows what each of these are:
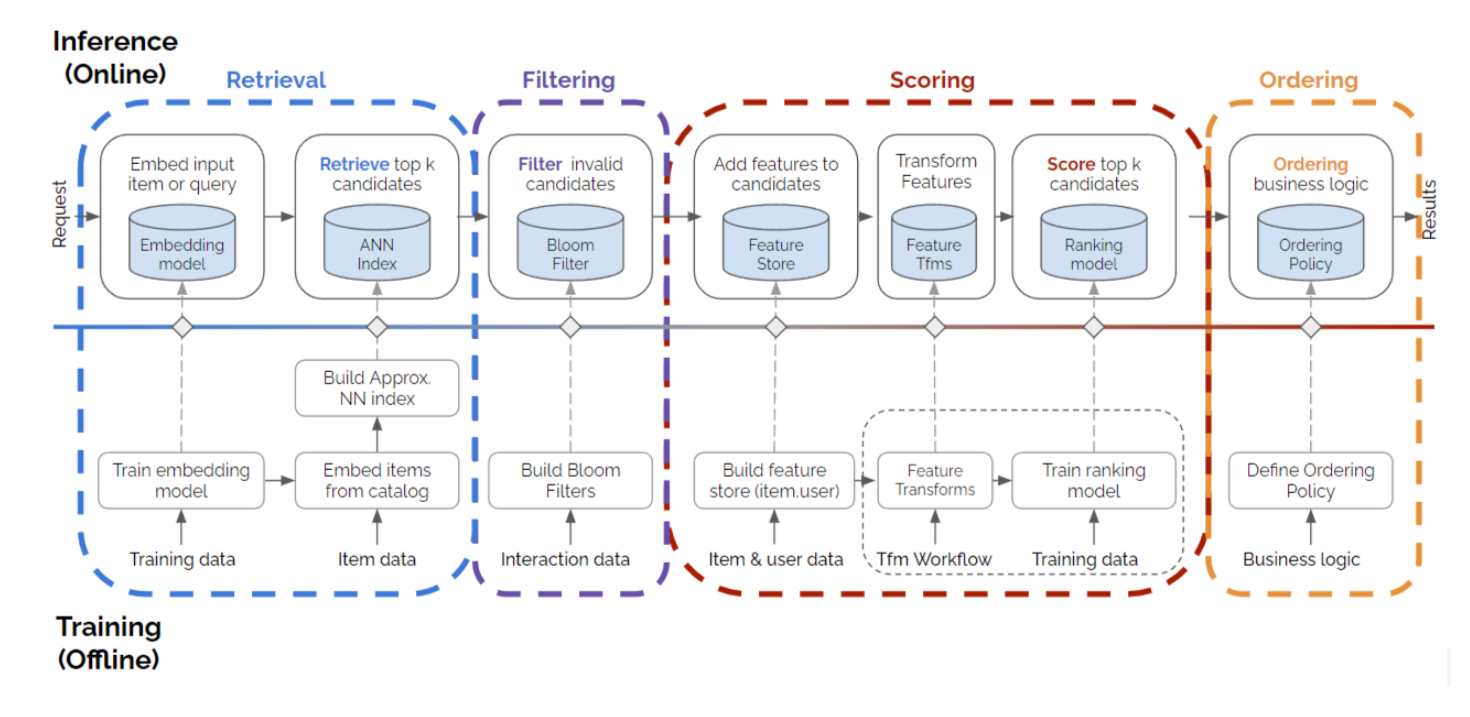
It trains both a retrieval (two-tower) model and a scoring/ranking model (Deep Learning Recommendation Model, aka. DLRM), includes data preparation and a feature store, and, crucially, shows how to deploy the multi-model setup into production using Triton Inference Server.
In 01-Building-Recommender-Systems-with-Merlin.ipynb, the dataset is prepared, feature engineering is done, and the models are trained. By default, the dataset generated is synthetic, using Merlin's generate_data() function, but there is an option to use real data from ALI-CCP (Alibaba Click and Conversion Prediction) too. The feature engineering is done using NVTabular, and the feature store uses Feast. After model training, the output goes to /workspace/data/.
In 02-Deploying-multi-stage-RecSys-with-Merlin-Systems.ipynb, the deployment is set up, including feature store, model graph exportation as an ensemble, and the Triton server. The model is then deployed, and recommendations can be retrieved.
Unfortunately, the notebook doesn't provide much insight into the correctness of the recommendations, or how they would then be used, but they look plausible.
Running the notebooks
When running notebook 1, you can do Run All, except that you will need to uncomment the %pip install "feast<0.20" faiss-gpu line in the first code cell.
For notebook 2, assuming you ran notebook 1, you can run everything except the last cell, which will fail. For that cell to run, start Triton Inference Server first in the terminal using tritonserver --model-repository=/Merlin/examples/Building-and-deploying-multi-stage-RecSys/poc_ensemble/ --backend-config=tensorflow,version=2. If it says out of memory, restart the notebook 1 kernel to clear some. Then you can run the last cell of notebook 2.
docker run) used in the original Nvidia GitHub repository uses the argument memlock=-1, and in Gradient the container is invoked behind the scenes without this. A fix is planned in the first quarter of 2023. In the meantime, to see deployments that do run, go to the MovieLens and Scaling Data examples below, which do not have this issue.Example 2: MovieLens
The MovieLens recommender example can be found here, and consists of notebooks in 4 steps. We will focus on the TensorFlow (TF) path, as that covers both training and deployment, and allows us to continue using the same Docker image as above. Therefore we run these 4 notebooks:
01-Download-Convert.ipynb02-ETL-with-NVTabular.ipynb03-Training-with-TF.ipynb04-Triton-Inference-with-TF.ipynb
In 01-Download-Convert.ipynb, the MovieLens-25M dataset is downloaded and converted from its supplied CSV format into the much more efficient Parquet.
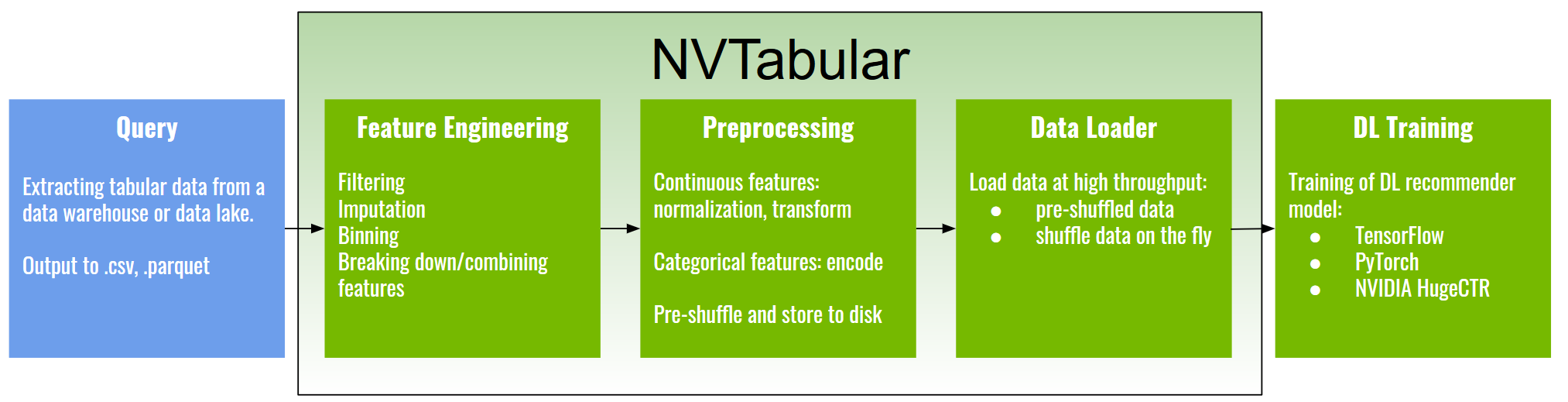
In 02-ETL-with-NVTabular.ipynb, NVTabular is used to perform data preparation. It has some useful functions like multi-hot features, meaning information like movie genres, whose number of categories varies for each data row, can be used fully. This is in addition to the usual usage of the user, item, and rating information. NVTabular is also able to handle data larger than the memory size of the GPU.
03-Training-with-TF.ipynb then trains the models, here using deep learning layers with embeddings, ReLU, etc. NVTabular's data loader is used to accelerate the training by reading the data directly into GPU memory, among other optimizations, removing what can otherwise be a bottleneck when using GPUs.
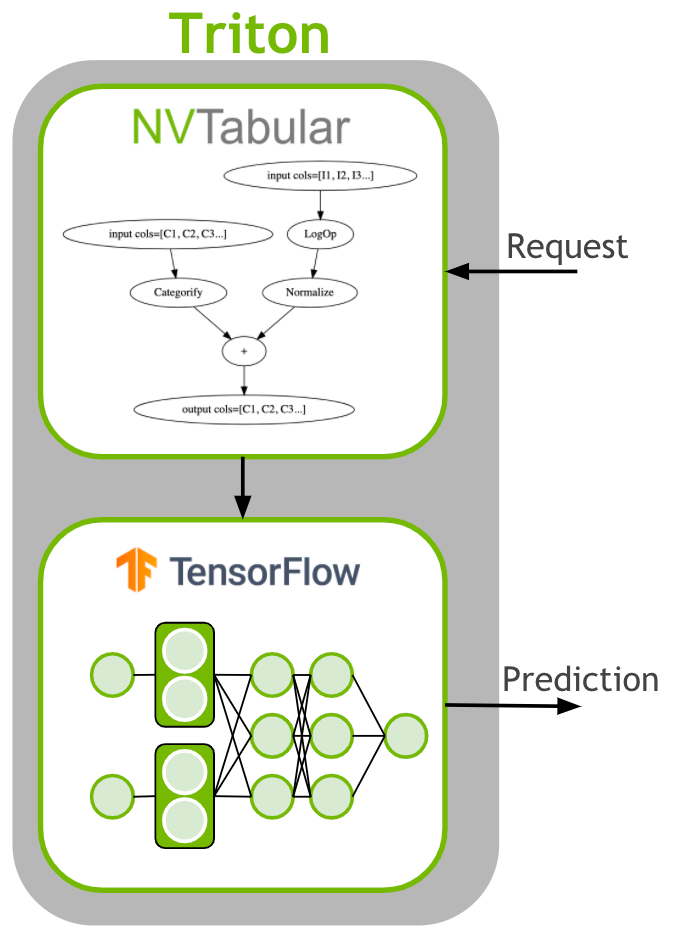
Finally, in 04-Triton-Inference-with-TF.ipynb the model is deployed using Triton Inference Server. As with the first example on Multi-Stage above, we don't get much insight into the utility of the recommendations, but it's clear that model outputs are being produced.
The examples here show again the capability of NVTabular in doing real data preparation, and speeding it up with GPUs:
We also see again the usage of Triton Inference Server to solve the problem of preprocessing incoming unseen data in production deployment:
Running the notebooks
The first 3 notebooks can be run as-are using Run All.
Before running notebook 4, start the Triton Inference Server, using the directories as they are created on Gradient: tritonserver --model-repository=/root/nvt-examples/models/ --backend-config=tensorflow,version=2 --model-control-mode=explicit.
Then notebook 4 also works with Run All.
Example 3: Scaling Criteo Data
In the third and final example, we see how to work with larger-scale data. The full public Criteo dataset is 1 terabyte, and consists of 4 billion rows of click logs over 24 days.
We focus on a 2 day subset, although we did find that using all 24 days does work for downloading and prep. The training and deployment worked for a Kaggle-sized 7 days, but 24 days needs a larger GPU setup.
For the full 24 days, the information online quotes "1.3 terabytes", but in fact this is the combined size of the compressed and uncompressed files, which don't both have to be kept on disk. 1 terabyte is the uncompressed size of the flat files before conversion to Parquet, which is about 250GB.
As with the first 2 examples, we focus on the TensorFlow 2 path, and run:
01-Download-Convert.ipynb02-ETL-with-NVTabular.ipynb03-Training-with-Merlin-Models-TensorFlow.ipynb04-Triton-Inference-with-Merlin-Models-TensorFlow.ipynb
In 01-Download-Convert.ipynb, the dataset is downloaded and converted to Parquet format. By default, it does not download all 1 terabyte, but downloads 2 of the 24 days, totaling about 30GB compressed. There is the option to download any number of days between 2 and 24, so you can scale up as desired. This notebook also sets up and uses a Dask cluster.
In 02-ETL-with-NVTabular.ipynb, the data is prepared using NVTabular, and the setup includes the capability to extend to both multi-GPU and multi-node. This uses a Dask cluster and the Nvidia RAPIDS dask_cudf library to work with Dask dataframes. Data preparation includes imposing frequency thresholding, so that categories that occur infrequently are grouped together into one category. The resulting NVTabular workflows take about a minute each to run on a single GPU with 2 days' data, and the output goes to /raid/data/criteo/test_dask/output/.

The model is trained in 03-Training-with-Merlin-Models-TensorFlow.ipynb. This time, it is the DLRM (Deep Learning Ranking Model) again, and the training + evaluation take a few minutes with the 2 days' worth of data. The model is saved to /raid/data/criteo/test_dask/output/dlrm/.
When the model is deployed in 04-Triton-Inference-with-Merlin-Models-TensorFlow.ipynb, the Triton setup includes the NVTabular workflow for feature engineering that was set up in notebook 2.
As with the other 2 examples, the correctness and utility of the model output recommendations are not really addressed, but we again see that they are being produced, and so we have run our "end-to-end" data science.
Running the notebooks
All 4 can be run as-are with Run All.
For notebook 1, after it has run and the original data is converted to Parquet, you can remove the original data to save disk space by doing rm -rf /raid/data/criteo/crit_orig/. The converted data is in /raid/data/criteo/converted/criteo/. Note that if you shut down and restart the Gradient Notebook, the data will be deleted as /raid is not a persistent directory. To retain it, move it to somewhere that is persisted, such as /storage.
For Notebook 2 using Dask, Gradient supports multi-GPU, although you would need to change the machine type to a multi-GPU instance, such as A6000x2. This is not required, however, and it will run fine on a single A6000. The dashboard that it mentions to be displayed in 127.0.0.1:8787 unfortunately does not work with the current Gradient Notebook architecture, but it is not needed for the rest to function. You can still see the CUDA cluster setup in the cell output.
For notebook 3, it runs through as-is.
For notebook 4, do Run All first before starting the Triton Inference Server using tritonserver --model-repository=/raid/data/criteo/test_dask/output/ensemble --backend-config=tensorflow,version=2. The penultimate cell will fail, but after the server has started you can run the last 2 cells. The server takes a minute or two to start up for these models.
Conclusions and Next Steps
We have seen how real end-to-end data science can be done on Paperspace Gradient, at a scale and robustness that is suitable for production. Nvidia Merlin recommenders provide an excellent demonstration of this.
We saw three examples:
- Multi-stage recommender
- MovieLens dataset
- Scaling data with Criteo
and a large number of different tools that are commonly used in end-to-end data science working together.
For some next steps, you can:
- Try out the Notebooks for yourself
- Learn more about Nvidia Merlin (website, GitHub repository, documentation, Docker images)
- Learn more about Paperspace Gradient at its documentation
- Learn more about other Nvidia functionality for end-to-end data science such as RAPIDS, and, for enterprise work, LaunchPad
Good luck!











