
Introduction
Many natural language processing (NLP) tasks, including sentiment analysis, question answering, natural language inference, named entity identification, and textual similarity, have benefited from language model pre-training.
ELMo, GPT, and, more recently, Bidirectional Encoder Representations from Transformers are examples of state-of-the-art pre-trained models.
The BERT Transformer is a massive one-stop shop for representing words and sentences. It is pre-trained on massive quantities of text with the unsupervised goal of masked language modeling and next-sentence prediction, and it can be fine-tuned with various task-specific purposes.
This paper investigates how pre-training a language model may improve its ability to summarize text. Summarization differs from earlier tasks because it requires a more comprehensive understanding of natural language than the meaning of individual words and phrases. The goal is to reduce the length of the original text while keeping as much of its original meaning.
Extractive summarization is often defined as a binary classification task with labels indicating whether a text span (typically a sentence) should be included in the summary. Abstractive modeling formulations call for language generation capabilities to create summaries containing new words and phrases not featured in the source text.
Methodology for Extractive Summarization
Suppose document d contains the sentences sent1, sent2, sentm, where senti is the i-th sentence.
Extractive summarizing marks each sentence(senti) with a label yi ∈ {0, 1} indicating whether or not it will be included in the summary. It is assumed that summary sentences represent the most critical content of the document.
Extractive Summarization with BERT
To work with BERT, extractive summarization must provide a representation for each sentence. In contrast, since it is trained as a masked-language model, BERT's output vectors are anchored to tokens rather than sentences.
Meanwhile, although BERT has segmentation embeddings for indicating different sentences, it only has two labels (sentence A or sentence B) instead of multiple sentences as in extractive summarization.
So, the researchers adapt BERT by changing its input sequence and embeddings to enable summary extraction.
Encoding Multiple Sentences: The researchers insert a CLS token before each sentence and a SEP token after each sentence, as shown in Figure 1. The CLS is used as a symbol in vanilla BERT to aggregate features from a single sentence or a pair of sentences. They modify the model by using several CLS symbols to extract features for sentences ascending the symbol.
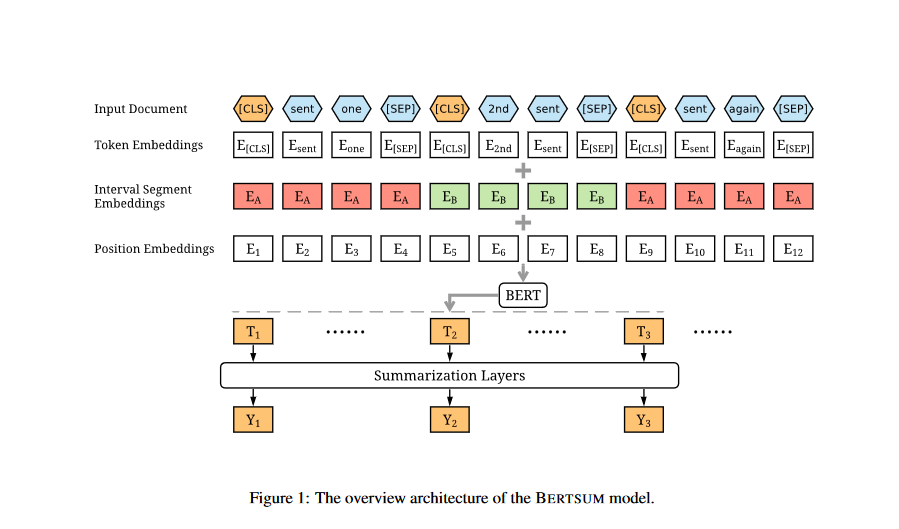
Interval Segment Embeddings: They use interval segment embeddings to differentiate across sentences in a document. Depending on whether i is an odd or even number, they use either the EA or EB segment embedding for senti. For sent1, sent2, sent3, sent4, and sent5, for example, they'll use EA, EB, EA, EB, EA. The vector Ti which is the vector of the i-th CLS symbol from the top BERT layer will be used as the representation for senti.
Fine-tuning with Summarization Layers: Once the researchers have obtained the sentence vectors from BERT, they stack various summarization-specific layers on top of the BERT outputs to capture document-level features for extracting summaries. They will figure out the predicted ultimate score, Yi, for each senti sentence. These summarization layers are jointly fine-tuned with BERT.
- Simple Classifier: Like in the original BERT paper, the Simple Classifier only adds a linear layer on the BERT outputs and uses a sigmoid function to get the predicted score:
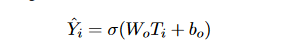
where σ is the Sigmoid function.
2. Inter-sentence Transformer: Inter-sentence Transformer applies more Transformer layers to sentence representations to get document-level features relevant to summarization tasks out of the BERT outputs.
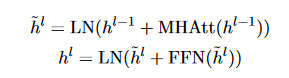
- h0 = PosEmb(T ) and T are the sentence vectors output by BERT. PosEmb is the function of adding positional embeddings to T.
- LN is the layer normalization operation.
- MHAtt is the multi-head attention operation.
- The superscript l indicates the depth of the stacked layer.
The final output layer is still a sigmoid classifier:
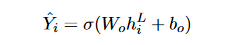
Where hpower(L) is the vector for senti from the top layer (the L-th layer ) of the Transformer. In experiments, the researchers implemented Transformers with L = 1, 2, 3 and found Transformers with 2 layers performs the best.
The loss of the model is the binary classification entropy of prediction ˆyi against gold label yi. Inter-sentence Transformer layers are jointly fine-tuned with BERTSUM. We use the Adam optimizer with β1 = 0.9, and β2 = 0.999). The learning rate schedule follows (Vaswani et al., 2017) with warming-up (warmup = 10, 000):
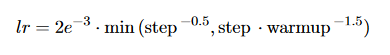
3. Recurrent Neural Network: While the transformer model has shown impressive performance on various tasks, Recurrent Neural Networks are still advantageous, particularly when combined with Transformer's methods. That's why the researchers add an LSTM layer on top of the BERT outputs to learn features relevant to summarization.
Methodology for Abstractive Summarization with BERT
Neural approaches to abstractive summarization conceptualize the task as a sequence-to-sequence problem, where an encoder maps a sequence of
tokens in the source document x = x1, ..., xn to a sequence of continuous representations z =z1, ..., zn, and a decoder then generates the target
summary y = y1, ..., ym token-by-token, in an auto-regressive manner, hence modeling the conditional probability: p(y1, ..., ym|x1, ..., xn).
Abstractive Summarization with BERTSUMABS
- The researchers use a standard encoder-decoder framework for abstractive summarization. The encoder is the pretrained BERTSUM and the decoder is a 6-layered Transformer initialized randomly.
- Since the encoder is pre-trained while the decoder is not, a mismatch between the two is possible. The encoder can overfit the data while the decoder underfits, or vice versa, making fine-tuning unstable. The researchers developed a novel fine-tuning shedule which separates the optimizers of the encoder and the decoder.
- They use two Adam optimizers with β1= 0.9 and β2= 0.999 for the encoder and the decoder, respectively, each with different warmup-steps and learning rates:
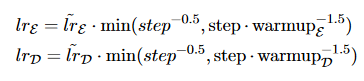
where ̃lrE= 2e−3, and warmupE= 20,000 for the encoder and ̃lrD=0.1, and warmupD=10,000 for the decoder. This is predicated on the idea that the pre-trained encoder has to have its learning rate lowered and its decay smoothed (so that it can be trained with more precise gradients as the decoder approaches stability). The BERT model for abstractive summarization is called BERTSUMABS.
Two-stage fine-tuned Model BERTSUMEXTABS
- Researchers propose a two-stage fine-tuning strategy, in which the encoder is first fine-tuned for the extractive summarizing task and subsequently for the abstractive summarization task. Evidence from prior research (Gehrmann et al., 2018; Li et al., 2018) indicates that extractive objectives can improve the efficiency of abstractive summarization.
- The model can take use of information exchanged between these two tasks without making any fundamental changes to its architecture; therefore, this two-stage technique is theoretically quite straightforward. The
two-stage fine-tuned model is called BERTSUMEXTABS.
Experiments
Implementation Details
The team used PyTorch, OpenNMT, and the 'bert-base-uncased'2 version of BERT to implement BERTSUM in both extractive and abstractive scenarios. Both source and target texts were tokenized with BERT’s subwords tokenizer.
Extractive Summarization
- All models are trained for 50,000 steps on 3 GPUs (GTX 1080 Ti) with gradient accumulation per two steps, which makes the batch size approximately equal to 36.
- Model checkpoints are saved and evaluated on the validation set every 1,000 steps. The researchers select the top-3 checkpoints based on their evaluation losses on the validations set and report the averaged results on the test set.
- When predicting summaries for a new document, they first use the models to obtain the score for each sentence. They then rank these sentences by the scores from higher to lower and select the top-3 sentences as the summary.
- To train extractive models, the researchers used a greedy algorithm to generate an oracle summary of each document.The algorithm produces a multi-sentence oracle that improves the ROUGE-2 score relative to the gold summary.
- Trigram Blocking: Trigram Blocking minimizes unnecessary information(redundancy) during the prediction phase. Assuming we have a chosen summary S and a candidate sentence c, we will disregard c if there exists a trigram overlapping between c and S. It is like the Maximal Marginal Relevance but much easier to implement.
Abstractive Summarization
- Researchers employed dropout (with a probability of 0.1) before each linear layer in their abstractive models, and they also used label smoothing with a smoothing value of 0.1. The Transformer decoder has 768 hidden units and the hidden size for all feed-forward layers is 2,048.
- All models were trained for 200,000 steps on 4 GPUs (GTX 1080 Ti) with gradient accumulation every five steps. Model checkpoints were saved and evaluated on the validation set every 2,500 steps.They selected the top-3 checkpoints based on their evaluation loss on the validation set, and report the averaged results on the test set.
- During decoding they used beam search (size 5), and tuned the α for the length penalty between 0.6 and 1 on the validation set; they decode until an end-of-sequence token is emitted and repeated trigrams are blocked. The decoder ap-
plies neither a copy nor a coverage mechanism. This is because they focus on building a minimum-requirements model and these mechanisms may introduce additional hyper-parameters to tune.
Summarization Datasets
- CNN/DailyMail: The researchers evaluated two benchmark datasets: the CNN/DailyMail news highlights dataset and the New York Times Annotated Corpus. The CNN/DailyMail dataset contains news articles and associated highlights, i.e., a few bullet points giving a brief overview of the article. They used the standard splits for training, validation, and testing (90,266/1,220/1,093 CNN documents and 196,961/12,148/10,397 DailyMail documents). They first split sentences with the Stanford CoreNLP toolkit and pre-process the dataset.
- NYT: The NYT dataset contains 110,540 articles with abstractive summaries. They split these into 100,834 training and 9,706 test examples based on the publication date. They took 4,000 examples from the training set as the validation set. They also followed their filtering technique, excluding documents having summaries of less than 50 words from the raw dataset. There are 3,452 test examples in the filtered test set(NYT50). They first split sentences with the Stanford CoreNLP toolkit and pre-process the dataset. nput
documents were truncated to 800 tokens. - XSum: It has 226,711 news articles and a simple summary that explains what each article is about in a single sentence. To train, validate, and test their models, they used the splits and pre-processing procedures established by Narayan et al. (2018a). Input documents were truncated to 512 tokens.
Experimental Results
The researchers evaluated summarization quality automatically using ROUGE . They report unigram and bigram overlap (ROUGE-1and ROUGE-2) as a means of assessing informativeness and the longest common subsequence(ROUGE-L) as a means of assessing fluency.
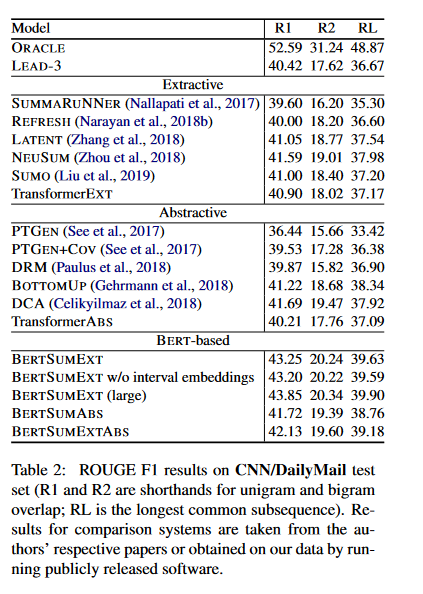
- Table 2 summarizes the results on the CNN/DailyMail dataset. The first block in the table includes the results of an extractive ORACLE system as an upper bound. They also present the LEAD-3 baseline (which simply selects the first
three sentences in a document). - The second block in the table includes various extractive models trained on the CNN/DailyMail dataset.
- For comparison to their own model, they also implemented a non-pretrained Transformer baseline (TransformerEXT) which uses the same architecture as BERTSUMEXT, but with fewer parameters. It is randomly initialized and only trained on the summarization task.
- The third block in Table 2 highlights the performance of several abstractive models on the CNN/DailyMail dataset. They also include an abstractive Transformer baseline (TransformerABS) which has the same decoder as the abstractive BERTSUM models.
- The fourth block reports results with fine-tuned BERT models: These models include BERTSUMEXT and its two variations (one without interval embeddings and one with the large version of BERT), BERTSUMABS, and BERTSUMEXTABS. On the CNN/DailyMail corpus, BERT-based models perform better than the LEAD-3 baseline, which is not a strawman.
- BERT models collectively outperform all previously proposed extractive and abstractive systems, only falling behind the ORACLE upper bound. Among BERT variants, BERTSUMEXT performs best which is not entirely surprising;
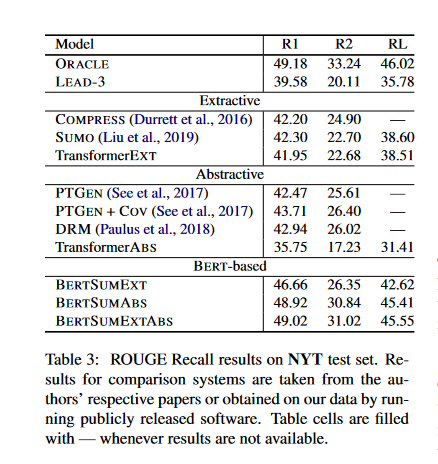
- Table 3 presents results on the NYT dataset. The researchers use limited-length ROUGE Recall, where predicted summaries are truncated to the length of the gold summaries.
- They report the performance of the ORACLE upper bound and LEAD-3 baseline. The second block in the table contains previously proposed extractive models as well as the Transformer baseline.
- The third block includes abstractive models from the literature, and our Transformer baseline. BERT-based models are shown in the fourth block. Again, we observe that they outperform previously proposed approaches.
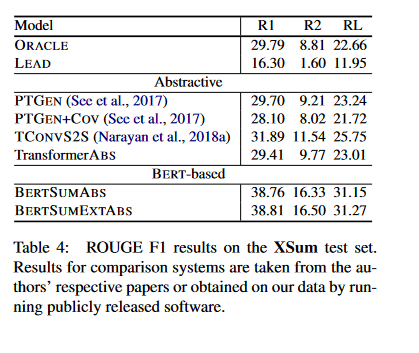
- Table 4 summarizes the results on the XSum dataset.
- Extractive models here perform poorly as corroborated by the low performance of the LEAD baseline, and the ORACLE. As a consequence, we do not disclose extractive model results on this dataset.
- The second block in Table 4 presents the results of various ab-
stractive models and also includes the abstractive Transformer baseline. - In the third block we show the results of our BERT summarizers which again are superior to all previously reported models.
A Simple Demo
Python provides a package called newspaper that simplifies data loading. This library is a web scraper, meaning it can get any textual data from the given URL, and newspaper can easily identify and extract languages. Newspaper will make an effort to determine the user's language automatically if none are specified.
Execute this command to set up this library:
!pip install newspaper3k For the sake of this assignment, we will use this particular article.
from newspaper import fulltext
import requests
article_url="https://edition.cnn.com/2022/09/19/uk/queen-royal-vault-king-george-chapel-intl-gbr/index.html"
article = fulltext(requests.get(article_url).text)
print(article)As soon as we feed our data into BERTSUM, the built-in module named summarizer immediately accesses it and outputs the summary, all in a matter of seconds.
from summarizer import Summarizer
model = Summarizer()
result = model(article, min_length=30,max_length=300)
summary = "".join(result)
print(summary)Conclusion
The authors demonstrated how pre-trained BERT might be effective in text summarization in this study. They developed a generic framework for both abstractive and extractive summarization and a unique document-level encoder.
Experiment findings across three datasets reveal that our model obtains cutting-edge performance under automated and human-based evaluations processes.
Reference
Text Summarization with Pretrained Encoders: https://arxiv.org/pdf/1908.08345.pdf









