

Bring this project to life
One of the coolest possibilities offered by AI and Deep Learning technologies is the ability to replicate various things in the real world. Whether it be generating realistic images from scratch or the right response to an incoming chat request or appropriate music for a given theme, we can rely on AI to deliver awesome approximations of the things previously only possible when guided directly by a humans hand.
Voice cloning is one of those interesting possibilities offered by this novel tech. This is the quality of mimicking the voice qualities of some actor by attempting to recreate their specific intonation, accent, and pitch using some deep learning model. When combined with technologies like Generative Pretrained Transformers and static image manipulators, like SadTalker, we can start to make some really interesting approximations of real life human behaviors - albeit from behind a screen and speaker.
In this short article, we will walk through each of the steps required to clone your own voice, and then generate accurate impersonations of yourself using Tortoise TTS in Paperspace. We can then take these clips and combine it with other projects to create some really interesting outcomes with AI.
Tortoise TTS
Released by solo author James Betker, Tortoise is undoubtedly the best and easiest to use voice cloning model available for use on local and cloud machines without requiring any sort of API or service payment to access. It makes it easy to clone a voice from just a few (3-5) 10 second voice clips.
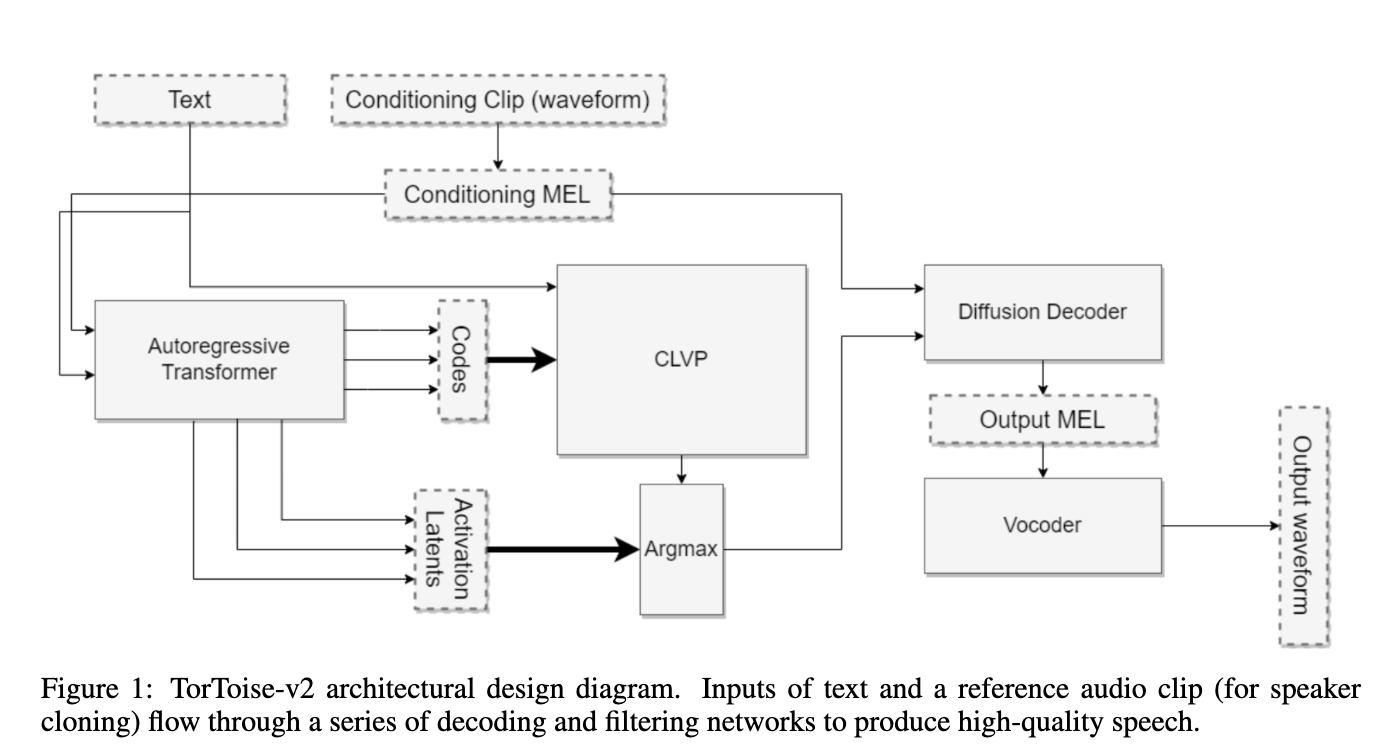
In terms of how it works and its inspiration, both lie with image generation with AutoRegressive Transformers and Denoising Diffusion Probabilistic Models. The author sought to recreate the success of those model approaches, but applied towards speech generation. In those models, they learn the process of image generation with a step-wise probabilistic procedure which, over time and large amounts of data, learn the image distribution.
With TorToise, the model is specifically trained on visualizations of speech data called MEL spectrograms. These representations of the audio can be easily modeled using the same process as used in typical DDPM situations with only slight modification to account for voice data. Additionally, we add the ability to mimic some existing voice type by using it as an initial noise object weight condition.
Together, this can be used to accurately recreate voice data using very little initial input.
Demo
Bring this project to life
For the demo, we are going to use the provided IPython Notebook in the original TorToise TTS repo. To spin this up in a Paperspace Notebook on a Free GPU, all we need to do is use the link above! Once we are in the Notebook space, just click run to get started, and open up the tortoise_tts.ipynb notebook.
Voice Sample Selection
In addition to their own suggestions for selecting voice samples, we have a few of our own for making things easier:
- If you do not have a proper microphone stand, we suggest using a mobile phone rather than a computer. The phone microphone will likely have much better noise reduction
- A good place to record will have no echoes. We tried to use samples of 'Bane' from "The Dark Knight Rises" for this demo, but his voice was too full of echo from the inside of his mask. We recommend a closet full of clothing that will damp any extra sound
- Write out a script for your recordings. This will help you avoid any stuttering, "uh" or "um" sounds, or minor flubs
- If possible, try to cover the widest variety of phonemes (sounds in language) possible. These are called phonetic pangrams. This will help the model know all the different potential sounds in your speech. An example of this would be "That quick beige fox jumped in the air over each thin dog. Look out, I shout, for he's foiled you again, creating chaos."
If you follow both our suggestions as well as the originals, your clone should go without hitches. Here are the recordings we used for this demonstration:
If everything is done correctly, your final output should closely approximate the intonation, tone, and pitch of the voices in your original inputs. This may not work perfectly however. In our case, we tested a few samples using slowly recorded voice samples that were not phonetic pangrams, and were left with a result with an English accent haphazardly added on:
Read to the end of the next section for some working examples we made using our voice, the provided sample voices, and some celebrities we sourced for our own amusement.
Ethical considerations
If you clone others voices, be sure to consider the ethics of such actions, not to mention potential legal ramifications. We do not recommend using voice cloning of anyone without their express permission for anything other than parody and experimentation, and disavow any bad actors who would use this technology for any sort of malicious or self serving intent.
Code breakdown
The first thing we need to do is set up the workspace. The first code cell has all of the installs we need for this project. Unfortunately, the author did not include all of those in the requirements.txt file, so we have appended a few extra installs to facilitate the process.
#first follow the instructions in the README.md file under Local Installation
!pip3 install -r requirements.txt
!pip install librosa einops rotary_embedding_torch omegaconf pydub inflect
!python3 setup.py installThe next code cell contains the actual imports and model downloads themselves. If you are on one of Paperspace's Free GPUs, do not worry! The model download is in the cache and shouldn't count against your total storage. Though that does mean the download will have to restart each time your machine is spun back up after the end of a session.
# Imports used through the rest of the notebook.
import torch
import torchaudio
import torch.nn as nn
import torch.nn.functional as F
import IPython
from tortoise.api import TextToSpeech
from tortoise.utils.audio import load_audio, load_voice, load_voices
# This will download all the models used by Tortoise from the HF hub.
# tts = TextToSpeech()
# If you want to use deepspeed the pass use_deepspeed=True nearly 2x faster than normal
tts = TextToSpeech(use_deepspeed=True, kv_cache=True)Once the model has completed downloading, we can do a simple TTS generation without voice cloning using the provided code in the following cell. This will have a random voice as determined by the model. We can take a look at the code for this unguided speech generation in the following cell:
# This is the text that will be spoken.
text = "Joining two modalities results in a surprising increase in generalization! What would happen if we combined them all?"
# Here's something for the poetically inclined.. (set text=)
"""
Then took the other, as just as fair,
And having perhaps the better claim,
Because it was grassy and wanted wear;
Though as for that the passing there
Had worn them really about the same,"""
# Pick a "preset mode" to determine quality. Options: {"ultra_fast", "fast" (default), "standard", "high_quality"}. See docs in api.py
preset = "ultra_fast"We can now upload our own voice recordings to the /notebooks/tortoise-tts/tortoise/voices directory. Use the file navigator on the left side of the GUI to find this folder, and create a new subdirectory titled "voice_test" within. Upload your sample recordings to this folder. Once that is complete, we can run the next cell to get a look at all the available voices we can use for the demo.
# Tortoise will attempt to mimic voices you provide. It comes pre-packaged
# with some voices you might recognize.
# Let's list all the voices available. These are just some random clips I've gathered
# from the internet as well as a few voices from the training dataset.
# Feel free to add your own clips to the voices/ folder.
%ls tortoise/voices
IPython.display.Audio('tortoise/voices/tom/1.wav')
#### output #### these are the names
#angie/ freeman/ myself/ tom/ train_grace/
#applejack/ geralt/ pat/ train_atkins/ train_kennard/
#cond_latent_example/ halle/ pat2/ train_daws/ train_lescault/
#daniel/ jlaw/ rainbow/ train_dotrice/ train_mouse/
#deniro/ lj/ snakes/ train_dreams/ weaver/
#emma/ mol/ tim_reynolds/ train_empire/ william/Now we are finally ready to begin voice cloning. Use the code in the following cell to generate a sample clone using the text variable as input. Note, we can adjust the speed (fast, ultra_fast, standard, or high_quality are the options), and this can have pretty profound effects on the final output.
# Pick one of the voices from the output above
voice = 'voice_test'
text = 'Hello you have reached the voicemail of myname, please leave a message'
# Load it and send it through Tortoise.
voice_samples, conditioning_latents = load_voice(voice)
gen = tts.tts_with_preset(text, voice_samples=voice_samples, conditioning_latents=conditioning_latents,
preset=preset)
torchaudio.save('generated.wav', gen.squeeze(0).cpu(), 24000)
IPython.display.Audio('generated.wav')Change the text variable to your desired test, and run the following cell to get the audio output!
Closing thoughts
As far as Deep Learning applicability goes, this is one of our favorite projects to come through in the last couple years. Voice cloning has infinite possibilities as far as creating entertainment, conversational agents, and much, much more.
In this tutorial, we showed how to use TorToise TTS to create voice cloned audio samples of speech using Paperspace. We encourage you to play around with this technology using other samples. We, for example, created a new voicemail using one of our favorite celebrities. Try the same out using the morgan voice for an extremely pleasant surprise!











