
Bring this project to life
What if instead of training lots of models for many different tasks, we only had to train one model? Then that model does all of our tasks.
While it sounds fanciful, there are examples already available where the same model can perform many different tasks, running on images, text, audio, video, and more.
Such generalist models (aka. generalist agents or multi-modal models) are becoming increasingly able to take on a large number of different use cases. This means that in the future we may not need to manage many models, but can run end-to-end artificial intelligence on just a few, or even one.
Simplifying end-to-end AI in this way would open it up to use by many more people, because the remaining model or models could potentially be put within easy-to-use no-code interfaces, while retaining their full problem-solving ability.
So while we have not yet seen the one model to rule them all, it is worth exploring their current capabilities.
Here, we will review 3 of them:
- Perceiver IO
- Data2vec
- Gato
and, specifically, we will show how to run Perceiver IO on Paperspace.
Perceiver IO and Gato are from DeepMind, and Data2vec is from Meta AI.
The days of true artificial general intelligence (AGI) are still some way off, but in future these may be remembered as taking some of the steps towards it.
Why are they general?
Each of the 3 models presented here differs in its details from the others, but the underlying idea that makes them general is that the data passed into them is converted into the same form regardless of input. So images, text, audio, etc., all get converted into the same underlying form that the models can then be trained on.
The models then output predictions on the data in this form that get converted back to actionable outputs in an inversion of the transformation used for the inputs.
The changeable components of the models become just the input and output for dealing with their data, while the models themselves retain the same form.
Why are they important?
The importance of these models lies not just in their potential successors a long way down the road paving the way to an artificial general intelligence, but in their more near-term utility:
- Fewer models to manage: one model for many tasks instead of multiple models strung together in a dataflow simplifies management, such as when routing data, versioning, deploying, checking accountability, data I/O versus training, and so on.
- Simpler interfaces: having a general model with swappable input and output means it will become easier to create more general end-to-end interfaces and applications, opening their use to less technical and even no-code users.
- They can outperform specialist models: aside from being more general, there are several instances of these generalist models outperforming previous specialist models on the same tasks, so the process is not only simpler but can also produce better results.
Having a combination of abilities in one place, and being able to deal with many types of data at once, means they can also be combined in novel ways. For example, not only creating a video, but also captioning it and speaking the words, giving greater accessibility for all audiences. The possibilities multiply as abilities are added.
The 3 models
Now lets' see a general overview of what each of the models is doing. For more in-depth descriptions, see the original blogs and papers referenced below.
Perceiver IO
Perceiver IO (blog, HF repository, paper, Wikipedia) is based on a transformer neural network. Originally used for natural language processing (BERT, etc.), transformers were then applied to computer vision, e.g., the vision transformer ViT, and now as generalist models. They work by using attention, which means that the parts of the data found to be more important in training receive greater weight and have more compute time spent on them.
The input data, regardless of source such as images, text, audio, etc., is mapped to a latent space of lower dimension. In other words, the network itself is not modality-specific, and all data passed in proceeds in the same form. A latent space means that items in the original data that resemble each other are closer together in the new space. The model is using cross-attention, which is the use of attention to map the data to different numbers of dimensions. The use of attention to reduce the size of the data in this way is also known as an attention bottleneck. Specific features of the latent data are associated to their parts of the input, keeping what passes through the network in sequence with the original data.
Because all data passes through the network in the same form, it means that all the outputs are also the same form. The outputs therefore then have to be interpreted in terms of the task the user wants to perform, and transformed back appropriately. This is done by the user passing in a query that combines with the latent data in the network to produce outputs in the desired form. This encoding of data at the start then decoding at the end resembles what is done in the widely used class of models known as encoder-decoder neural networks.
The use of latent data in the network, which is of lower dimension than the original data, means that the network can scale to handle large inputs and outputs without becoming too slow, unlike transformers.
The diagram from the original DeepMind blog shows a useful overview of the Perceiver setup:
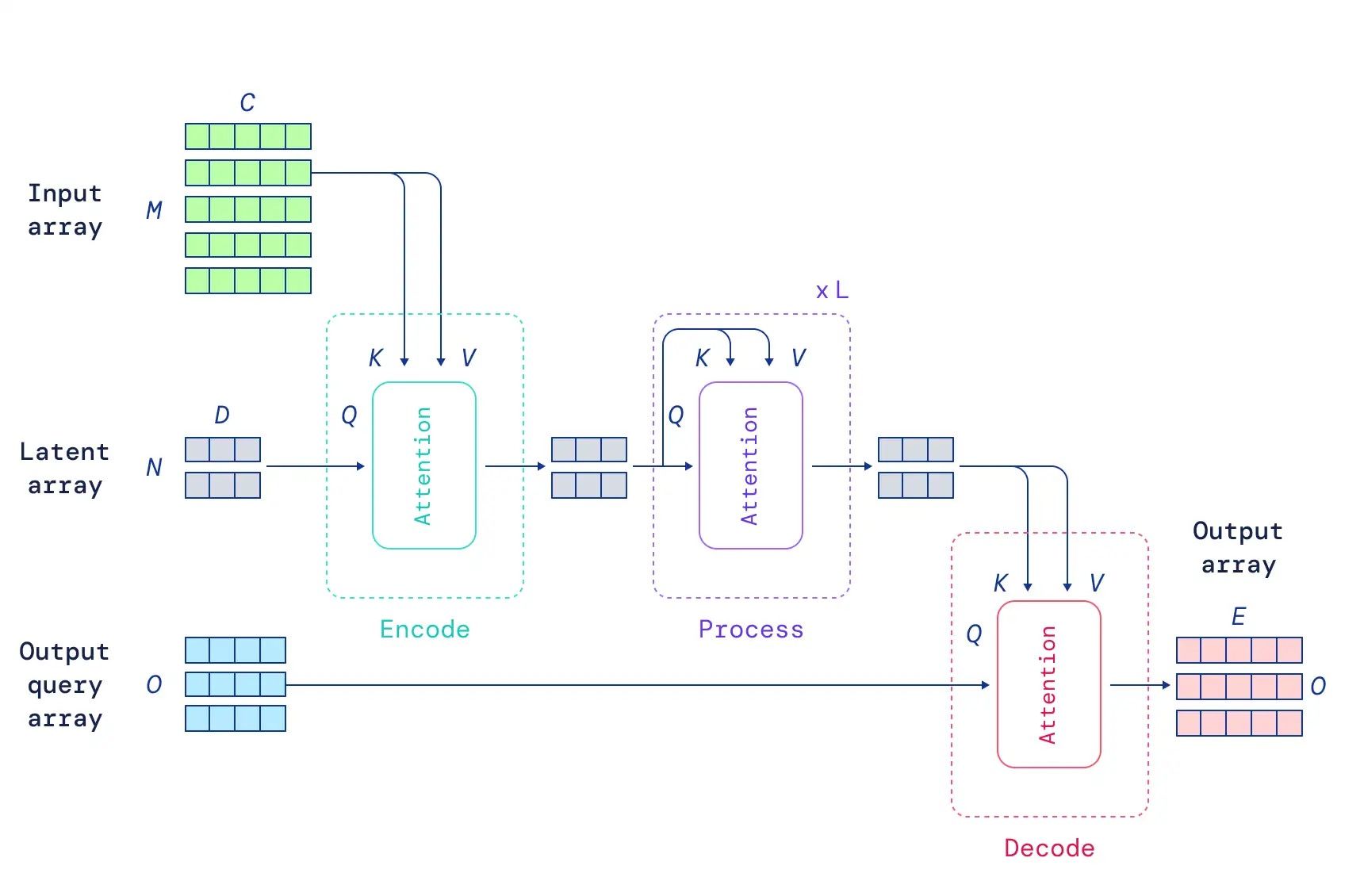
Perceiver IO has been shown to match the performance of other models, such as BERT for language and ResNet50 for images, plus is state-of-the-art on AudioSet audio+video data and Sintel video for optical flow. Further demonstrated applications include classifying 3D point clouds and videogaming.
Data2vec
Announced in January 2022 by Meta AI (aka. Facebook), Data2vec (blog, repository, paper) is the first self-supervised algorithm that works for multiple different types of data.
Self-supervised algorithms are important, because they are able to train on data that does not have labels. There is a lot more unlabeled data out there than labeled data. Self-supervised models learn by observing their environment directly.
But, as they point out in the blog, the way that other self-supervised models learn depends a lot upon the type of input data. So being able to learn from all types of data in one model is a step forward from this, and opens up wider usage of self-supervised learning.
The types of data that Data2vec is shown working on are not quite as general as Perceiver IO, but they still include images, text, and speech.
In a similar idea to Perceiver IO, Data2vec achieves its generality by transforming all input data into a particular representation, again the latent space encoding of the most important parts. The model then learns on this representation in a self-supervised manner, rather than the original data.
The learning is done by the combination of a teacher network and a student network. The teacher turns whatever the input data is into a target representation, then the student predicts the representation with part of the data hidden. This is then iterated until the student network is able to predict the data. Currently the exact method of turning the data into its representation depends on whether it is images, text, or speech.
The animation from the original Data2vec blog gives a schematic illustration of the learning process:

Because all types of input data are formed into a specific representation, the model's outputs are also in the form of this representation. This then has to be translated back to the external format to see the model's predictions directly.
Like Perceiver IO, the general model here not only equals the performance of previously specialized models, but outperforms them for computer vision and speech tasks. The NLP text tasks are also done well. The data they tested it on includes ImageNet for vision, LibriSpeech for speech, and GLUE for text.
The method is not limited to the 3 types of data studied here. So long as the data can be converted into the model's representation, it can be used.
Data2vec has a public GitHub repository, which can be run on Paperspace by pointing to it from a Gradient Notebook in the usual manner.
Gato
Like their Perceiver IO, DeepMind's Gato (blog, paper, Wikipedia) is also based upon a transformer neural network. The difference from Perceiver IO is that a single Gato model learns all at the same time how to do many different tasks.
The tasks include playing Atari video games, captioning images, text chat with a user, stacking blocks with a robot arm, navigating simulated 3D environments, following instructions, and others.
As with Perceiver IO and Data2vec, the different data types are all processed into a single more general type to pass through the network. Here, it is a sequence of tokens:
- Text is encoded into subwords
- Images are sequences of non-overlapping patches in raster order, then normalized
- Discrete values are integer sequences
- Continuous values are floating point sequences, normalized and then binned
Examples of discrete and continuous values respectively are button presses when playing a game, and proprioceptive inputs. In total, Gato was trained on 604 different tasks.
The tokenized and sequenced data is passed through an embedding function. What the function does depends on the type of input data, and the result is the vectors input into the model. This again follows the idea of all types of input being converted into the same representation within the model.
The diagram from the original blog entry shows a sketch of how things pass through, and some of the tasks that can be performed:
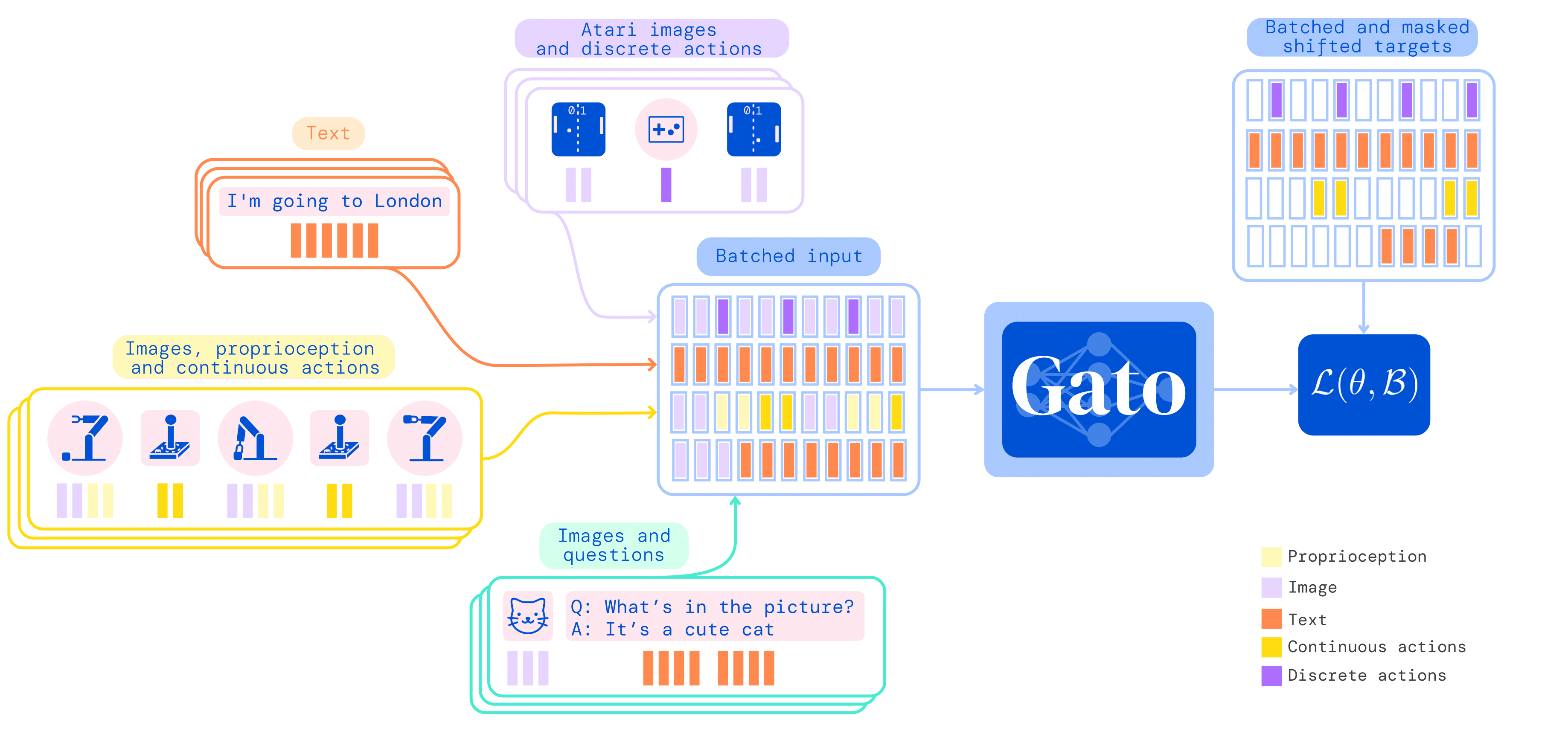
The model is deployed by applying the inverse of the encoding + sequencing that was performed on its inputs to the model's outputs to give its next action to perform. It is sent an initial observation of the environment, then it acts, observes the new environment, acts again, and so on.
Gato's performance relative to more specialized models depends upon which task it is performing. Because results are presented for 604 different tasks, we don't attempt to quantify them all here, but very roughly, the same trained model with the same weights gets most of the way to expert performance for most tasks. This is different to Perceiver IO and Data2vec, where sometimes those models were outperforming the state-of-the-art, but this model is doing the most different things.
There is therefore room for improvement on any single task, but this is an example of a general method where all of it parts will benefit from ever increasing computing power in the future. The model size presented was held down to be usable for real-time robotics as one of its tasks, and so at 1.2 billion parameters it is relatively small by current standards. So it is in fact striking how many things it can do at this scale, and the scaling analysis indicates further room for improvement if it were to be trained with more parameters.
Of the 3 models discussed here, Gato is the most proto-AGI-like because it is one model that can do many things all at once. And indeed, the paper devotes more text than the papers for the other two models to discussing its broader context in the evolution and safety of AI.
For now it remains much closer to existing deep learning models than to a future superintelligence. But these models will only get better as time goes on.
Gato doesn't have a public version yet, so it is not available to run on Paperspace.
Generalist models on Paperspace
Bring this project to life
Now let's look at how to run a generalist model on Paperspace. We will focus on Perceiver IO. Click the link above or follow the instructions below to launch Perceiver IO in a Gradient Notebook.
The original JAX-based content from DeepMind has been implemented on PyTorch in an excellent GitHub repository and blog on Hugging Face by Niels Rogge. While JAX can be run on Paperspace, we use this PyTorch repository as our route to running Perceiver IO.
To run it on Paperspace, start a Gradient Notebook in the usual way. Use the PyTorch runtime, and all options on their default settings, except for:
- Machine: Choose a larger machine. We used an Ampere A6000, although any with at least 16GB RAM should be OK.
- Workspace: Under Advanced Options, set this to https://github.com/NielsRogge/Transformers-Tutorials
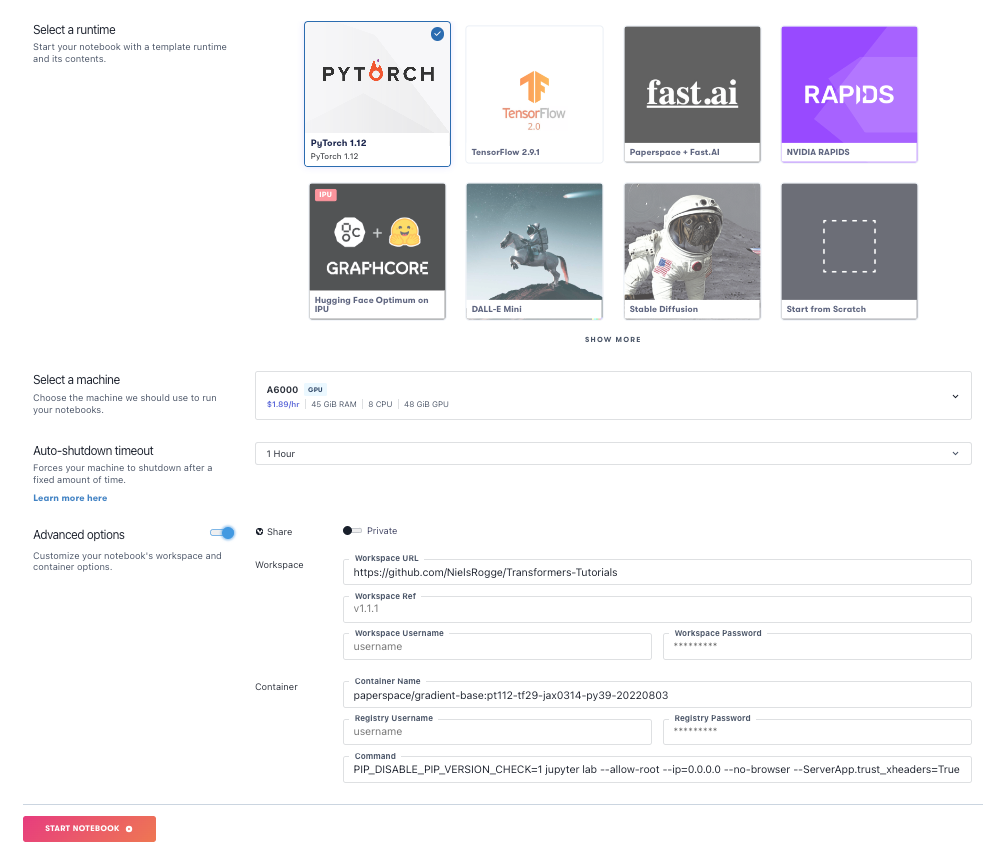
The GitHub repository for this Workspace contains many other models besides Perceiver, so to run it, navigate to the Perceiver directory, where we will find five .ipynb Jupyter notebooks.
Each one can be opened and run using Run All, or by stepping through the cells.
We recommend restarting the notebook kernel after a run so that the GPU does not run out of memory on a subsequent run. We can also check the GPU memory usage at any time by using either the metrics tab on the left-hand GUI navigation bar, or nvidia-smi in the terminal.
Perceiver_for_Multimodal_Autoencoding.ipynb, we will need to run pip install accelerate before running the notebook. Either do so from the command line in the terminal, or add a cell to the notebook containing !pip install accelerate. If we choose the cell method, restart the notebook kernel before proceeding to run the rest of the cells, so that accelerate can be imported.The Perceiver IO functionalities shown in the 5 notebooks are as follows:
Fine_tune_Perceiver_for_text_classification.ipynb: This shows text classification and runs on a subset of the Internet Movie Database (IMDB) dataset, performing binary classification of whether a movie review is good or bad. Perceiver IO doesn't need to tokenize text first, so the bytes are provided directly as input. It goes through from fine-tuning training to showing inference on the test set, and the prediction for the review being good or bad.Fine_tune_the_Perceiver_for_image_classification.ipynb: This shows image classification into 10 classes using a subsample of the CIFAR-10 dataset. The model trained on ImageNet has its final output replaced to classify on CIFAR-10. The mode evaluates to 60s or 70s percentage accuracy, but it could be trained on more data, with more augmentation than the notebook shows by default. (As mentioned earlier, when fully trained Perceiver IO can match the performance of other models that were designed specifically for images.)Perceiver_for_Optical_Flow.ipynb: This uses 2 frames of the Sintel video dataset, with optical flow being to interpolate between them at the pixel level. The resulting flow is then visualized using Gradio. While use of the Perceiver simplifies many tasks, this one simplifies versus a specialized setup more than most.
iface.launch(debug=True) to iface.launch(debug=True, share=True). Otherwise, you will not be able to open the popup window, as Gradient doesn't currently support port forwarding.Perceiver_for_Multimodal_Autoencoding.ipynb: Multimodal autoencoding means that the model is working with more than one type of input data at the same time. In this notebook, the UCF101 dataset is loaded, using its video, audio, and class label data. Multimodal pre- and post-processing is used, and the resulting output shows the reconstructed video, audio, and predicted class labels for what the video is showing.Perceiver_for_masked_language_modeling_and_image_classification.ipynb: This shows masked language modeling and image classification on the same model architecture, resulting in correct text and classification outputs.
Conclusions
We have introduced the generalist models Perceiver IO, Data2vec, and Gato, and shown Perceiver IO running on Paperspace. It performs tasks related to images, text, audio, and video. Each one is straightforward to load up and run, in the usual Paperspace manner.
These models represent a step forward in generality compared to most models. Particularly significant is that they not only generalize the earlier models, but in some cases also outperform them.
While a true artificial general intelligence is still some way in the future, in the shorter term these models may both simplify and broaden the reach and capability of AI and end-to-end data science.
Thanks for reading!
Next Steps
Some next steps we can take are to run these on Paperspace, or learn about the models in more detail than given here by referring to the original blogs and papers. Note that many of those more detailed expositions will assume that we already know about many of the deep learning concepts introduced here.
The Perceiver IO Hugging Face content, like their blog, is based upon the original content from DeepMind, but implements it in PyTorch + .ipynb rather than JAX + .py.
- Try out Perceiver IO on Paperspace
- Perceiver IO: blogs (DeepMind, Hugging Face), repository, paper, Wikipedia
- Data2vec: blog, repository, paper
- Gato: blog, paper, Wikipedia
- Learn more about Paperspace at the documentation and tutorials
- Try out Data2vec from its repository
- Try out the agents on other tasks, full-sized data, and on different datasets not shown here








