
Most of our readers are familiar with the two big players in the world of Deep Learning, namely PyTorch and TensorFlow. These libraries are essential for any Deep Learning professional or enthusiast to make use of, and Gradient takes away the hassle of setting up and installing packages like these by relying on Docker images to run the Notebooks on.
Many of the containers our users use come prepackaged as Gradient Notebooks Runtimes, which allow our users to quickly access the GPU enabled Notebook with both the files and installs completed. You can also directly input any workspace URL or container, saved on service like Docker Hub or Nvidia NGC, to a Notebook via the advanced options.
We have created a new JAX-enabled container that can be used with Gradient Notebooks, and this article is meant to help guide users seeking to get started with using JAX with Gradient Notebooks.
What is JAX?
JAX is one of the rising stars in the Deep Learning community. A machine learning library from Google designed for high-performance numerical computing, it has burst on to the scene since its release.
According to their docs, "JAX is NumPy on the CPU, GPU, and TPU, with great automatic differentiation for high-performance machine learning research." [1]. In practice, JAX behaves similarly to the popular library, NumPy, but with the addition of Autograd and XLA (Accelerated Linear Algebra), which allows for array manipulations to take advantage of GPU-enabled machines. It can handle this action through a number of clever differences to its predecessor.
The key changes are fourfold: the additions of Autograd differentiation, JAX vectorization, JIT (just-in-time) compilation, and XLA.
- JAX's updated version of Autograd allows JAX to automatically differentiate NumPy and Python code. This includes working with many Python features like loops, ifs, recursions, closures, and more. It can also take derivatives of derivatives of derivatives. This allows for reverse-mode differentiation (a.k.a. backpropagation) via
gradas well as forward-mode differentiation, and the two can be composed arbitrarily to any order. [2] - JAX vectorization via the
vmapfunction, the vectorizing map, allows for familiar mapping of functions across array axes. The loop is kept down in a function’s primitive operations for improved performance. [3] - JAX contains a function transformation, JIT, for just-in-time compilation of existing functions.
- JAX also leverages XLA to run NumPy code in a way optimized for accelerator hardware like a GPU or TPU. XLA compiles by default under the hood, and library calls get compiled and executed just-in-time. JAX even enables just-in-time compilation of your own Python functions into XLA-optimized kernels using its one-function API. Compilation is also composed arbitrarily, so complex algorithms can be implemented optimally without having to write non-Python code. [1]
For more information on what JAX is, check out their quickstart page in the docs.
Why use JAX?
The utility of JAX can be succinctly boiled down to replacing and outperforming NumPy for use with GPUs. Given that it is essentially Autograd 2.0, users at all levels can get utility out of JAX.
Furthermore, JAX is capable of replacing much of the functionalities offered by deep learning libraries like Keras, TensorFlow, and PyTorch. JAX based DL libraries like Elegy, Flax, and ObJAX can all carry out much of the same tasks as mainline DL libraries, but are at relatively early stages in development compared to the Keras or Torch suites.
Try out JAX on Gradient by following the instructions below to get started with using JAX on Gradient today.
Bring this project to life
How to Make a JAX enabled Gradient Notebook:
To create a JAX enabled Gradient Notebook, only a few short steps need be followed. In the Create Notebook page, first scroll past the Runtimes section, select a GPU for your Notebook, and navigate to and click on the toggle for "Advanced Options." In this section, paste the following into their respective text boxes:
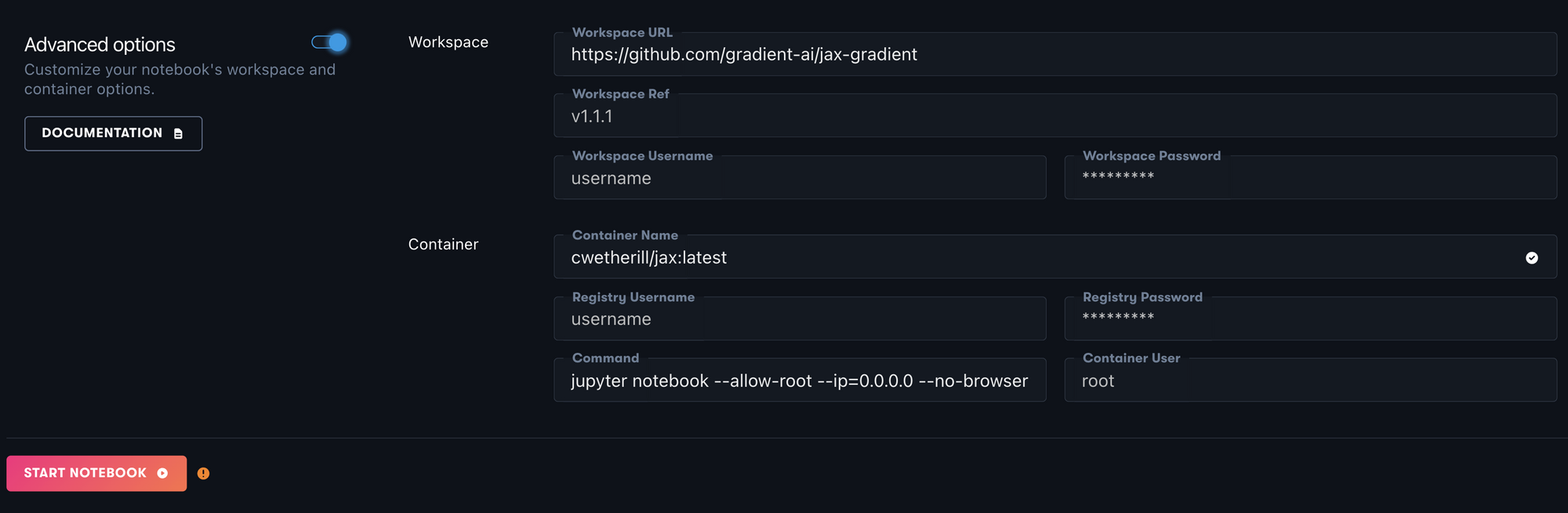
- Workspace URL: https://github.com/gradient-ai/jax-gradient
- Container Name: cwetherill/jax:latest
- Command:
jupyter lab --allow-root --ip=0.0.0.0 --no-browser --ServerApp.trust_xheaders=True --ServerApp.disable_check_xsrf=False --ServerApp.allow_remote_access=True --ServerApp.allow_origin=''*'' --ServerApp.allow_credentials=True
Then all you need to do is click Start Notebook!
Next Steps
Once your notebook is spun up, check out the example notebooks in the /notebooks folder to get started with JAX. The TensorFlow notebooks in particular offer an interesting look at how JAX can facilitate your DL tasks.
Access the Github for this repo by clicking here.
Sources:
- https://jax.readthedocs.io/en/latest/notebooks/quickstart.html
- https://pytorch.org/docs/stable/notes/autograd.html#:~:text=Autograd is reverse automatic differentiation,roots are the output tensors.
- https://jax.readthedocs.io/en/latest/notebooks/quickstart.html?highlight=auto-vectorization#auto-vectorization-with-vmap











