The Python programming language is an interface that can be implemented in many ways. Some examples include CPython which uses the C language, Jython that is implemented using Java, and so on.
Despite being the most popular, CPython is not the fastest. PyPy is an alternate Python implementation that is both compliant and fast. PyPy depends on just-in-time (JIT) compilation that dramatically reduces the execution time for long-running operations.
In this tutorial, PyPy will be introduced for beginners to highlight how it is different from CPython. We'll also cover its advantages and limitations. Then we'll take a look at how to download and use PyPy to execute a simple Python script. PyPy supports hundreds of Python libraries, including NumPy.
Specifically, this tutorial covers the following:
- A quick overview of CPython
- Introduction to PyPy and its features
- PyPy limitations
- Running PyPy on Ubuntu
- Execution time of PyPy vs CPython
Let's get started.
Bring this project to life
A Quick Overview of CPython
Before discussing PyPy, it is important to know how CPython works. My previous tutorial titled Boosting Python Scripts With Cython gave a longer introduction to how CPython works, but it won't hurt to have a quick recap here about the important points. Below you can see a visualization of the execution pipeline of a Python script implemented using CPython.
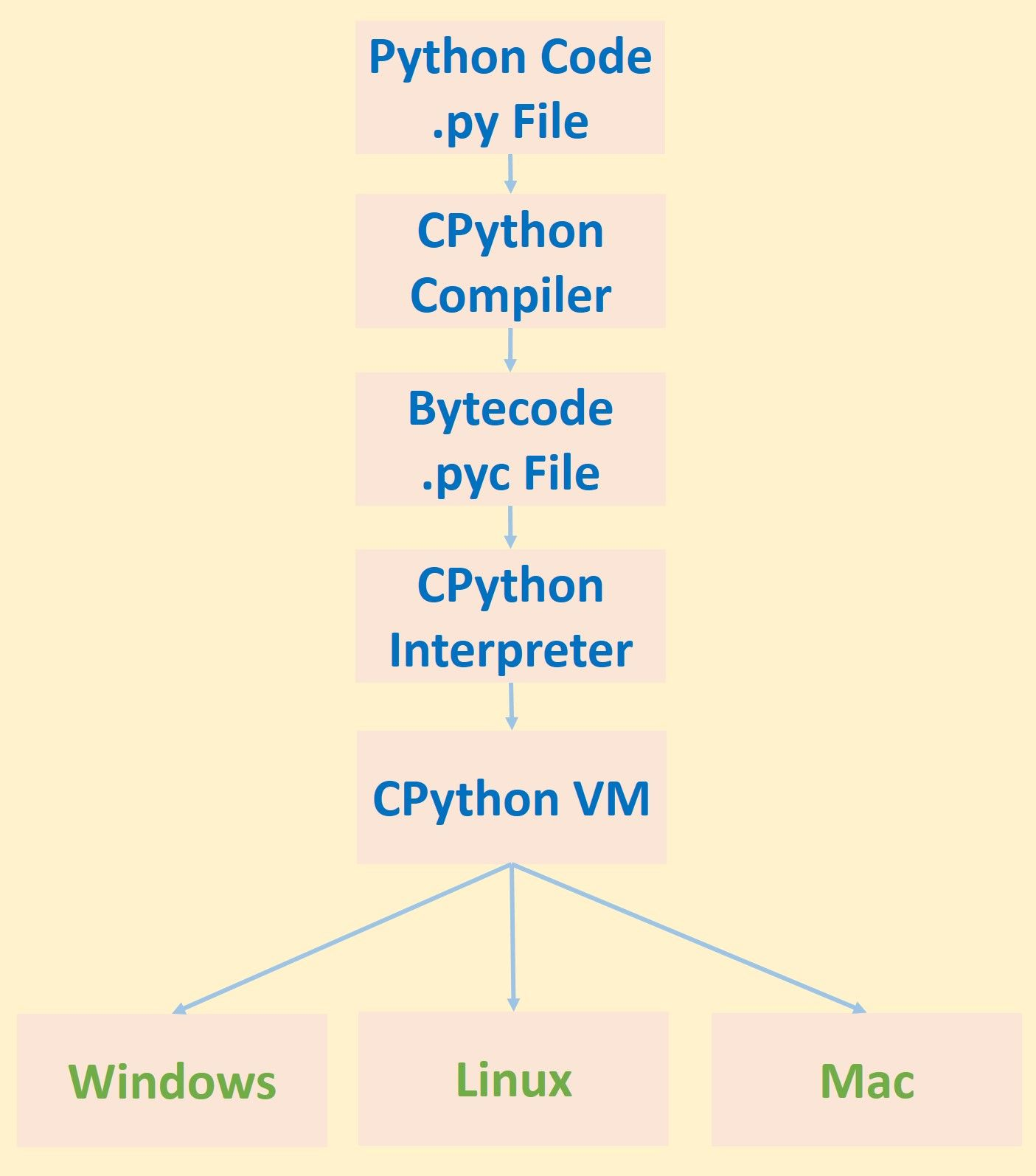
Given a Python .py script, the source code is first compiled using the CPython compiler into bytecode. The bytecode is generated and saved in a file with a .pyc extension. The bytecode is then executed using the CPython interpreter within a virtual environment.
There are benefits to using the compiler to convert the source code into bytecode. If no compiler is used, then the interpreter will work directly on the source code by translating it line by line into machine code. The disadvantage of doing this is that some processes have to be applied for translating each line of source code into machine code, and such processes will be repeated for each line. For example, syntax analysis will be applied to each line independently from the other lines, and thus the interpreter takes a lot of time to translate the code. The compiler solves this issue as it is able to process all of the code at once, and thus syntax analysis will be applied only once rather than to each line of code. The generated bytecode from the compiler will thus be interpreted easily. Note that compiling the entire source code might not be helpful in some cases, and we'll see a clear example of this when discussing PyPy.
After the bytecode is generated, it is executed by the interpreter running in the virtual machine. The virtual environment is beneficial, as it isolates the CPython bytecode from the machine, and thus makes Python cross-platform.
Unfortunately, just using a compiler to generate the bytecode is not enough to speed up the execution of CPython. The interpreter works by translating the code, each time it is executed, into machine code. Thus, if a line L takes X seconds to be executed, then executing it 10 times will have a cost of X*10 seconds. For long-running operations, this is too costly in its execution time.
Based on the drawbacks of CPython, let's now take a look at PyPy.
Introduction to PyPy and its Features
PyPy is a Python implementation similar to CPython that is both compliant and fast. "Compliant" means that PyPy is compatible with CPython, as you can use nearly all CPython syntax in PyPy. There are some compatibility differences, as mentioned here. The most powerful advantage of PyPy is its speed. PyPy is much faster than CPython; we'll see tests later on where PyPy performs about 7 times faster. In some cases it might even be tens or hundreds of times faster than CPython. So how does PyPy achieve its speed?
Speed
PyPy uses a just-in-time (JIT) compiler that is able to dramatically increase the speed of Python scripts. The type of compilation used in CPython is ahead-of-time (AOT), meaning that all of the code will be translated into bytecode before being executed. JIT just translates the code at runtime, only when it is needed.
The source code might contain code blocks that are not executed at all, but which are still being translated using the AOT compiler. This leads to slower processing times. When the source code is large and contains thousands of lines, using a JIT makes a big difference. For AOT, the entire source code will be translated and thus take a lot of time. For JIT, just the needed parts of the code will be executed, making it a lot faster.
After PyPy translates a part of the code, it then gets cached. This means the code is translated only once, and then the translation is used later. The CPython interpreter repeats the translation each time the code is executed, an additional cause for its slowness.
Effortless
PyPy is not the only way to boost the performance of Python scripts—but it is the easiest way. For example, Cython could be used to increase the speed of assigning C types to the variables. The problem is that Cython asks the developer to manually inspect the source code and optimize it. This is tiresome, and the complexity increases as the code size increases. When PyPy is used, you just run the regular Python code much faster without any effort at all.
Stackless
Standard Python uses the C stack. This stack stores the sequence of functions that are called from each other (recursion). Because the stack size is limited, you are limited in the number of function calls.
PyPy uses Stackless Python, a Python implementation that does not use the C stack. Instead, it stores the function calls in the heap alongside the objects. The heap size is greater than the stack size, and thus you can do more function calls.
Stackless Python also supports microthreads, which are better than regular Python threads. Within the single Stackless Python thread you can run thousands of tasks, called "tasklets," with all of them running on the same thread.
Using tasklets allows running concurrent tasks. Concurrency means that two tasks work simultaneously by sharing the same resources. One task runs for some time, then stops to make room for the second task to be executed. Note that this is different from parallelism, which involves running the two tasks separately but at the same time.
Using tasklets reduces the number of threads created, and thus reduces the overhead of managing all these threads by the OS. As a result, speeding up the execution by swapping between two threads is more time-intensive than swapping between two tasklets.
Using Stackless Python also opened the door for implementing continuations. Continuations allow us to save the state of a task and restore it later to continue its job. Note that Stackless Python is not different from Standard Python; it just adds more functionalities. Everything available in Standard Python will be available in Stackless Python, too.
After discussing the benefits of PyPy, let's talk about its limitations in the next section.
PyPy Limitations
While you can use CPython on any machine and any CPU architecture, PyPy has comparably limited support.
Here are the CPU architectures supported and maintained by PyPy (source):
- x86 (IA-32) and x86_64
- ARM platforms (ARMv6 or ARMv7, with VFPv3)
- AArch64
- PowerPC 64bit, both little and big endian
- System Z (s390x)
PyPy cannot work on all Linux distributions, so you have to take care to use one that's supported. Running PyPy Linux binary on an unsupported distribution will return an error. PyPy only supports one version of Python 2 and Python 3, which are PyPy 2.7 and PyPy 3.6.
If the code that is executed in PyPy is pure Python, then the speed offered by PyPy is usually noticeable. But if the code contains C extensions, such as NumPy, then PyPy might actually increase the time. The PyPy project is actively developed and thus may offer better support for C extensions in the future.
PyPy is not supported by a number of popular Python frameworks, such as Kivy. Kivy allows CPython to run on all platforms, including Android and iOS. This means that PyPy cannot run on mobile devices.
Now that we've seen the benefits and limitations of PyPy, let's cover how to run PyPy on Ubuntu.
Running PyPy on Ubuntu
You can run PyPy on either Mac, Linux, or Windows, but we are going to discuss running it on Ubuntu. It is very important to mention again that PyPy Linux binaries are only supported on specific Linux distributions. You can check the available PyPy binaries and their supported distributions on this page. For example, PyPy (either Python 2.7 or Python 3.6) is only supported for three versions of Ubuntu: 18.04, 16.04 and 14.04. If you have the newest version of Ubuntu up to this date (19.10), then you cannot run PyPy on it. Trying to run PyPy on an unsupported distribution will return this error:
pypy: error while loading shared libraries ...
I simply use a virtual machine to run Ubuntu 18.04.
The PyPy binaries come as compressed files. All you need to do is to decompress the file you downloaded. Inside the decompressed directory there is a folder named bin, in which the PyPy executable file can be found. I am using Python 3.6 and thus the file is named pypy3. For Python 2.7, it's just called pypy.
For CPython, if you would like to run Python 3 from the terminal, you simply enter the command python3. To run PyPy, simply issue the command pypy3.
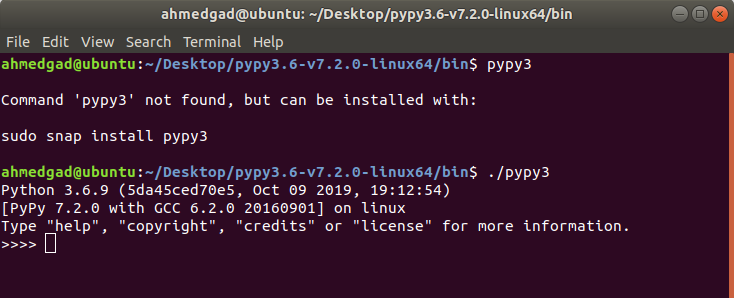
Entering the pypy3 command in the terminal might return the Command 'pypy3' not found message, as shown in the next figure. The reason is that the path of PyPy is not added to the PATH environment variable. The command that actually works is ./pypy3, taking into regard that the current path of the terminal is inside the bin directory of PyPy. The dot . refers to the current directory, and / is added to access something within the current directory. Issuing the ./pypy3 command runs Python successfully as given below.
You can now work with Python as usual, taking advantage of the benefits of PyPy. For example, we can create a simple Python script that sums 1,000 numbers and execute it using PyPy. The code is as follows.
nums = range(1000)
sum = 0
for k in nums:
sum = sum + k
print("Sum of 1,000 numbers is : ", sum)If this script is named test.py, then you can simply run it using the following command (assuming that the Python file is located inside the bin folder of PyPy, which is the same location of the pypy3 command).
./pypy3 test.pyThe next figure shows the result of executing the previous code.

Execution Time of PyPy vs. CPython
To compare the runtime of PyPy and CPython for summing 1,000 numbers, the code is changed to measure the time as follows.
import time
t1 = time.time()
nums = range(1000)
sum = 0
for k in nums:
sum = sum + k
print("Sum of 1,000 numbers is : ", sum)
t2 = time.time()
t = t2 - t1
print("Elapsed time is : ", t, " seconds")For PyPy the time is nearly 0.00045 seconds, compared to 0.0002 seconds for CPython (I ran the code on my Core i7-6500U machine @ 2.5GHz). In this case CPython takes less time compared to PyPy, which is to be expected since this task is not really a long-running task. If the code is changed to add 1 million numbers, rather than 1 thousand, then PyPy would end up winning. In this case it takes 0.00035 seconds for Pypy and 0.1 seconds for CPython. The benefit of PyPy is now obvious. This should give you an idea of how much slower CPython is for executing long-running tasks.
Conclusion
This tutorial introduced PyPy, the fastest Python implementation. The major benefit of PyPy is its just-in-time (JIT) compilation, which offers caching of the compiled machine code to avoid executing it again. The limitations of PyPy are also highlighted, the major one being that it works well for pure Python code but is not efficient for C extensions.
We also saw how to run PyPy on Ubuntu and compared the runtime of both CPython and PyPy, highlighting PyPy's efficiency for long-running tasks. Meanwhile, CPython might still beat out PyPy for short-running tasks. In future articles we'll explore more comparisons between PyPy, CPython, and Cython.