
In recent years, zero-shot object detection has become a cornerstone of advancements in computer vision. Creating versatile and efficient detectors has been a significant focus on building real-world applications. The introduction of Grounding DINO 1.5 by IDEA Research marks a significant leap forward in this field, particularly in open-set object detection.
We will run the demo using Paperspace GPUs, a platform known for offering high-performance computing resources for various applications. These GPUs are designed to meet the needs of machine learning, deep learning, and data analysis and provide scalable and flexible computing power without needing physical hardware investments.
Paperspace offers a range of GPU options to suit different performance requirements and budgets, allowing users to accelerate their computational workflows efficiently. Additionally, the platform integrates with popular tools and frameworks, making it easier for developers and researchers to deploy, manage, and scale their projects.
What is Grounding DINO?
Grounding DINO, an open-set detector based on DINO, not only achieved state-of-the-art object detection performance but also enabled the integration of multi-level text information through grounded pre-training. Grounding DINO offers several advantages over GLIP or Grounded Language-Image Pre-training. Firstly, its Transformer-based architecture, similar to language models, facilitates processing both image and language data.
Grounding DINO Framework
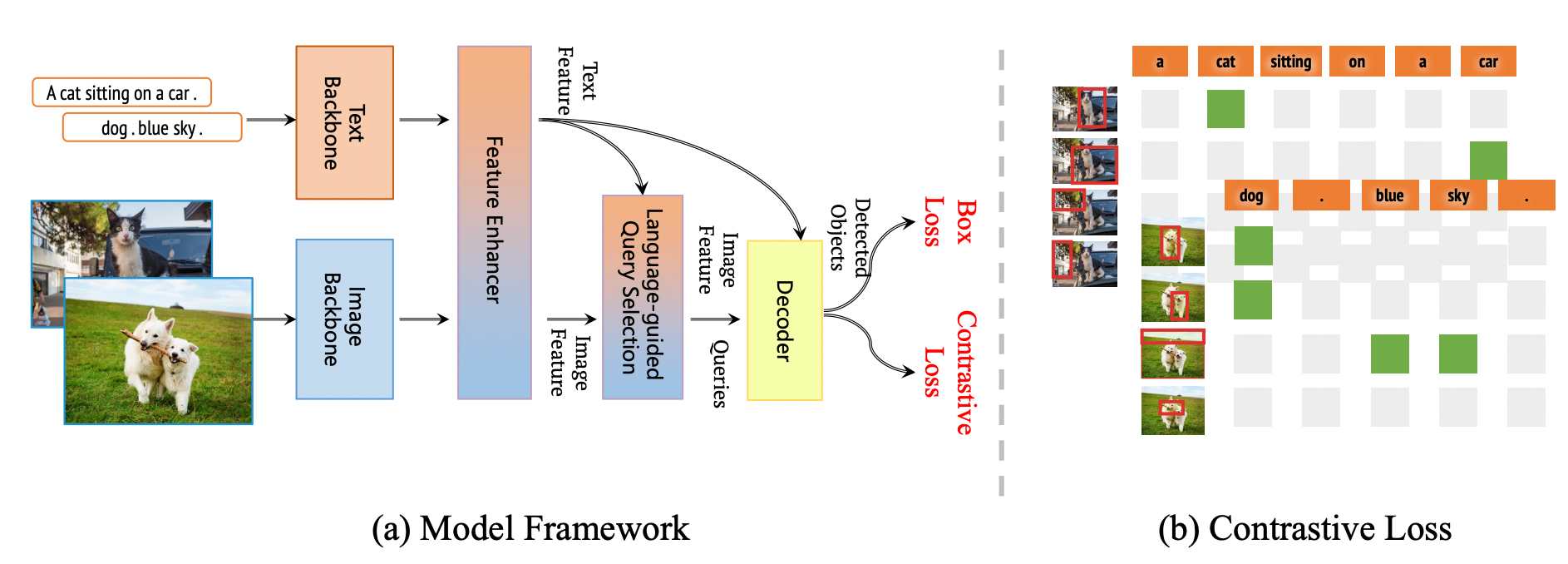
The framework shown in the above image is the overall framework of the Grounding DINO 1.5 series. This framework retains the dual-encoder-single-decoder structure of Grounding DINO. Further, this framework extends it to Grounding DINO 1.5 for both the Pro and Edge models.
Grounding DINO combines concepts from DINO and GLIP. DINO, a transformer-based method, excels in object detection with end-to-end optimization, removing the need for handcrafted modules like Non-Maximum Suppression or NMS. Conversely, GLIP focuses on phrase grounding, linking words or phrases in text to visual elements in images or videos.
Grounding DINO's architecture consists of an image backbone, a text backbone, a feature enhancer for image-text fusion, a language-guided query selection module, and a cross-modality decoder for refining object boxes. Initially, it extracts image and text features, fuses them, selects queries from image features, and uses these queries in a decoder to predict object boxes and corresponding phrases.
Bring this project to life
What's new in Grounding DINO 1.5?
Grounding DINO 1.5 builds upon the foundation laid by its predecessor, Grounding DINO, which redefined object detection by incorporating linguistic information and framing the task as phrase grounding. This innovative approach leverages large-scale pre-training on diverse datasets and self-training on pseudo-labeled data from an extensive pool of image-text pairs. The result is a model that excels in open-world scenarios due to its robust architecture and semantic richness.
Grounding DINO 1.5 extends these capabilities even further, introducing two specialized models: Grounding DINO 1.5 Pro and Grounding DINO 1.5 Edge. The Pro model enhances detection performance by significantly expanding the model's capacity and dataset size, incorporating advanced architectures like the ViT-L, and generating over 20 million annotated images. In contrast, the Edge model is optimized for edge devices, emphasizing computational efficiency while maintaining high detection quality through high-level image features.
Experimental findings underscore the effectiveness of Grounding DINO 1.5, with the Pro model setting new performance standards and the Edge model showcasing impressive speed and accuracy, rendering it highly suitable for edge computing applications. This article delves into the advancements brought by Grounding DINO 1.5, exploring its methodologies, impact, and potential future directions in the dynamic landscape of open-set object detection, thereby highlighting its practical applications in real-world scenarios.
Grounding DINO 1.5 is pre-trained on Grounding-20M, a dataset of over 20 million grounding images from public sources. During the training process, high-quality annotations with well-developed annotation pipelines and post-processing rules are ensured.
Performance Analysis
The figure below shows the model's ability to recognize objects in datasets like COCO and LVIS, which contain many categories. It indicates that Grounding DINO 1.5 Pro significantly outperforms previous versions. Compared to a specific previous model, Grounding DINO 1.5 Pro shows a remarkable improvement.
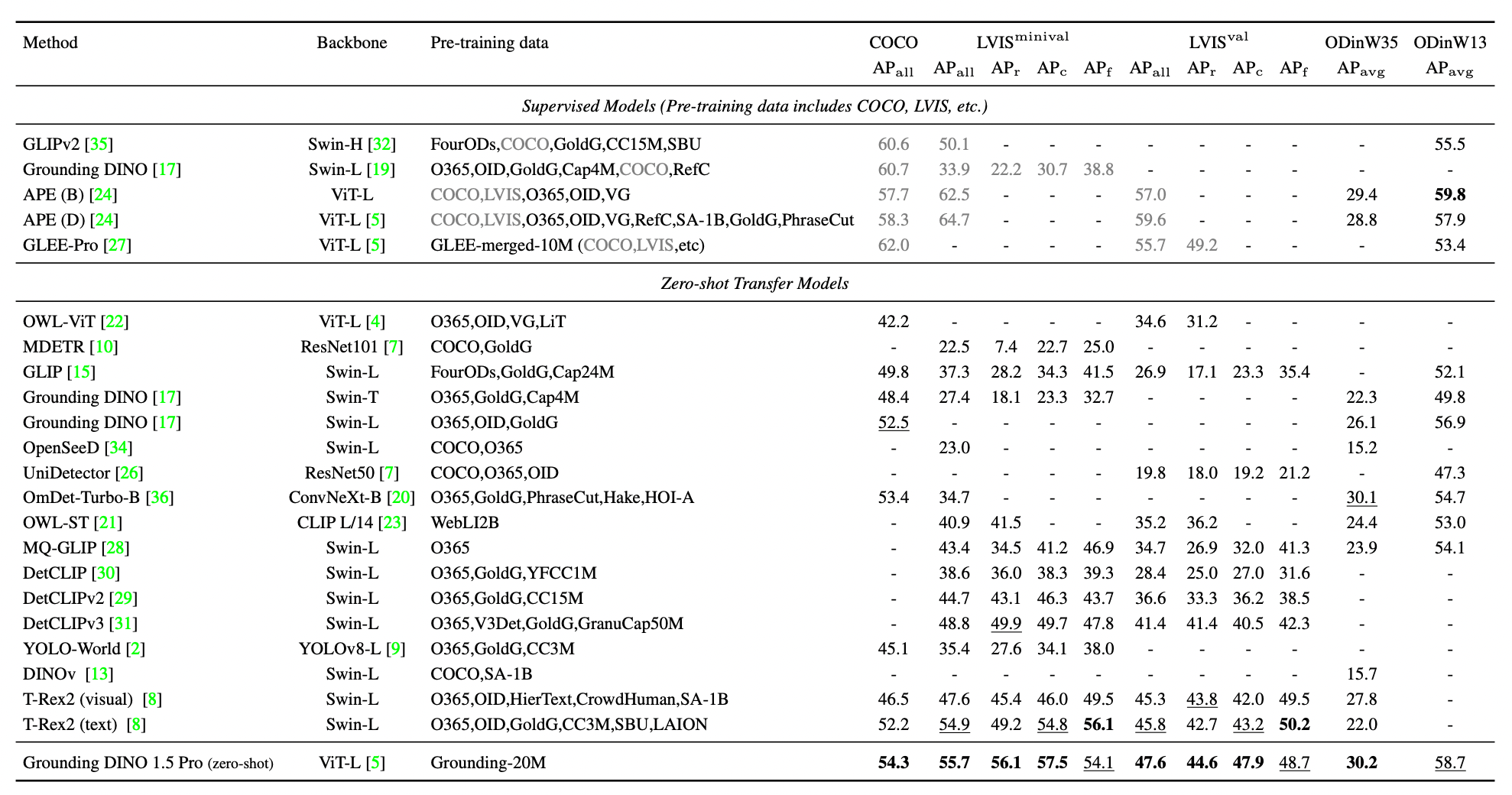
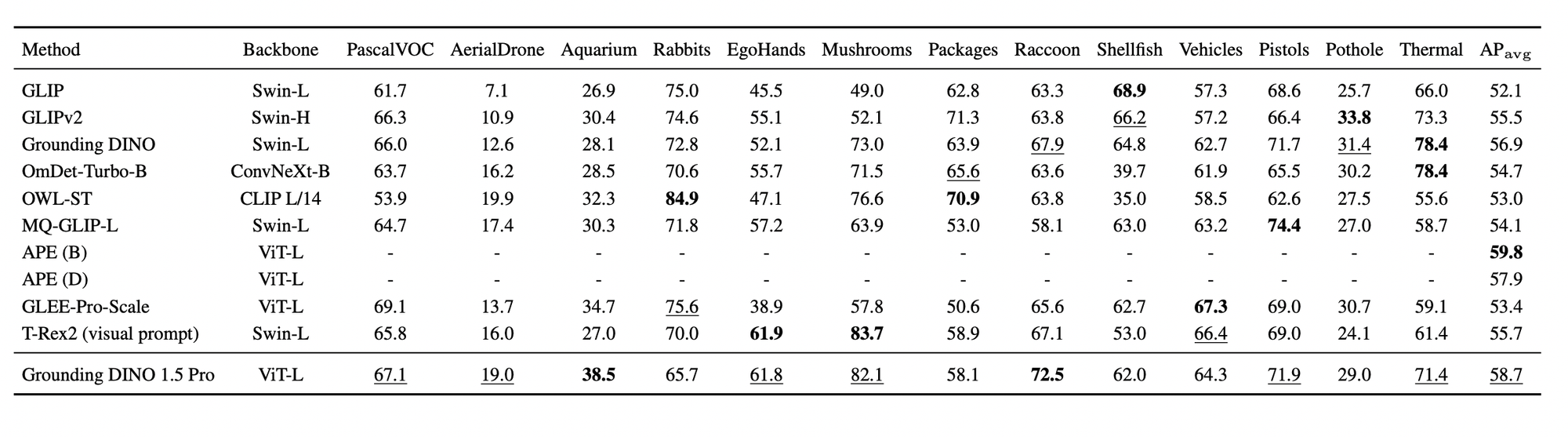
The model was tested in various real-world scenarios using the ODinW (Object Detection in the Wild) benchmark, which includes 35 datasets covering different applications. Grounding DINO 1.5 Pro achieved significantly improved performance over the previous version of Grounding DINO.
Zero-shot results for Grounding DINO 1.5 Edge on COCO and LVIS are measured in frames per second (FPS) using an A100 GPU, reported in PyTorch speed / TensorRT FP32 speed. FPS on NVIDIA Orin NX is also provided. Grounding DINO 1.5 Edge achieves remarkable performance and also surpasses all other state-of-the-art algorithms (OmDet-Turbo-T 30.3 AP, YOLO-Worldv2-L 32.9 AP, YOLO-Worldv2-M 30.0 AP, YOLO-Worldv2-S 22.7 AP).
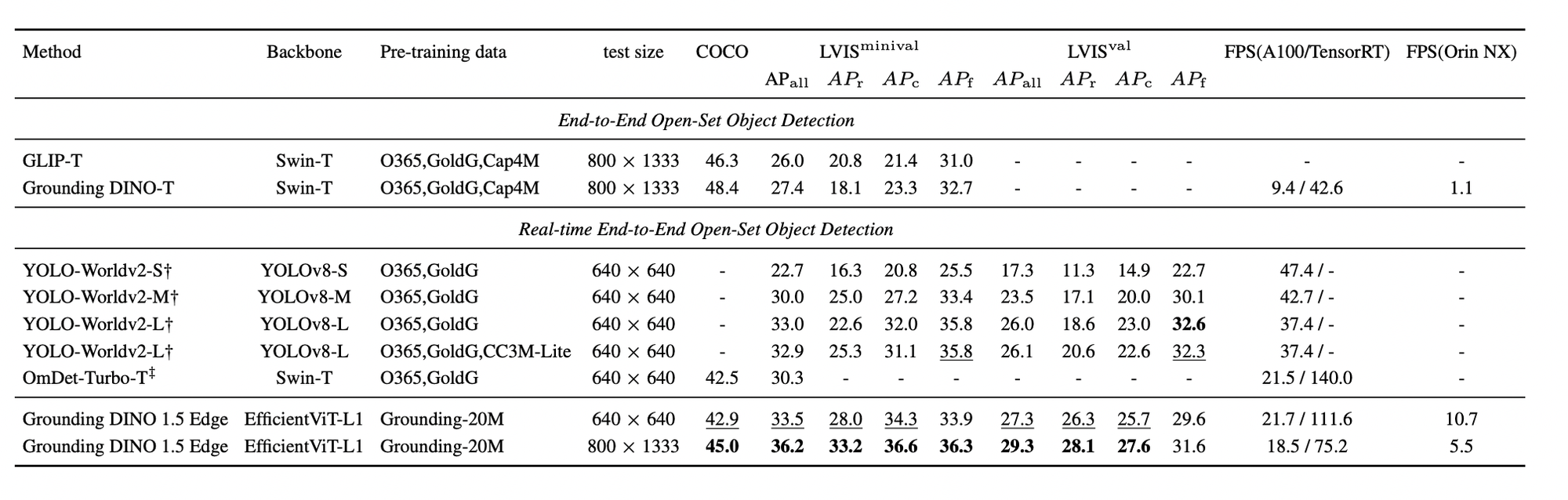
Grounding DINO 1.5 Pro and Grounding DINO 1.5 Edge
Grounding DINO 1.5 Pro
Grounding DINO 1.5 Pro builds on the core architecture of Grounding DINO but enhances the model architecture with a larger Vision Transformer (ViT-L) backbone. The ViT-L model is known for its exceptional performance on various tasks, and the transformer-based design aids in optimizing training and inference.
One of the key methodologies Grounding DINO 1.5 Pro adopts is a deep early fusion strategy for feature extraction. This means that language and image features are combined early on using cross-attention mechanisms during the feature extraction process before moving to the decoding phase. This early integration allows for a more thorough fusion of information from both modalities.
In their research, the team compared early fusion with later fusion strategies. In early fusion, language, and image features are integrated early in the process, leading to higher detection recall and more accurate bounding box predictions. However, this approach can sometimes cause the model to hallucinate, meaning it predicts objects that aren't present in the images.
On the other hand, late fusion keeps language and image features separate until the loss calculation phase, where they are integrated. This approach is generally more robust against hallucinations but tends to result in lower detection recall because aligning vision and language features becomes more challenging when they are only combined at the end.
To maximize the benefits of early fusion while minimizing its drawbacks, Grounding DINO 1.5 Pro retains the early fusion design but incorporates a more comprehensive training sampling strategy. This strategy increases the proportion of negative samples—images without the objects of interest—during training. By doing so, the model learns to distinguish between relevant and irrelevant information better, thereby reducing hallucinations while maintaining high detection recall and accuracy.
In summary, Grounding DINO 1.5 Pro enhances its prediction capabilities and robustness by combining early fusion with an improved training approach that balances the strengths and weaknesses of early fusion architecture.
Grounding DINO 1.5 Edge
Grounding DINO is a powerful model for detecting objects in images, but it requires a lot of computing power. This makes it challenging to use on small devices with limited resources, like those in cars, medical equipment, or smartphones. These devices need to process images quickly and efficiently in real time.
Deploying Grounding DINO on edge devices is highly desirable for many applications, such as autonomous driving, medical image processing, and computational photography.
However, open-set detection models typically require significant computational resources, which edge devices lack. The original Grounding DINO model uses multi-scale image features and a computationally intensive feature enhancer. While this improves the training speed and performance, it is impractical for real-time applications on edge devices.
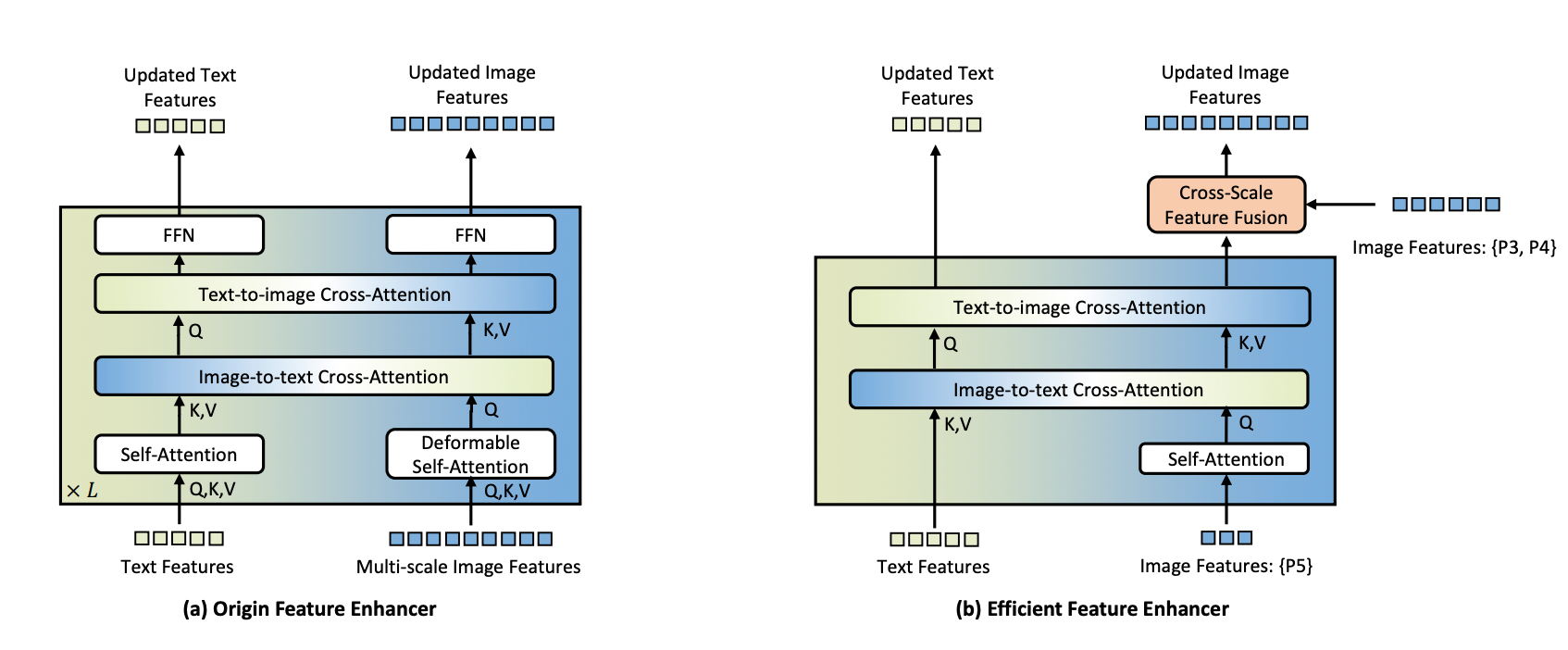
To address this challenge, the researchers propose an efficient feature enhancer for edge devices. Their approach focuses on using only high-level image features (P5 level) for cross-modality fusion, as lower-level features lack semantic information and increase computational costs. This method significantly reduces the number of tokens processed, cutting the computational load.
For better integration on edge devices, the model replaces deformable self-attention with vanilla self-attention and introduces a cross-scale feature fusion module to integrate lower-level image features (P3 and P4 levels). This design balances the need for feature enhancement with the necessity for computational efficiency.
In Grounding DINO 1.5 Edge, the original feature enhancer is replaced with this new efficient enhancer, and EfficientViT-L1 is used as the image backbone for rapid multi-scale feature extraction. When deployed on the NVIDIA Orin NX platform, this optimized model achieves an inference speed of over 10 FPS with an input size of 640 × 640. This makes it suitable for real-time applications on edge devices, balancing performance and efficiency.

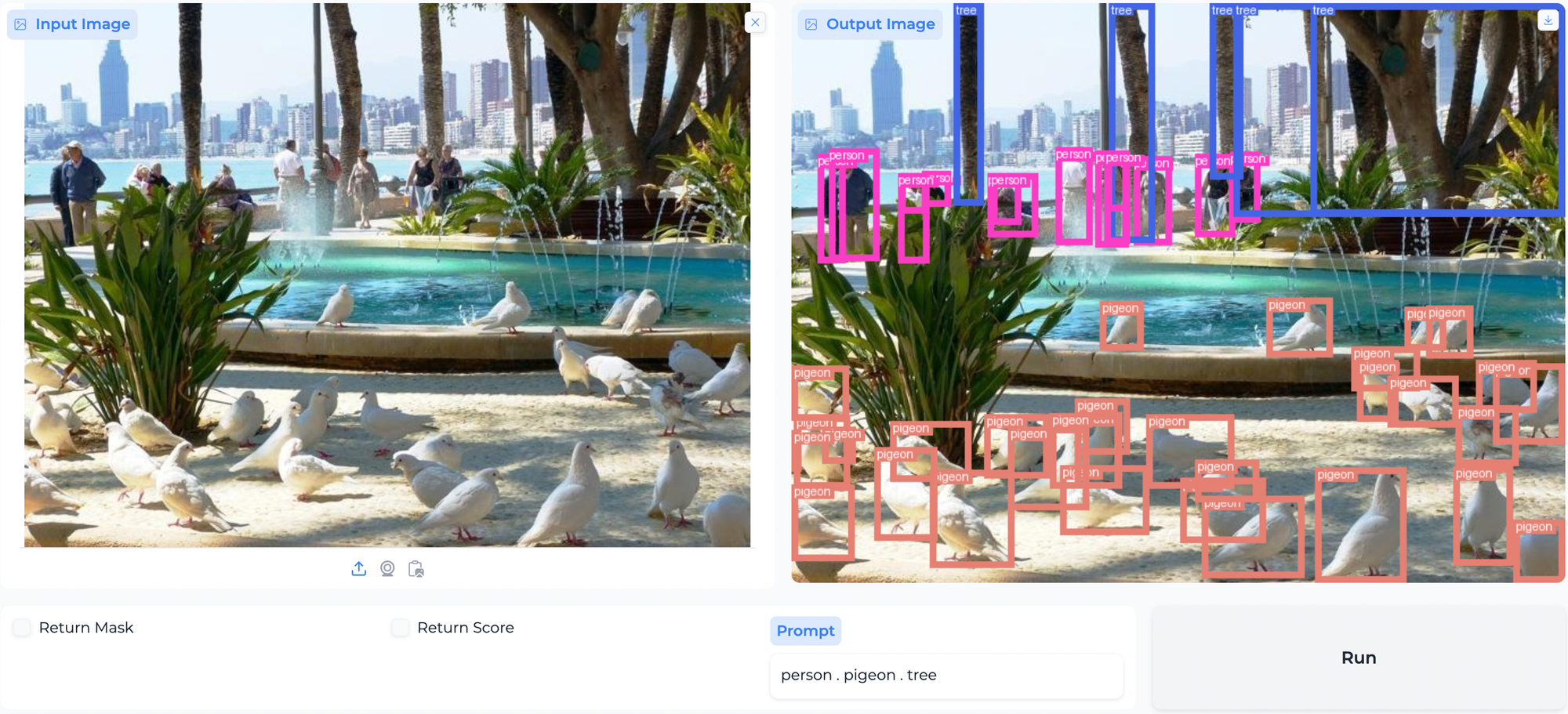
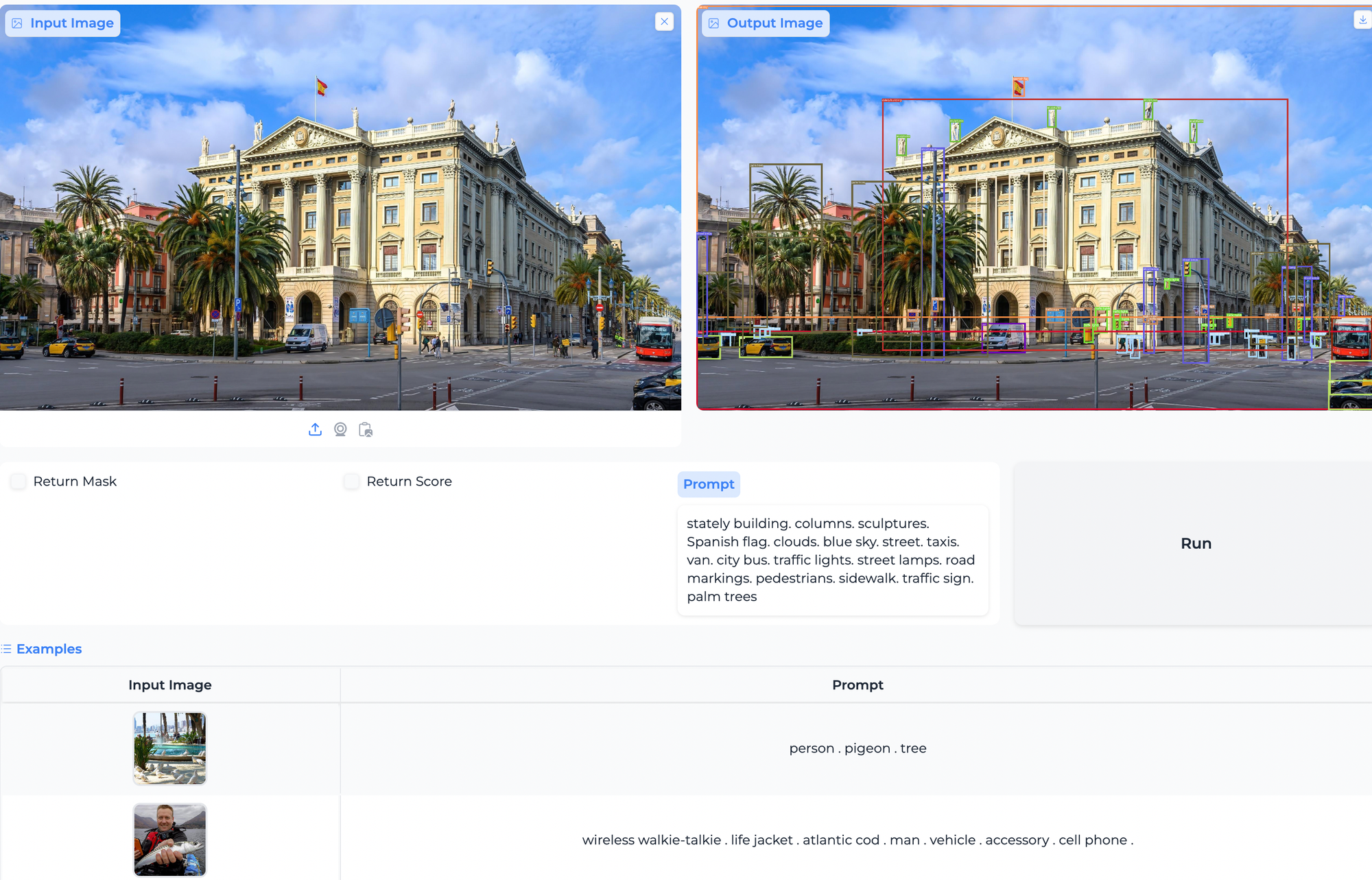
Object Detection and Paperspace Demo
Bring this project to life
Please make sure to request DeepDataSpace to get the API key. Please refer to the DeepDataSpace for API keys: https://deepdataspace.com/request_api.
To run this demo and start your experimentation with the model, we have created and added a Jupyter notebook with this article so that you can test it.
First, we will clone the repository:
!git clone https://github.com/IDEA-Research/Grounding-DINO-1.5-API.git
Next, we will install the required packages:
!pip install -v -e .Run the code below to generate the link:
!python gradio_app.py --token ad6dbcxxxxxxxxxx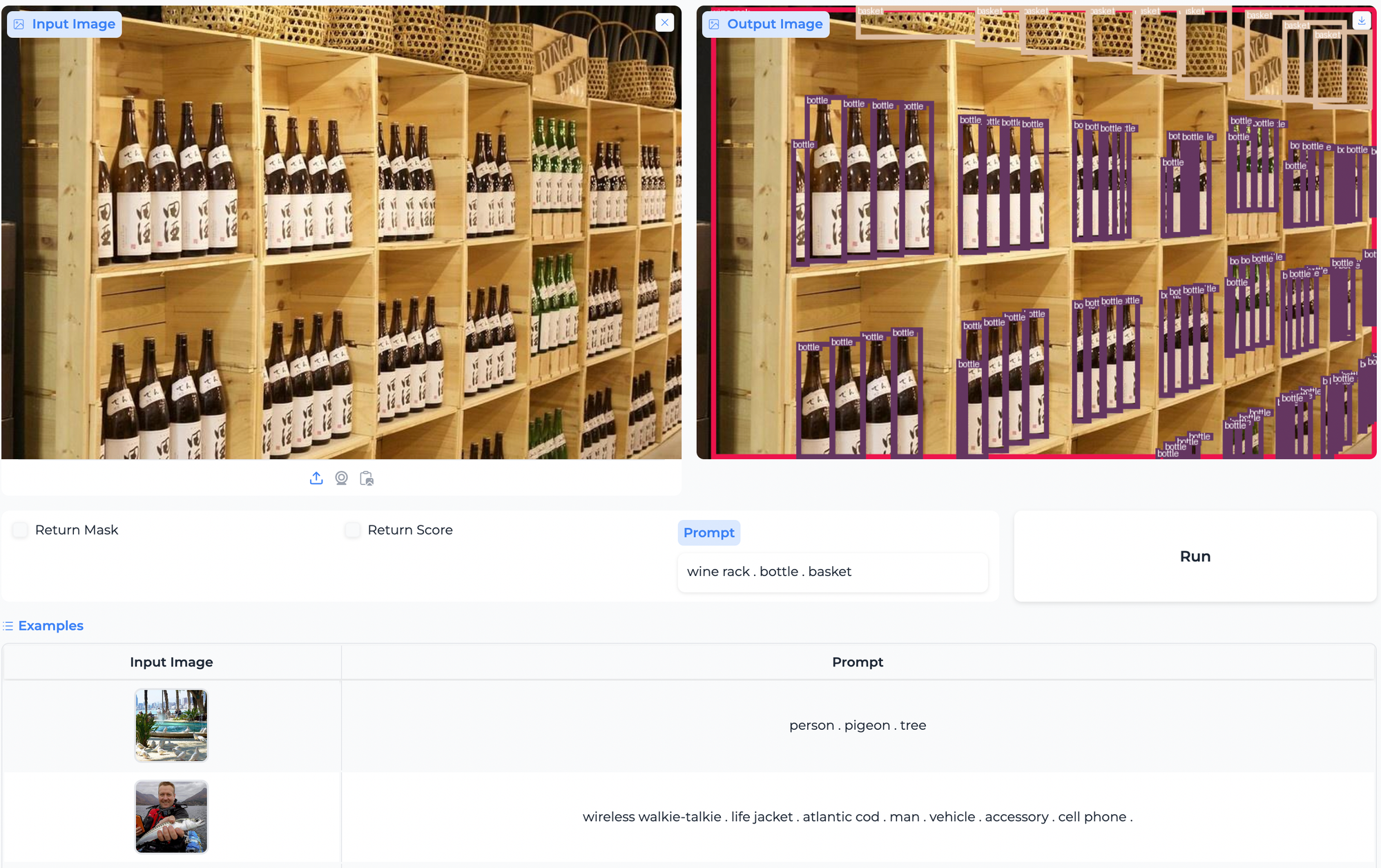
Real-World Application and Concluding Thoughts on Grounding DINO 1.5
- Autonomous Vehicles:
- Detecting and recognizing known traffic signs and pedestrians and unfamiliar objects that might appear on the road, ensuring safer navigation.
- Identifying unexpected obstacles, such as debris or animals, that are not pre-labeled in the training data.
- Surveillance and Security:
- Recognizing unauthorized individuals or objects in restricted areas, even if they haven't been seen before.
- Detecting abandoned objects in public places, such as airports or train stations, could be potential security threats.
- Retail and Inventory Management:
- Identifying and tracking items on store shelves, including new products that may not have been part of the original inventory.
- Recognizing unusual activities or unfamiliar objects in a store that could indicate shoplifting.
- Healthcare:
- Detecting anomalies or unfamiliar patterns in medical scans, such as new types of tumors or rare conditions.
- Identifying unusual patient behaviors or movements, especially in long-term care or post-surgery recovery.
- Robotics:
- Enabling robots to operate in dynamic and unstructured environments by recognizing and adapting to new objects or changes in their surroundings.
- Detecting victims or hazards in disaster-stricken areas where the environment is unpredictable and filled with unfamiliar objects.
- Wildlife Monitoring and Conservation:
- Detecting and identifying new or rare species in natural habitats for biodiversity studies and conservation efforts.
- Monitoring protected areas for unfamiliar human presence or tools that could indicate illegal poaching activities.
- Manufacturing and Quality Control:
- Identifying defects or anomalies in products on a production line, including new types of defects not previously encountered.
- Recognizing and sorting a wide variety of objects to improve efficiency in manufacturing processes.
This article introduces Grounding DINO 1.5, designed to enhance open-set object detection. The leading model, Grounding DINO 1.5 Pro, has set new benchmarks on the COCO and LVIS zero-shot tests, marking significant progress in detection accuracy and reliability.
Additionally, the Grounding DINO 1.5 Edge model supports real-time object detection across diverse applications, broadening the series' practical applicability.
We hope you have enjoyed reading the article!










