

What is IDEFICS visual language model?
IDEFICS (Image-aware Decoder Enhanced à la Flamingo with Interleaved Cross-attentionS) is an open-access version of Deepmind's visual language model, Flamingo. It processes sequences of images and text, producing text outputs, and can answer questions about images, describe visual content, and create stories based on images.
Built with publicly available data and models, IDEFICS matches the original Flamingo on various benchmarks like visual question answering, image captioning, and image classification. Available in two sizes, 80 billion and 9 billion parameters, it also comes in fine-tuned versions, idefics-80b-instruct and idefics-9b-instruct, which enhance performance and usability in conversational contexts.
Key difference between IDEFICS1 and IDEFICS2
- Idefics2 surpasses Idefics1 with 8 billion parameters and the flexibility of an Apache 2.0 open license.
- The images are manipulated at their native resolutions (up to 980 x 980) and aspect ratios using the NaViT strategy, avoiding the need to resize them to fixed squares. Additionally, more advanced techniques from SPHINX are incorporated to allow sub-image splitting and processing of high-resolution images.
- The OCR capabilities have been greatly enhanced with data for transcribing text from images and documents. Also, the model's ability to answer questions about charts, figures, and documents has improved in IDEFICS2.
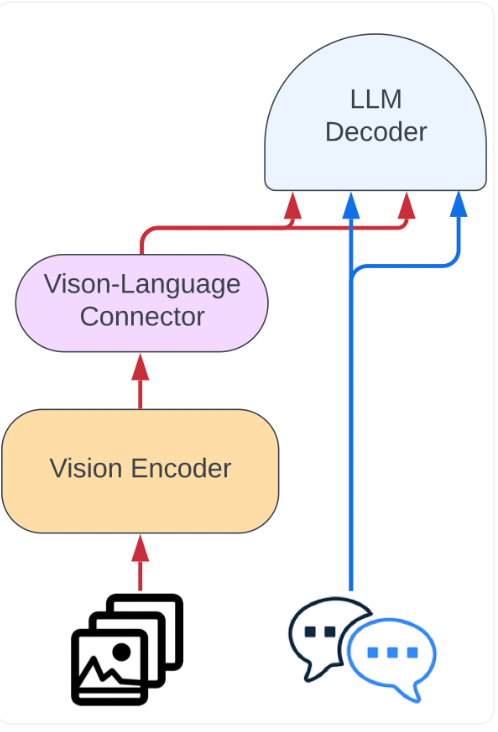
- Unlike Idefics1, the architecture is simplified by feeding images to the vision encoder, followed by Perceiver pooling and an MLP modality projection. This pooled sequence is combined with text embeddings to seamlessly integrate images and text.
These enhancements and better pre-trained backbones result in a significant performance boost over Idefics1, even though the new model is 10 times smaller.
In this article, we will use Paperspace, a cloud computing platform that offers a range of powerful GPUs designed to handle intensive computational tasks such as machine learning, deep learning, and high-performance computing.
The GPUs offered by Paperspace enable researchers and developers to efficiently scale their models efficiently, ensuring faster training times and more accurate results. With Paperspace, users can seamlessly access these high-powered GPUs in the cloud, providing the flexibility and scalability needed for demanding computational tasks.
Image tasks with IDEFICS
While specialized models can be fine-tuned for specific tasks, this new and popular approach uses large models to handle diverse tasks without fine-tuning. Large language models, for example, can perform summarization, translation, and classification. This method now extends beyond text to multimodal tasks.
In this article, we'll show you how to use the IDEFICS model for image-text tasks.
IDEFICS processes sequences of images and text to generate coherent text outputs, such as answering questions about images, describing visual content, and creating stories from multiple images. IDEFICS comes in two versions: 80 billion and 9 billion parameters, with fine-tuned versions for conversational use.
Paperspace Demo
Bring this project to life
This model's exceptional versatility allows it to handle various image and multimodal tasks. However, its large size necessitates substantial computational resources and infrastructure.
In this demo, we will use the model to answer visual questions.
Let us start by installing the necessary packages and loading the model’s 9 billion parameters model checkpoint:
%pip install -U transformers \
datasets==2.14.4 \
diffusers==0.20.0 \
accelerate==0.21.0 \
torch==2.0.1 \
torchvision==0.15.2 \
sentencepiece==0.1.99Once the installation is done, we will move to the next steps to set up the model and processor for performing vision-text tasks using the IdeficsForVisionText2Text model from Hugging Face.
import torch
from transformers import IdeficsForVisionText2Text, AutoProcessor
device = "cuda" if torch.cuda.is_available() else "cpu"
model_name = "HuggingFaceM4/idefics-9b-instruct"
model = IdeficsForVisionText2Text.from_pretrained(model_name, torch_dtype=torch.bfloat16).to(device)
processor = AutoProcessor.from_pretrained(model_name)
# Generation args
exit_condition = processor.tokenizer("<end_of_utterance>", add_special_tokens=False).input_ids
bad_words_ids = processor.tokenizer(["<image>", "<fake_token_around_image>"], add_special_tokens=False).input_ids
We will set the data type for the model to bfloat16, a lower-precision format to save memory and potentially increase speed.
Next, we will use an image for our task,
from PIL import Image
img = Image.open("dog.jpg")
img
prompt = [
"User:",
img,
"Describe this image."
"Assistant:",
]
inputs = processor(prompt, return_tensors="pt").to("cuda")
generated_ids = model.generate(**inputs, eos_token_id = exit_condition, max_new_tokens=100, bad_words_ids=bad_words_ids)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(generated_text)
Output:-
'User: Describe this image. Assistant: The image shows two golden retriever puppies sitting in a field of flowers. They are sitting next to each other, looking at the camera, and appear to be very happy. The puppies are adorable, and their fur is a beautiful golden color. The flowers surrounding them are yellow and add a vibrant touch to the scene.'
It is a good idea to include the bad_words_ids in the call to generate to avoid errors arising when increasing the max_new_tokens: the model will want to generate a new
or <fake_token_around_image> token when there is no image being generated by the model. You can set it on-the-fly as in this guide, or store in the GenerationConfig as described in the Text generation strategies guide. -Source Hugging Face
IDEFICS Training Data
Idefics2 was trained on a mix of publicly available datasets, including web documents (like Wikipedia and OBELICS), image-caption pairs (from LAION-COCO), OCR data, and image-to-code data.
To enhance the base model, the model is further trained on task-oriented data, which is often scattered and in various formats, posing a challenge for the community.
Conclusion
In this article we explored IDEFICS2, a versatile multimodal model that handles sequences of text and images, generating text responses. It can answer image-related questions and describe visuals.
Idefics2 is a major upgrade from Idefics1, boasting 8 billion parameters, an Apache 2.0 open license. It's a powerful tool for those working on multimodal projects. With Idefics2 already integrated into Transformers, it's easy to fine-tune for various multimodal applications. You can try it out with Paperspace today!
We explored the model performance with visual question answering, and the model performed quite decently.
We hope you enjoyed reading the article and exploring the model further with Paperspace.
References
To further understand the model, we have provided the resources below:-
- Idefics2 collection
- Idefics2 model with model card
- Idefics2-base model with model card
- The Cauldron with its dataset card
- OBELICS with its dataset card
- WebSight with its dataset card
- Idefics2 fine-tuning colab
- Idefics2-8B model demo (not the chatty model)
- Introducing Idefics2: A Powerful 8B Vision-Language Model for the community
- HuggingFaceM4/idefics-9b-instruct
- Image tasks with IDEFICS










