We're excited to announce a new collaboration with Hugging Face to provide state-of-the-art NLP tools to the community.
Check out the Webinar, and run the new notebooks on a free GPU.
Gradient + Hugging Face
The new Transformers container makes it simple to deploy cutting-edge NLP techniques in research and production. All dependencies are pre-installed, which means individual developers and teams can hit the ground running without the stress of tooling or compatibility issues.

Demo notebooks available in the ML Showcase provide an overview of how these libraries can be used.
The Transformers Library
The Transformers library provides state-of-the-art NLP for both TensorFlow 2.0 and PyTorch. This is an open-source, community-based library for training, using, and sharing models based on the Transformer architecture, including BERT, RoBERTa, GPT2, XLNet, and more.
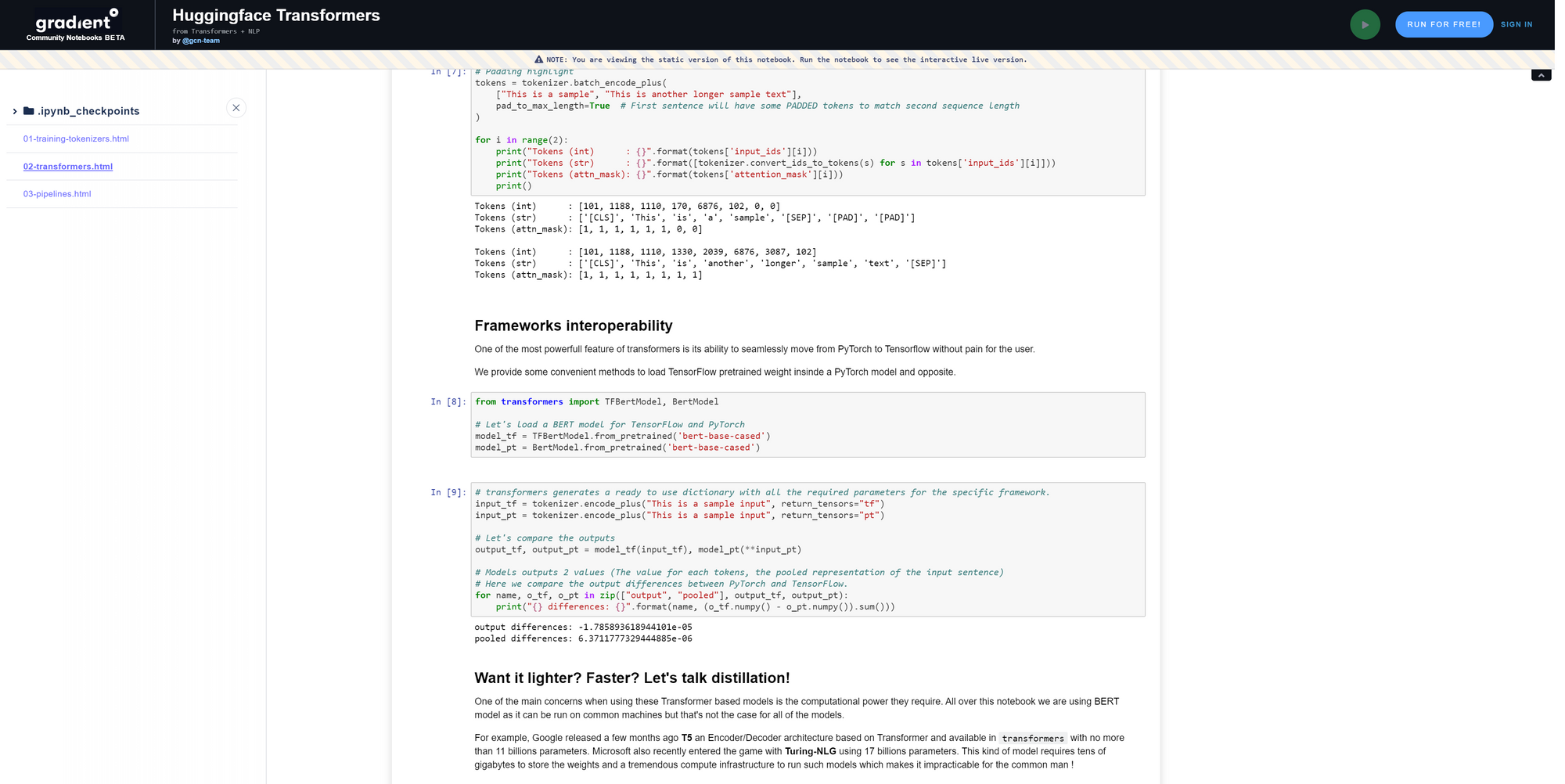
Along with the models themselves, the library also contains multiple variations for many downstream tasks like Named Entity Recognition (NER), Sentiment Analysis, Language Modeling, Question Answering, and so on.
The Transformers library allows you to benefit from large, pre-trained language models without requiring costly computational infrastructure. Load and use pre-trained models in a couple lines of code, and seamlessly move models between either PyTorch or Tensorflow.
The Tokenizers Library
The Tokenizers library provides fast, state-of-the-art tokenization optimized for research and production.
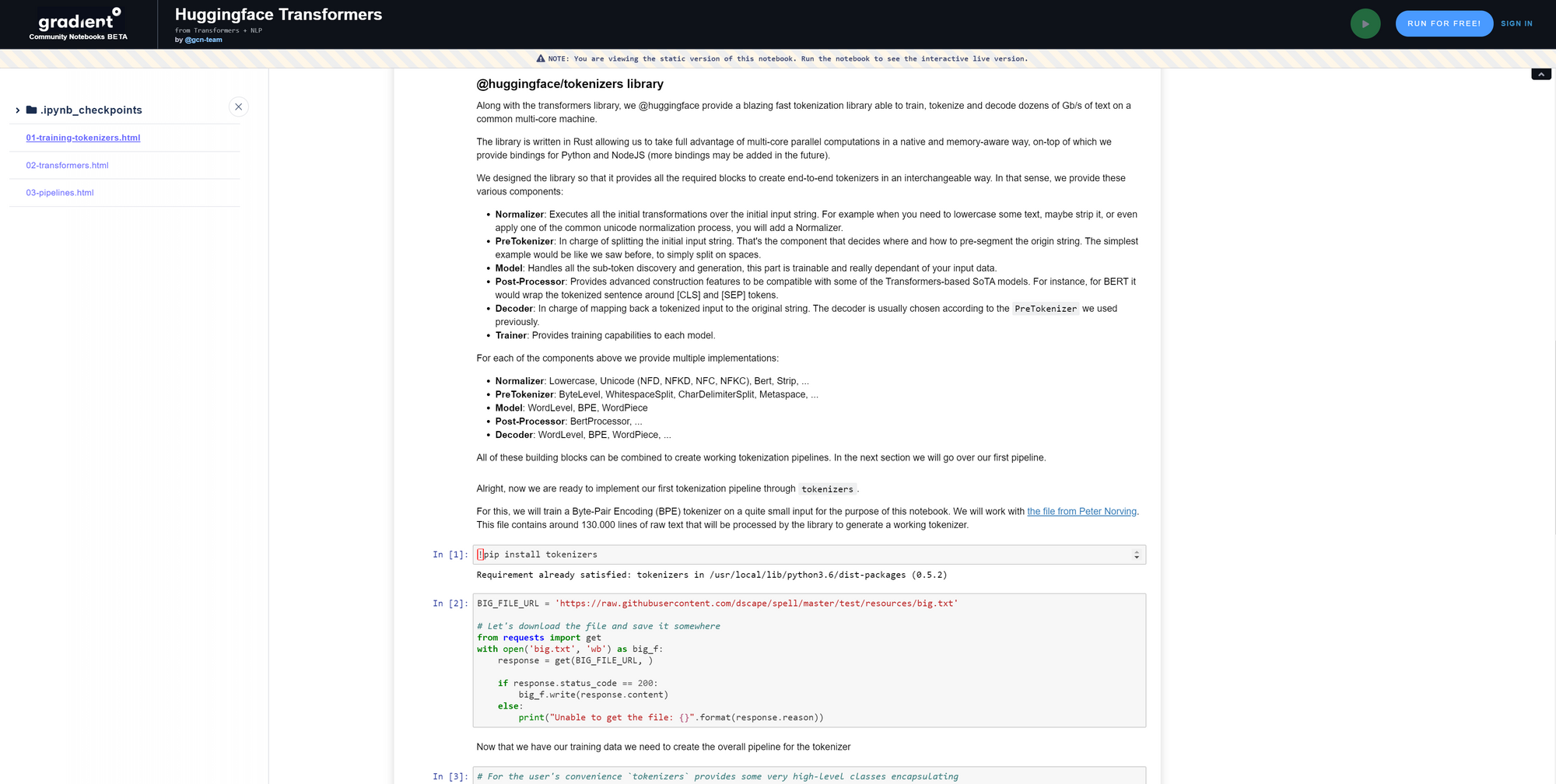
Before diving into any Machine Learning or Deep Learning Natural Language Processing models, every practitioner should find a way to map raw input strings to a representation understandable by a trainable model. With the Tokenizers library, you can create end-to-end tokenizers in an interchangeable way. Incredibly fast, this provides the ability to train, tokenize, and decode dozens of gigabytes-per-second of text on a common multi-core machine.
NLP Pipelines
Newly introduced in transformers v2.3.0, pipelines encapsulate the overall process of every NLP process. These provide a high-level, easy-to-use API for doing inference over a variety of downstream tasks.
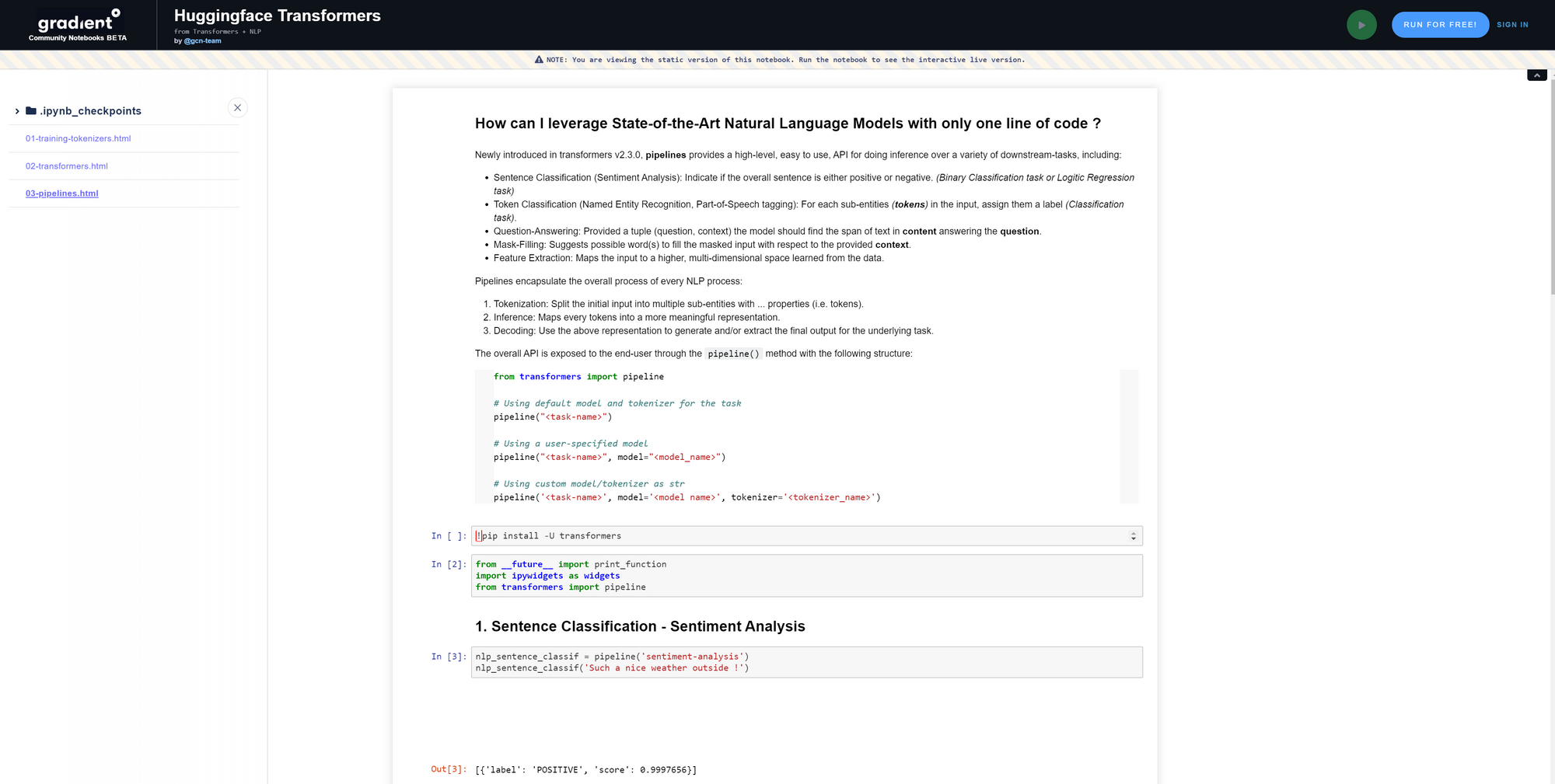
Tools from each library are put into context with pipelines for inference on sentence classification (sentiment analysis), token classification, question-answering, mask-filling, and feature extraction.
More To Come
We're proud to provide advanced NLP tools (with minimal fuss) to the community. Over time we'll be expanding the offering by providing additional resources for Hugging Face and other industry-standard libraries on Gradient.
Check back in the coming months!