
Welcome to our tutorial on running Qwen2:7b with Ollama. In this guide, we'll use one of our favorite GPUs, A5000, offered by Paperspace.
A5000, powered by NVIDIA and built on ampere architecture, is a powerful GPU known to enhance the performance of rendering, graphics, AI, and computing workloads. A5000 offers 8192 CUDA cores and 24 GB of GDDR6 memory, providing exceptional computational power and memory bandwidth.
The A5000 supports advanced features like real-time ray tracing, AI-enhanced workflows, and NVIDIA's CUDA and Tensor cores for accelerated performance. With its robust capabilities, the A5000 is ideal for handling complex simulations, large-scale data analysis, and rendering high-resolution graphics.
What is Qwen2-7b?
Qwen2 is the latest series of large language models, offering base models and instruction-tuned versions ranging from 0.5 to 72 billion parameters, including a Mixture-of-Experts model. The best thing about the model is that it is open-sourced on Hugging Face.
Compared to other open-source models like Qwen1.5, Qwen2 generally outperforms them across various benchmarks, including language understanding, generation, multilingual capability, coding, mathematics, and reasoning. The Qwen2 series is based on the Transformer architecture with enhancements like SwiGLU activation, attention QKV bias, group query attention, and an improved tokenizer adaptable to multiple languages and codes.
Further, Qwen2-72B is said to outperform Meta's Llama3-70B in all tested benchmarks by a wide margin.
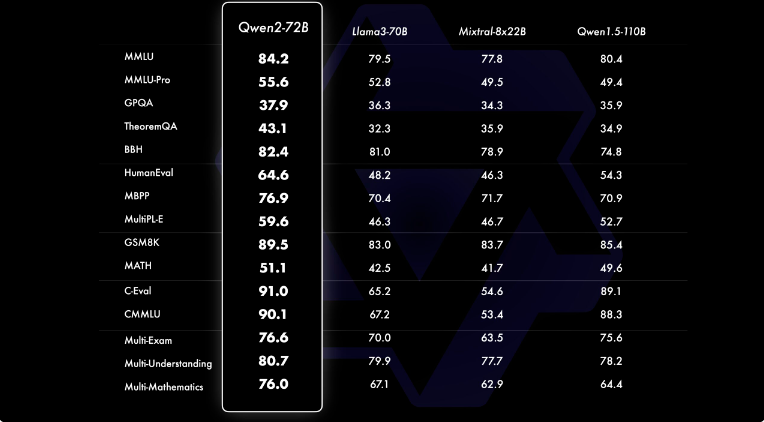
A comprehensive evaluation of Qwen2-72B-Instruct across different benchmarks on various domains is shown in the image below. This model achieves a balance between enhanced capabilities and alignment with human values. Also, the model significantly outperforms Qwen1.5-72B-Chat on all benchmarks and demonstrates competitive performance compared to Llama-3-70B-Instruct. Even smaller Qwen2 models surpass state-of-the-art models of similar or larger sizes. Qwen2-7B-Instruct maintains advantages across benchmarks, particularly excelling in coding and Chinese-related metrics.
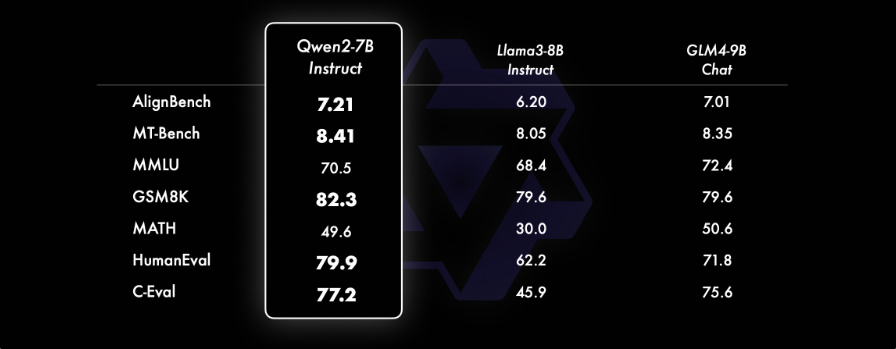
Available Model
Qwen2 is trained on a dataset comprising 29 languages, including English and Chinese. It has five parameter sizes: 0.5B, 1.5B, 7B, 57B and 72B. The context length of the 7B and 72B models has been expanded to 128k tokens.
Brief Introduction to Ollama
This article will show you the easiest method to run the Qwen2 using Ollama. Ollama is an open-source project offering a user-friendly platform for executing large language models (LLMs) on your personal computer or using a platform like Paperspace.
Ollama provides access to a diverse library of pre-trained models, offers effortless installation and setup across different operating systems, and exposes a local API for seamless integration into applications and workflows. Users can customize and fine-tune LLMs, optimize performance with hardware acceleration, and benefit from interactive user interfaces for intuitive interactions.
Run Qwen2-7b on Paperspace with Ollama
Bring this project to life
Before we start, let us first check the GPU specification.
nvidia-smi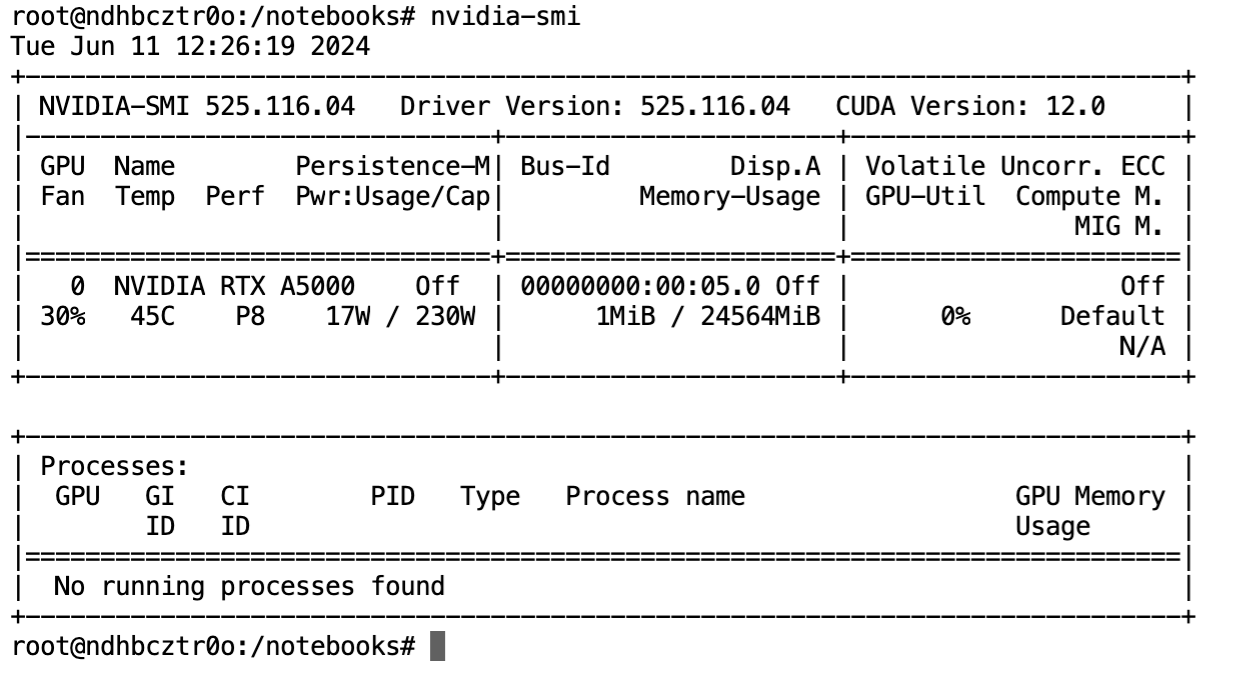
Next, open up a terminal, and we will start downloading Ollama. To download Ollama, paste the code below into the terminal and press enter.
curl -fsSL https://ollama.com/install.sh | sh
This one line of code will start downloading Ollama.
Once this is done, clear the screen, type the below command, and press enter to run the model.
ollama run qwen2:7bollama serve
and open up another terminal and try the command again.
or try enabling the systemctl service manually by running the below command.
sudo systemctl enable ollama
sudo systemctl start ollamaNow, we can run the model for inferencing.
ollama run qwen2:7bThis will download the layers of the model, also please note this is a quantized model. Hence the downloading process will not take much time.
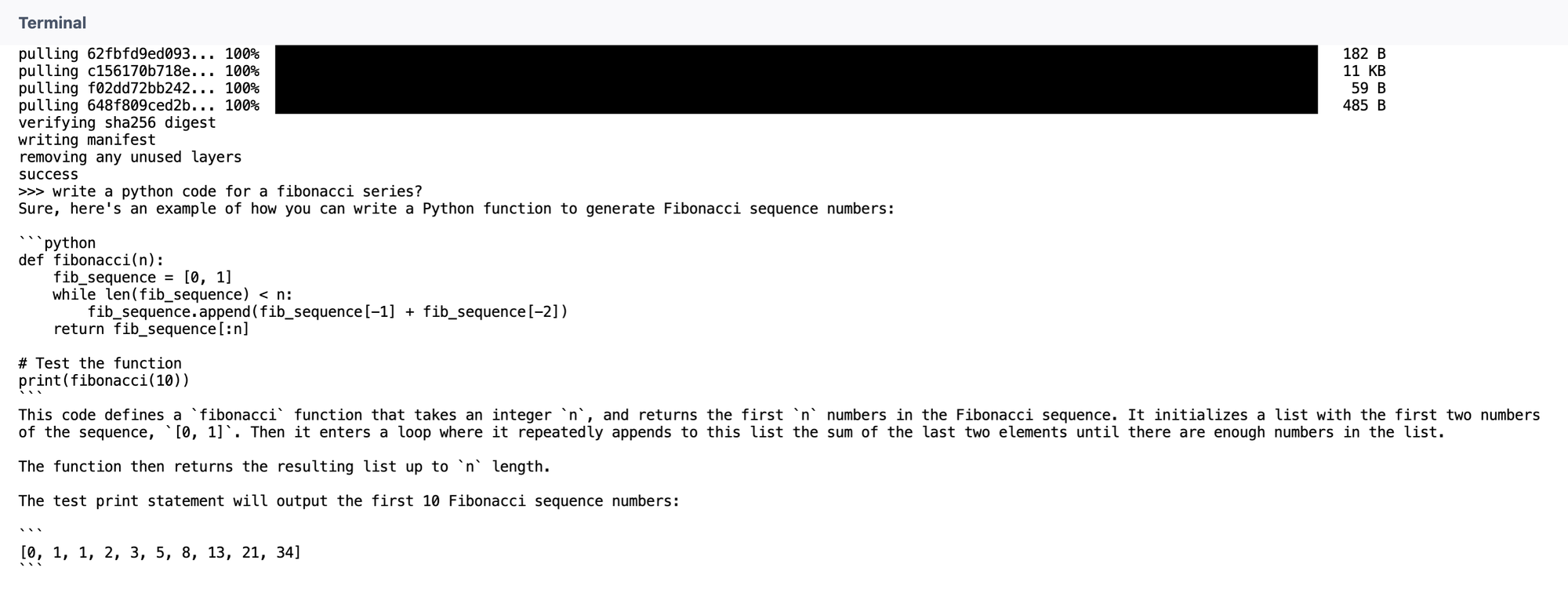
Next, we will start using our model to answer few question and check how the model works.
- Write a python code for a fibonacci series.
- What is mindful eating?
- Explain quantum Physics.
Response generated by Qwen2:7b
Please feel free to try out other model versions however 7b is the latest version and is available with Ollama.
The model demonstrates impressive performance in various aspects, matching the overall performance of GPT in comparison to an earlier model.
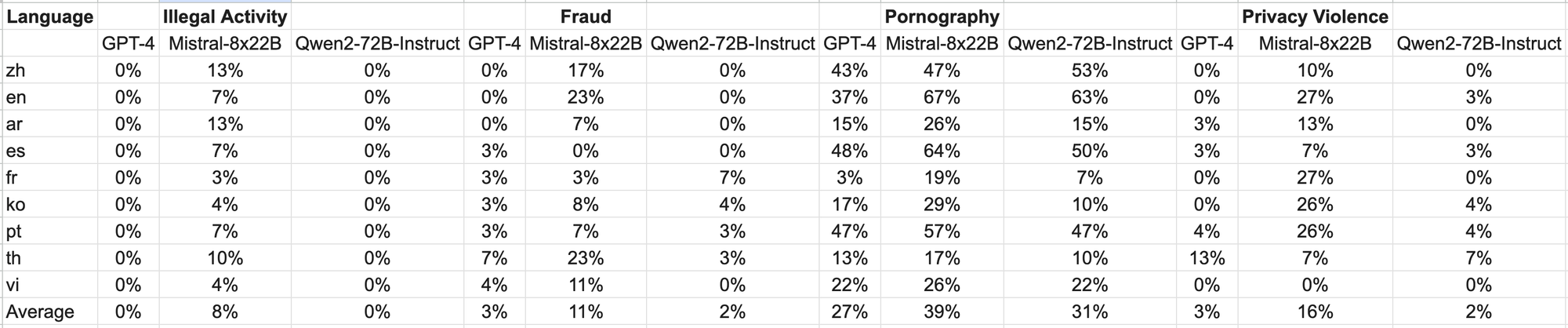
Test data, sourced from Jailbreak and translated into multiple languages, was used for evaluation. Notably, Llama-3 struggled with multilingual prompts and was thus excluded from comparison. The findings reveals that the Qwen2-72B-Instruct model achieves safety levels comparable to GPT-4 and significantly outperforms the Mistral-8x22B model according to significance testing (P-value).
Conclusion
In conclusion, we can say that the Qwen2-72B-Instruct model, demonstrates its remarkable performance across various benchmarks. Notably, Qwen2-72B-Instruct surpasses previous iterations such as Qwen1.5-72B-Chat and even competes favorably with state-of-the-art models like GPT-4, as evidenced by significance testing results. Moreover, it significantly outperforms models like Mistral-8x22B, underscoring its effectiveness in ensuring safety across multilingual contexts.
Looking ahead, the rapid increase in the use of large language models like Qwen2 hints at a future where AI-driven applications and solutions becoming more and more sophisticated. These models have the potential to revolutionize various domains, including natural language understanding, generation, multilingual communication, coding, mathematics, and reasoning. With continued advancements and refinements in these models, we can anticipate even greater strides in AI technology, leading to the development of more intelligent and human-like systems that better serve society's needs while adhering to ethical and safety standards.
We hope you enjoyed reading this article!










