

Bring this project to life
In this article we introduce Mistral 7B, a large language model with 7 billion parameter known for its performance and efficiency. The model has surpassed the performance of the leading 13B model (Llama 2) across all assessed benchmarks, as well as outperforming the best released 34B model (Llama 1) in reasoning, mathematics, and code generation. Mistral 7B has claimed to deliver high performance while maintaining an efficient inference.
The model employs grouped-query attention (GQA) to enhance inference speed and incorporates sliding window attention (SWA) for efficient processing of sequences with arbitrary length, minimizing inference costs.
We will use the powerful A6000 GPU to fine-tune the model which requires less than $2 per hour. Harness the power of A6000 for accelerated and budget-friendly fine-tuning processes.
Fine-Tuning Mistral-7B
We will use the Paperspace's robust GPUs, to seamlessly fine-tune our model for generating instructional responses. The platform offers user-friendly interface and scalable infrastructure allowing efficient access to GPU resources, this allows easy allocation of computing power. Our focus is on training the model using 4-bit double quantization with LoRa, specifically on the MosaicML instruct dataset. Further, we'll narrow down to the ‘dolly_hhrlhf’ subset of the dataset, which is a clean response-input pair. Regardless of the dataset size, the process remains the same. The process involves the conversion of actual data into prompts.
Concept
Bring this project to life
Here's the concept: we provide the model with a response from our dataset and challenge it to generate the original instruction that led to that response. It's like entire process but in reverse.
Let us start by importing the necessary packages:
!pip install transformers trl accelerate torch bitsandbytes peft datasets -qUDownload the dataset needed to fine-tune the model
from datasets import load_dataset
instruct_tune_dataset = load_dataset("mosaicml/instruct-v3")
instruct_tune_dataset
type(instruct_tune_dataset)
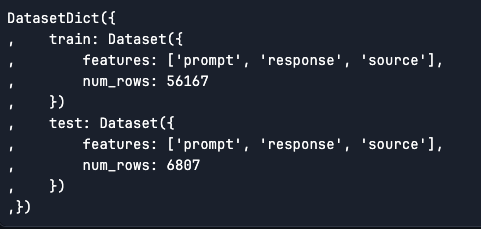
As we can see the training data is a pair of 56.2k rows and test data is 6.8k rows and is a 'datasets.dataset_dict.DatasetDict' type dataset.
Further, we will narrow down the dataset to obtain the subset of the data by filtering on 'dolly_hhrlhf.'
instruct_tune_dataset = instruct_tune_dataset.filter(lambda x: x["source"] == "dolly_hhrlhf")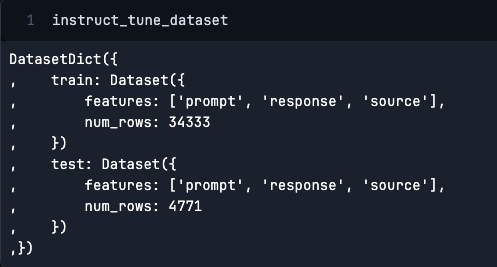
We're going to train and test on a smaller subset of the data this would reduce the amount of time spent training!
instruct_tune_dataset["train"] = instruct_tune_dataset["train"].select(range(3000))
instruct_tune_dataset["test"] = instruct_tune_dataset["test"].select(range(200))Next, we are going to create a function which will take in a sample input and generates a sequence. This sequence is essentially the message and the prompt to get that response.
def create_prompt(sample):
bos_token = "<s>"
original_system_message = "Below is an instruction that describes a task. Write a response that appropriately completes the request."
system_message = "Use the provided input to create an instruction that could have been used to generate the response with an LLM."
response = sample["prompt"].replace(original_system_message, "").replace("\n\n### Instruction\n", "").replace("\n### Response\n", "").strip()
input = sample["response"]
eos_token = "</s>"
full_prompt = ""
full_prompt += bos_token
full_prompt += "### Instruction:"
full_prompt += "\n" + system_message
full_prompt += "\n\n### Input:"
full_prompt += "\n" + input
full_prompt += "\n\n### Response:"
full_prompt += "\n" + response
full_prompt += eos_token
return full_promptfor example:-
instruct_tune_dataset["train"][0]{'prompt': 'Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction\nHow can I cook food while camping?\n\n### Response\n',
'response': 'The best way to cook food is over a fire. You’ll need to build a fire and light it first, and then heat food in a pot on top of the fire.',
'source': 'dolly_hhrlhf'}
create_prompt(instruct_tune_dataset["train"][0])'<s>### Instruction:\nUse the provided input to create an instruction that could have been used to generate the response with an LLM.\n\n### Input:\nThe best way to cook food is over a fire. You’ll need to build a fire and light it first, and then heat food in a pot on top of the fire.\n\n### Response:\nHow can I cook food while camping?</s>'
Load and Train the Model
this is an essential step as the model requires a decent amount of GPU space. Hence, we will highly recommend our users to use a pro version to get full access to our GPUs. We will still go ahead with the quantized version of the model from 32 bit to 4 bit.
We've decided to implement BFloat16, a 16-bit or half-precision quantization, for our compute data type, while the storage data type will be four bits. This means that we'll store all weights using 4 bits, but during training, we'll temporarily upcast them to 16 bits. This approach allows us to efficiently train while benefiting from the space savings achieved through 4-bit quantization.
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16
)Next, load the model and the tokenizer
model = AutoModelForCausalLM.from_pretrained(
"mistralai/Mistral-7B-Instruct-v0.1",
device_map='auto',
quantization_config=nf4_config,
use_cache=False
)
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"Let us now move to the fine-tuning part!
Since we are using a quantized version of the model we should use something called as LoRa. We have a detailed blog post on LoRa authored by James Skelton. We highly recommend to go through the post to get a detailed knowledge on LoRa.
But for now we will understand LoRa briefly.
LoRa
In this fine-tuning process we are using PEFT LoRa which stands for Parameter Efficient Fine Tuning (PEFT) using Low-Rank Adaptation (LoRA) method. In simpler terms, when we teach our model (train), we use a large set of information called a matrix. There are many of these matrices. LoRa is a technique that helps us use much smaller matrices which represents the big ones. It works by taking advantage of the fact that there's a bunch of repetitive stuffs in the big matrix, especially for what we're trying to do.
So, think of the full matrix like a big list of all the tasks it could ever learn, but our specific task only needs a small part of that list. With LoRa, we figure out how to focus just on that small part. This way, we don't have to deal with the whole list every time we train our model for our specific job. That's the basic idea behind LoRa!
This approach further reduces the amount of GPU space needed, as the model doesn't have to process and store unnecessary information. Essentially, LoRa optimizes the use of GPU resources and making the training process more efficient and saving valuable computing resources.
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM"
)Prepare model for k-bit training
model = prepare_model_for_kbit_training(model)
model = get_peft_model(model, peft_config)Next, set the hyperparameter, this is to not make the model overfit the training data.
args = TrainingArguments(
output_dir = "mistral_instruct_generation",
#num_train_epochs=5,
max_steps = 100,
per_device_train_batch_size = 4,
warmup_steps = 0.03,
logging_steps=10,
save_strategy="epoch",
#evaluation_strategy="epoch",
evaluation_strategy="steps",
eval_steps=20,
learning_rate=2e-4,
bf16=True,
lr_scheduler_type='constant',
)In the process of supervised fine-tuning (SFT), the pre-trained Language Model (LLM) undergoes adjustments using labeled data through supervised learning techniques. The model's weights are modified according to the gradients obtained from the task-specific loss, which is measured by the difference between the predictions made by the LLM and the actual ground truth labels.
max_seq_length = 2048
trainer = SFTTrainer(
model=model,
peft_config=peft_config,
max_seq_length=max_seq_length,
tokenizer=tokenizer,
packing=True,
formatting_func=create_prompt,
args=args,
train_dataset=instruct_tune_dataset["train"],
eval_dataset=instruct_tune_dataset["test"]
)Next, we will call the train function, here we train the model for 100 steps. Please modify the code to train using number of epochs.
import time
start = time.time()
trainer.train()
print(time.time()- start)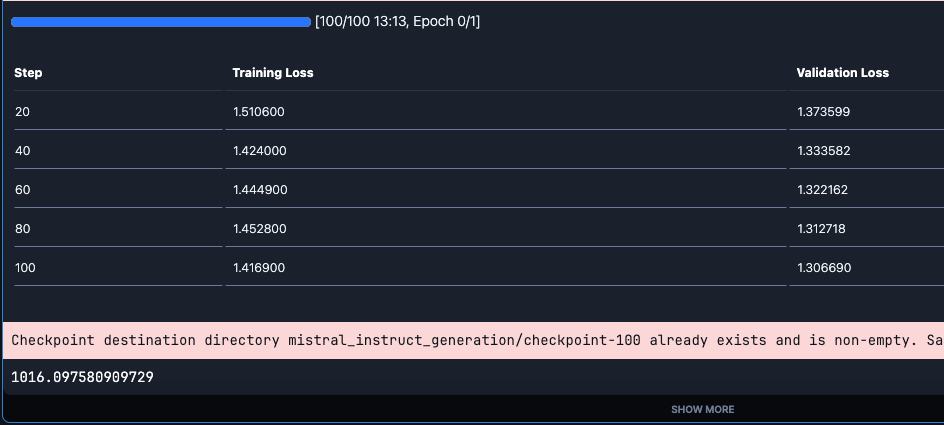
We can see that the loss gradually decreases with the steps. Also, note that it takes approx 16 min to train the model. Please note that you need to add wand credential before the training.
We will save this trained model locally,
trainer.save_model("mistral_instruct_generation")We can push the model to hugging face hub, make sure to authorize hugging face to push the model.
In this case we push the adapter, we are not pushing the full model here. When utilizing LoRa for training, we end up with a component known as an adapter. This adapter serves as an extension that can be applied to the base model, granting it the specific capabilities acquired during fine-tuning.
trainer.push_to_hub("shaoni/mistral-instruct-generation")View the system metrics and model performance by checking the recent run on wandb.ai.
Please keep in mind that the model can still underperform as it is fine-tuned on a small sample dataset.
generate_response("### Instruction:\nUse the provided input to create an instruction that could have been used to generate the response with an LLM.### Input:\nThere are more than 12,000 species of grass. The most common is Kentucky Bluegrass, because it grows quickly, easily, and is soft to the touch. Rygrass is shiny and bright green colored. Fescues are dark green and shiny. Bermuda grass is harder but can grow in drier soil.\n\n### Response:", model)'<s> ### Instruction:\nUse the provided input to create an instruction that could have been used to generate the response with an LLM.### Input:\nThere are more than 12,000 species of grass. The most common is Kentucky Bluegrass, because it grows quickly, easily, and is soft to the touch. Rygrass is shiny and bright green colored. Fescues are dark green and shiny. Bermuda grass is harder but can grow in drier soil.\n\n### Response:\nWhich type of grass is the most common and why is it popular?</s>'
This response is much better and the model is not just adding random words about the grass.
And with this we have come to end of fine-tuning Mistral-7B using PEFT LoRa.
To view the complete notebook, kindly follow the link provided in the article. Clicking on the link will redirect you to the Paperspace Platform, where you can start the machine to begin exploring and experimenting with the code.
We also recommend to check out the references section to find out more. We hope you enjoyed the article!
Thank you for reading!











