

Bring this project to life
What is better than Llama 1? LLama 2. What is even better than LLama 2? LLama 3. Meta recently announced LLama 3, the next-generation state-of-the-art open-source large language model.
Llama 3 now features advanced language models with 8B and 70B parameters. These models have proven to excel across various tasks and offer better reasoning capabilities. The model has been open-sourced for commercial uses and for the community to innovate in AI applications, developer tools, and more. This article explores the model's capabilities using Paperspace's powerful GPUs.
The Llama 3 releases four LLM models by Meta, built on the Llama 2 framework. These models come in two sizes: 8B and 70B parameters, each featuring base (pre-trained) and instruct-tuned versions. They're designed to run smoothly on different consumer hardware types and boast a context length of 8K tokens.
- Meta-Llama-3-8b: Base 8B model
- Meta-Llama-3-8b-instruct: Instruct fine-tuned version of the base 8b model
- Meta-Llama-3-70b: Base 70B model
- Meta-Llama-3-70b-instruct: Instruct fine-tuned version of the base 70b model
The original research paper has yet to be released. However, Meta claims to release the paper soon.
LLama 3 Enhancements
The latest Llama 3 models with 8B and 70B parameters are a considerable step forward from Llama 2, setting a new standard for large language models. They're the top models in their class, thanks to better pretraining and fine-tuning methods. The post-training enhancements have significantly reduced errors and improved the models' performance at reasoning, generating code, and following instructions. In short, Llama 3 is more advanced and flexible than ever.
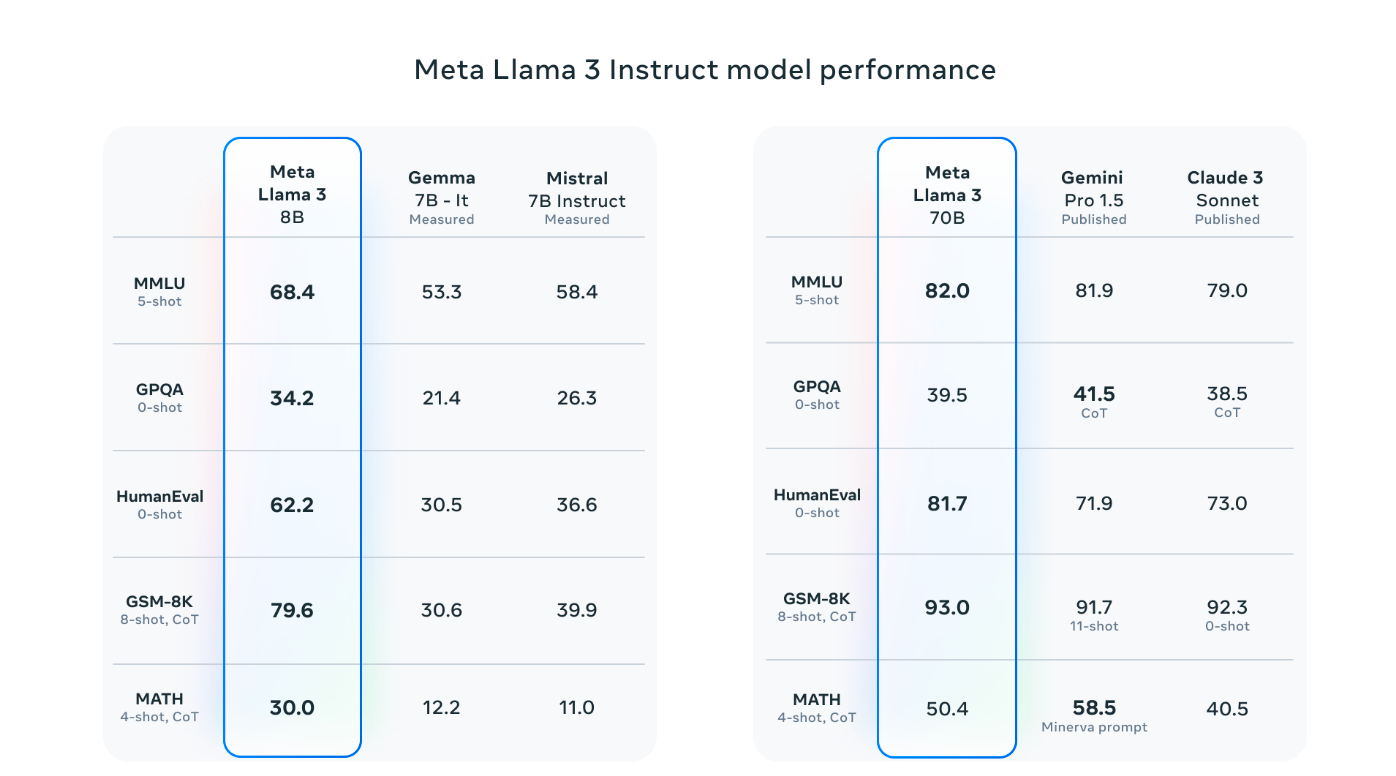
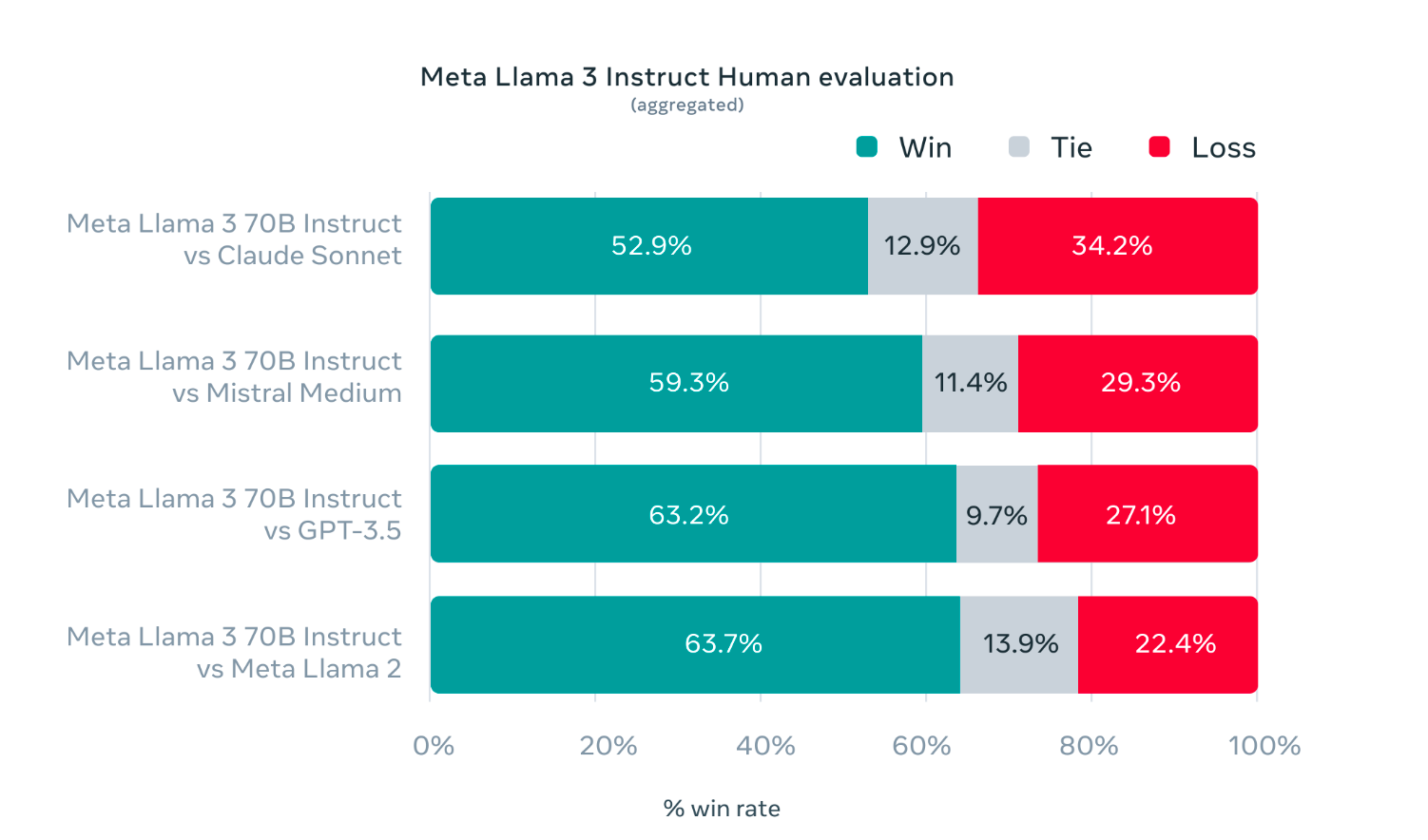
While developing Llama 3, the main focus was model optimisation for real-life situations. A top-notch evaluation set was created with 1,800 prompts covering 12 critical tasks: advice-seeking, coding, and summarization. Further, the validation data has been used privately to prevent model overfitting. Human evaluations comparing Llama 3 to other models show promising results across various tasks and scenarios.
To enhance Llama 3's capabilities, Meta focused on scaling up pretraining and refining post-training techniques.
Scaling up pre-training involved developing precise scaling laws to optimize data leakage and compute usage. Surprisingly, even after training on massive amounts of data—up to 15 trillion tokens—the models continued to improve. Various parallelization methods and custom-built GPU clusters were combined for efficient training and boosting efficiency by three times compared to Llama 2.
For instruction fine-tuning, different techniques like supervised fine-tuning and preference optimization were considered. Further, careful curation of training data and learning from preference rankings significantly improved the models' performance, especially in reasoning and coding tasks. These advancements allow the models to better understand and respond to complex queries.
Model Architecture
In designing Llama 3, a standard decoder-only transformer setup was installed. Compared to Llama 2, an efficient tokenizer with a vocabulary of 128K tokens helped to boost the performance. Plus, to make Llama 3 models faster during inference, grouped query attention (GQA) across different sizes was introduced. During training, sequences of 8,192 tokens and a masking technique to maintain attention within document boundaries were used.
Creating the best language model begins with a top-quality training dataset. For Llama 3, over 15 trillion tokens were curated from publicly available sources—seven times larger than what was used for Llama 2. This dataset even includes four times more code. This model aims for multilingual use by including over 5% non-English data, covering 30 languages, although we anticipate English will still outperform others.
To maintain quality, robust data-filtering pipelines are built, also using methods like heuristic filters and text classifiers increased the model performance. Through extensive experimentation, researchers ensure Llama 3 performs well across various tasks, from trivia to coding and beyond.
LLama 3 Demo
Bring this project to life
Before starting, make sure to get access to the model "meta-llama/Meta-Llama-3-70B" on huggingface.co
To use Llama 3 we will first start by upgrading the transformers package
#upgrade the transformer package
pip install -U "transformers==4.40.0" --upgrade
Next, run the following code snippet. The Hugging Face blog post states that the model typically requires about 16 GB of RAM, including GPUs such as 3090 or 4090.
import transformers
import torch
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model="meta-llama/Meta-Llama-3-8B-Instruct",
model_kwargs={"torch_dtype": torch.bfloat16},
device="cuda",
)
pipeline("Hey how are you doing today?")
torch.backends.cuda.enable_mem_efficient_sdp(False)
torch.backends.cuda.enable_flash_sdp(False)'generated_text': "Hey how are you doing today? I hope you're having a great day so far! I just"
Few things to keep in mind here,
- In our example case, we have used 'bfloat16' to load the model. Originally, Meta used 'bfloat16.' Hence, this is a recommended way to run to ensure the best precision or to conduct evaluations. For real-world cases, try
float16, which may be faster depending on your hardware. - One can also automatically compress the model, loading it in either 8-bit or 4-bit mode. Running in 4-bit mode requires less memory, making it compatible with many consumer-grade graphics cards and less powerful GPUs. Below is an example code snippet on how to load the pipeline with 4-bit mode.
pipeline = transformers.pipeline(
"text-generation",
model="meta-llama/Meta-Llama-3-8B-Instruct",
model_kwargs={
"torch_dtype": torch.float16,
"quantization_config": {"load_in_4bit": True},
"low_cpu_mem_usage": True,
},
)The Future of Llama 3
While the current 8B and 70B models are impressive, Meta researchers are working on even bigger ones with over 400B parameters. These models are still in training. In the coming months, they will have exciting new features like multimodality, multilingual conversation abilities, longer context understanding, and overall stronger capabilities.

Conclusion
With Llama 3, Meta has set to build the best open models that are on par with the best proprietary models available today. The best thing about Meta's Llama 3 is its open-source ethos of releasing early and often to enable the community to access these models while they are still developing. The released text-based models are the first in the Llama 3 collection of models. As stated by Meta, their main goal is to make Llama 3 multilingual and multimodal, have a more extended context, and continue to improve overall performance across core LLM capabilities such as reasoning and coding.
We can’t wait to see what's next in the GenAI field.











