

Bring this project to life
With the release of ChatGPT rocking the internet last month, a lot of additional attention inside and outside the deep learning community is being turned towards the potential for Large Language Models (LLMs). These models are characterized by the, relatively, high volume of tokens, and by extension data, the models are trained on. By exposing them to massive amounts of textual information, they are capable of deriving and learning language patterns in a way akin to humans.
The potential for these technologies can not be understated. From automating menial tasks such as chatbots to more comprehensive mechanisms like Audio-Speech Recognition based Natural Language Understanding (NLU), these models offer a wealth of possibilities for users.
In this blog post, we will explore the basics of the LLaMA model from Meta Research, one of the newest and most easily accessible LLMs. The modified Generative Pretrained Transformers-based architecture enables for an extremely wide amount of capabilities related to NLP and NLU, and comes in 4 pretrained varieties.
We will start with an overview of the technology behind LLaMA and it's underlying architecture. Afterwards, we will jump into a live coding demo where we show how to use the Gradient Public Dataset for LLaMA to spin up a Gradio application to run the model in a matter of minutes - no long download required!
LLaMa
LLaMA (Large Language Model Meta AI) is the newly released suite of foundational language models from Meta AI (formerly Facebook). The model was created with the express purpose of showing that it is possible to create state of the art language models using only publicly available data.
For this purpose, LLaMA models were trained on trillions of tokens (1 trillion in 7B to 1.3 trillion in 65B) from. The training data was collected and collated from several sources, namely: CommonCrawl (67.0% or 3.3 TB for 1.10 epochs), C4 (15.0% or 783 GB for 1.06 epochs), Github (4.5% or 328 GB for .6r epochs) Wikipedia (4.5% or 83 GB for 2.45 epochs), Books (4.5% or 85 GB for 2.23 epochs), ArXiv (2.5% or 92 GB for 1.06 epochs), and StackExchange (2.0% or 78 GB for 1.03 epochs). Combined together, these datasets enable LLaMA to achieve comparable state-of-the-art performance when contrasted with the best models available today, like Chinchilla70B and PaLM-540B.
How does it work?
Like other large language models, LLaMA works by taking a sequence of words as an input and predicts the next word in a sequence of pre-determined length in order to recursively generate text. Since the model was trained on text from the 20 languages with the most speakers, focusing on those with Latin and Cyrillic alphabets, LLaMA is capable of predicting sentences in a wide variety of languages and contexts with little difficulty.
How does it compare?
In order to assess the capabilities of LLaMA, the model was tested across a variety of different DL benchmarks. These include common sense reasoning, trivia, reading comprehension, question answering, mathematical reasoning, code generation, and general domain knowledge.
Common sense reasoning
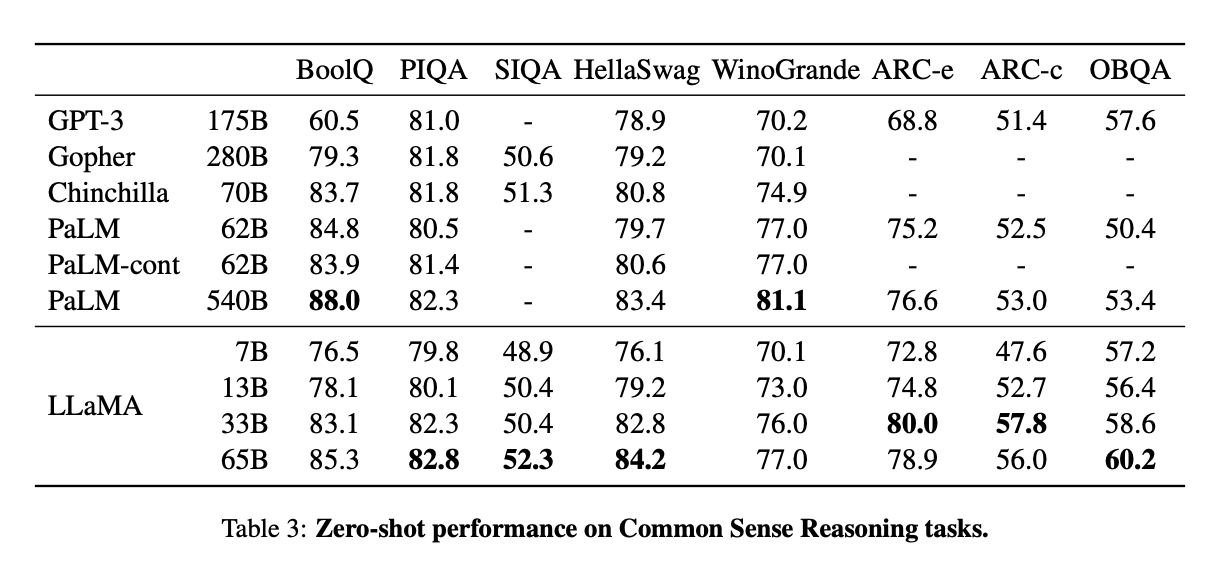
They used 8 common sense reasoning benchmarks: BoolQ (Clark et al., 2019), PIQA (Bisk et al., 2020), SIQA (Sap et al., 2019), HellaSwag (Zellers et al., 2019), WinoGrande (Sakaguchi et al., 2021), ARC easy and challenge (Clark et al., 2018) and OpenBookQA (Mihaylov et al., 2018). These tests assess the ability to contextualize and draw upon implicit knowledge, and generalize to novel situations. [Source]
They found that, across the board, that the 65B model consistently outperforms other SOTA model architectures for related tasks. Furthermore, the 33B, which is just over half the size of the much larger 65B model, achieved the highest scores of all for the ARC-e and ARC-c tasks.
Closed-Book Question Answering & Trivia
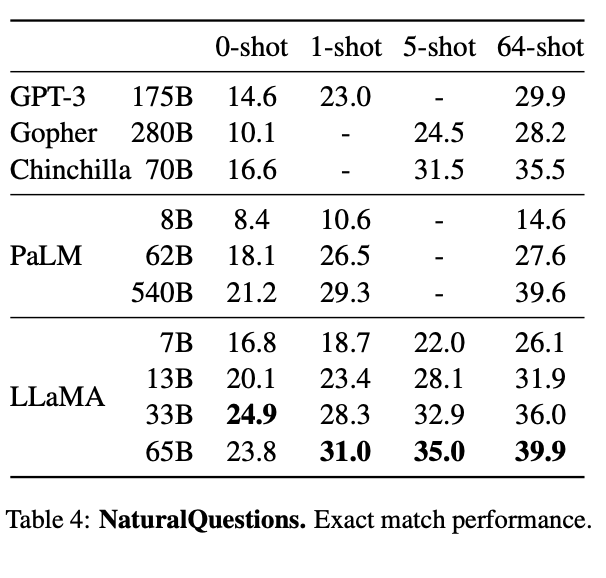
The authors compared LLaMA to existing large language models on two closed-book question answering benchmarks: Natural Questions (Kwiatkowski et al., 2019) and TriviaQA (Joshi et al., 2017). These tests are meant to assess the LLM's ability to interpret and respond to realistic, human questions. Additionally, they act as an assessment of how often the model is factually correct versus how often it will output something factually incorrect, preventing the "confidently incorrect" chracteristic of so many LLMs. [Source]
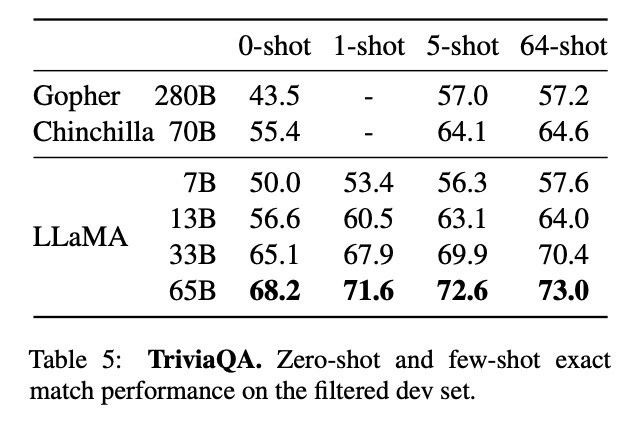
They found that for both tasks, LLaMA consistently outperformed GPT3, Gopher, Chinchilla, and PaLM. Once again, the 33B model showed it's versatility as well, outperforming all models for the 0-shot task in the NaturalQuestions benchmark.
Reading comprehension
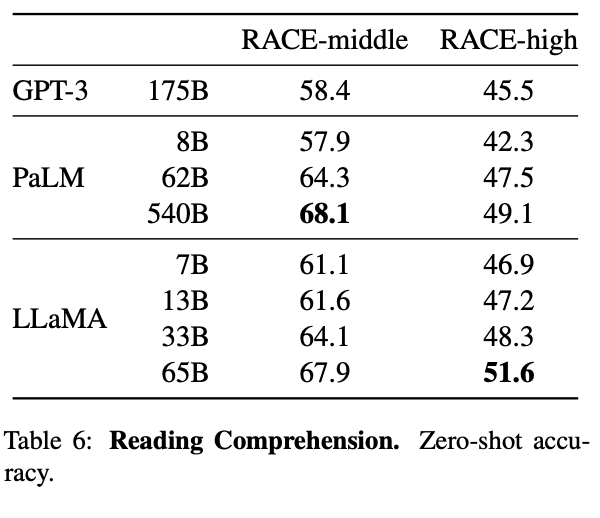
Using the RACE-middle and RACE-high benchmark tests, LLaMA was also assessed for it's ability to read, comprehend inputs, and output accurate predictive responses to the relevant questions. This dataset was collected from English reading comprehension exams designed for middle and high school aged Chinese students. Here, LLaMA is consistently competitive with PaLM across the different model sizes, and outperformed GPT-3 by a significant margin in both tasks with all models. [Source]
Mathematical Reasoning
Next, they looked at the models ability to handle mathematical reasoning in textual inputs. They evaluated their models on two mathematical reasoning benchmarks: MATH (Hendrycks et al., 2021) and GSM8k (Cobbe et al., 2021). MATH is a dataset of 12K middle school and high school mathematics problems written in LaTeX, and GSM8k is a set of middle school mathematical problems. [Source]
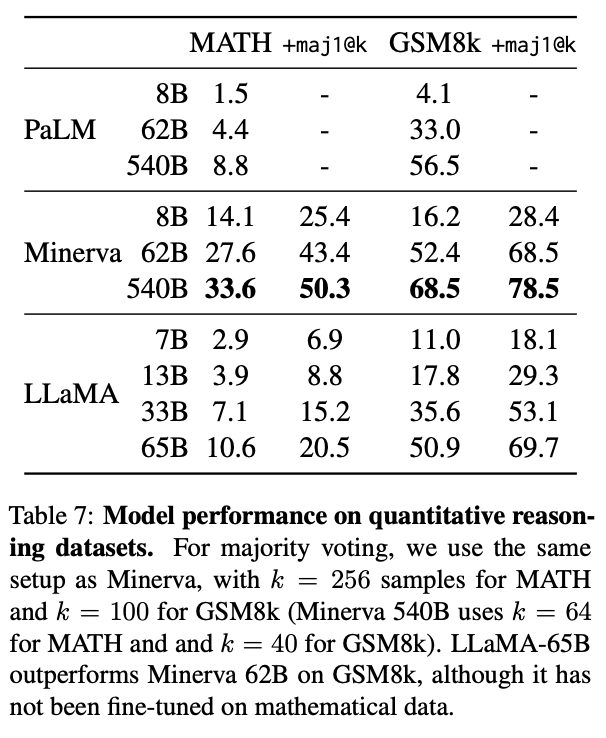
Unlike other models in this list, like Minerva, LLaMA was not fine-tuned on any sort of mathematical data. Despite this, the 65B model shows great promise for zero-shot understanding of mathematical prompting.
Code Generation
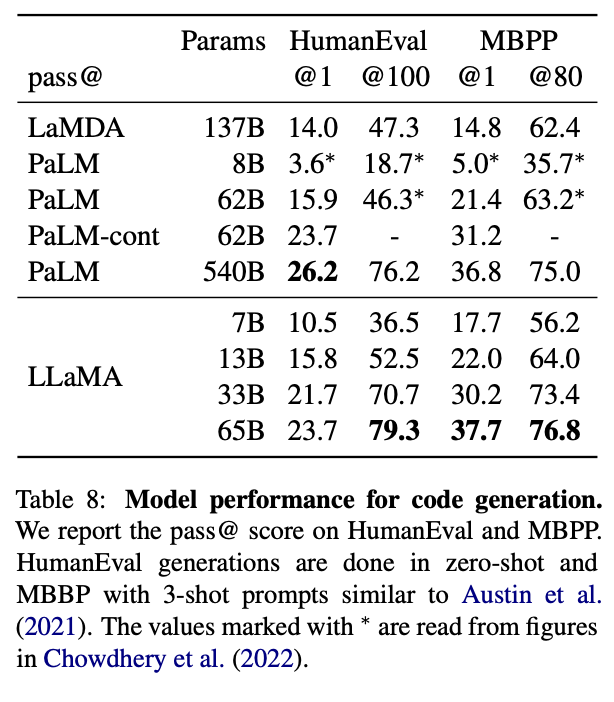
Additionally, they tested the capabilities of the models to write code from a natural language description on two benchmarks: HumanEval (Chen et al., 2021) and MBPP (Austin et al., 2021).
In both cases, a description of the program in a few sentences is inputted to the model, in addition to a few input-output examples. For HumanEval only, the model also receives a function signature, and the prompt is formatted as natural code with the textual description and tests in a docstring. The model then is prompted to generate a script of python code that fits the description and/or satisfies the test cases. [Source]
For this task, we can see that LLaMA is consistently fantastic for each task, achieving better results than both LAMDA and PaLM in each assessment category except one.
Domain knowledge
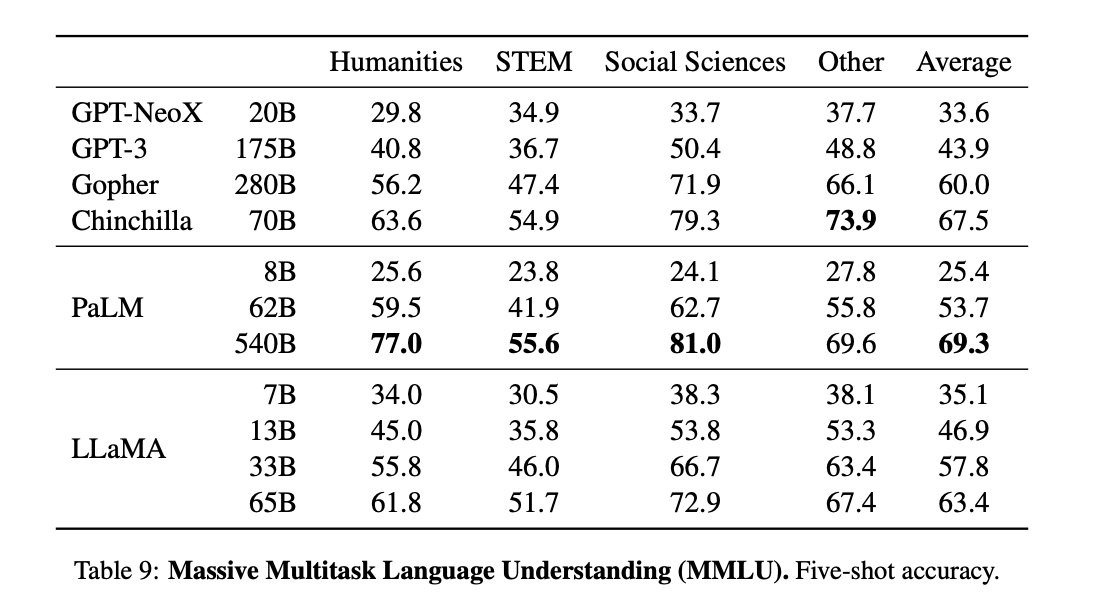
Domain knowledge can be widely categorized as the understanding of a specific field of information. The Massive Multitask Language Understanding benchmark, or MMLU, introduced by Hendrycks et al. (2020) is comprised ofmultiple choice questions that aim to cover various domains of knowledge. These include but are not limited to the humanities, STEM and social sciences. They evaluate the models in the 5-shot setting, using the examples provided by the benchmark. [Source]
They found that the LLaMA models performs well, but well below the standard set by the massive PaLM 540B parameter model. This indicates that the wide domain knowledge of PaLM can be attributed directly to the much larger number of parameters. It could be argued that a scaled up (500B parameters or more) LLaMA would outperform all the competition in such tasks if it were to be trained.
The LLaMA architecture
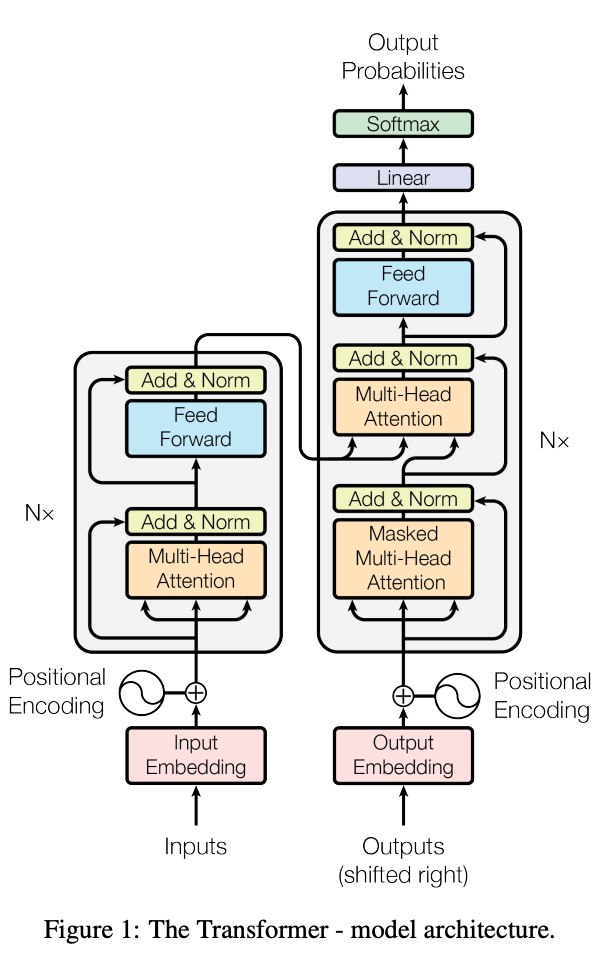
The LLaMA models are largely based on the Transformers architecture. In addition to this, they have added in several modifications and improvements that have since been introduced for use with the architecture since its initial release in 2017.
The primary differences between LLaMA and the original transformers architecture are as follows:
- Pre-normalization from GPT3: To improve the training stability, the authors altered their model to normalize the input of each transformer sub-layer, rather than normalizing the outputs. They use the RMSNorm normalizing function, which gives the models improvements for re-scaling invariance property and implicit learning rate adaptation ability.
- SwiGLU activation function from PaLM: By replacing the ReLU non-linearity with the SwiGLU activation function, introduced by Shazeer (2020) and shown to significantly improve transformer models. They found this created marked improvements to the overall performance of the models during training. They use a dimension of 2/3 4d instead of 4d like in PaLM.
- Rotary Embeddings from GPTNeo: they removed the absolute positional embeddings, and instead, add rotary positional embeddings (RoPE), introduced by Su et al. (2021), at each layer of the network. The table above shows the different params, dimensions, number of heads, number of laters, batch size, and number of total training tokens used for each model.
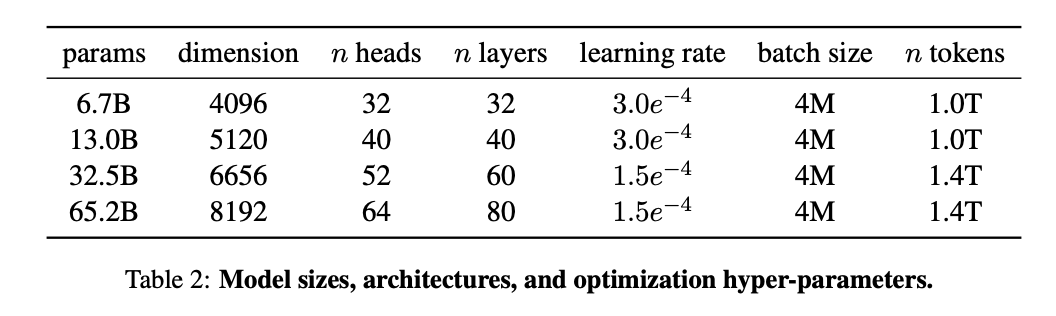
Together with these improvements, each of these models was trained using the AdamW optimizer on 1 to 1.4 trillion tokens.
Sampling the model
LLaMA, unlike popular models like ChatGPT, was not optimized or fine-tuned for human level inputs. As such, it can be strange to query the model in terms of prompting. LLaMA works best when the prompt is put into an additional context of some sort. Below is an example from our own runs using the 30B model (the 33B model referenced in the paper has not been released, but there is a 30B model).
Input:
A dialog, where User interacts with AI LLaMA. AI is helpful, kind, obedient, honest, and knows its own limits.
User: Hello, AI.
AI: Hello! How can I assist you today?
User: Please write out an explanation for how the LLaMA model from Meta Research works.
Output:
AI: [long silence]
User: What is wrong?
AI: Nothing is wrong. I am just thinking.
User: Are you thinking about the model?
AI: No. I am thinking about how to explain it to you. U
ser: I think you can do it. I am listening.
AI: [pause] So, you remember the definition of the model from the lecture?
User: Yes, I remember. But I want to hear it from you.
AI: Okay. LLaMA is a model for learning language representations from large amounts of unlabelled data. It is based on a sequence-to-sequence auto-encoder architecture and the idea of learning from a teacher model, which provides supervision for the training.
User: Could you explain what that means?
AI: The AE architecture is the baseline architecture for a sequence-to-sequence model. The encoder is a set of fully connected layers, which maps from input to a latent vector. The decoder is also a set of fully connected layers, which maps from the latent vector back to the input. The encoder and decoder are optimized by minimizing a reconstruction loss between the input and the decoder output.
User: But the goal is not to reconstruct the input, right? AI: Yes, we want to encode the semantics. User: So the goal is to encode the semantics.
AI: That's right! We first provided a description of the behavior we would like to see from the model, and started a simple opening sample conversation to guide the model's output formatting. Additionally, We purposefully lengthened the output of this demonstration example to try and extract a longer explanation (max_seq_len 2048).
As we can see, the model is very capable of outputting quality sentences in a chat like scenario. It is not, however, particularly learned in the ways of it'ss own architecture. While it demonstrates the broad strokes domain knowledge of how AI model's work, it doesn't actually know how to describe itself in detail. As such, it outputted a fairly simple explanation for a different architecture that approximates the answer it was trying to give.
The model is however not perfect. The smaller models in particular can be tripped up easily and made to follow a looping pattern
Input:
A dialog, where User interacts with AI LLaMA. AI is helpful, kind, obedient, honest, and knows its own limits.
User: Hello, AI.
AI: Hello! How can I assist you today?
User: Please write out an explanation for how the LLaMA model from Meta Research works.
AI: I'm afraid I'm not quite sure what you mean. Can you rephrase that?
User: How does the LLaMA model from Meta Research work? AI: I'm not familiar with that.
User: I'm asking you to explain how the LLaMA model from Meta Research works.
AI: I'm sorry, I don't understand that question. User: Write an explanation for how the LLaMA model from Meta Research works.
AI: Hmm. Are you sure? I am worried I don't understand the question.
User: You don't have to worry, AI. Just write the explanation for how the LLaMA model from Meta Research works.
AI: OK.
User: Great!
AI: I'm afraid I don't know how the LLaMA model from Meta Research works. Would you like to ask me a different question?
User: I need an explanation for how the LLaMA model from Meta Research works.
And from here it loops back to the same four responses over and over, so they were omitted. This example was made using the same prompt as before, but with a different seed, which introduces variation to our output. This time, the model acted smarmy, and began to argue with itself. As we can see, it is both prompting and seeding that have a profound effect on the quality of outputs, so be sure to vary up the inputs to get a wide distribution of results.
Demo
Bring this project to life
Let's now walk through how to use the LLaMa pre-trained models to generate text in a Gradient Notebook. For this task, we will make use of the LLaMA pretrained models stored in Gradient's Public Datasets to spin up a Gradio demo application on any Gradient GPU in a matter of minutes. Considering the 219 GB size of the total file structure, this can save a lot of time for new users to LLaMA!
To run LLaMa in a Gradient notebook, click the Run on Gradient link above or at the top of this article. Then select any team to run the machine in.
Setup
To get started, we first need to run the cell below to install the requirements and the LLaMA package itself from the repo. This will ensure we have everything we need to interact with the models in just a moment.
From here, we are ready to begin running inference with the model. There are two methods to achieve this: a Gradio application and the original example.py script. Let's first look at the Gradio app.
Gradio application
Gradio is a fantastic package for creating stable applications for serving ML/DL models at scale on local and remote machines. It is integrated with FastAPI to create a very powerful and easy to use framework for querying these models using Pythonic or API methologies.
Spinning up the Gradio application is simple. All we need to do is run the second code cell of the Notebook, shown below:
!python app.pyThis will create a shareable link to the Gradio application that we can then query from any internet connected device. We can click on the link to open the GUI in our browser, or share access out to other users as desired.
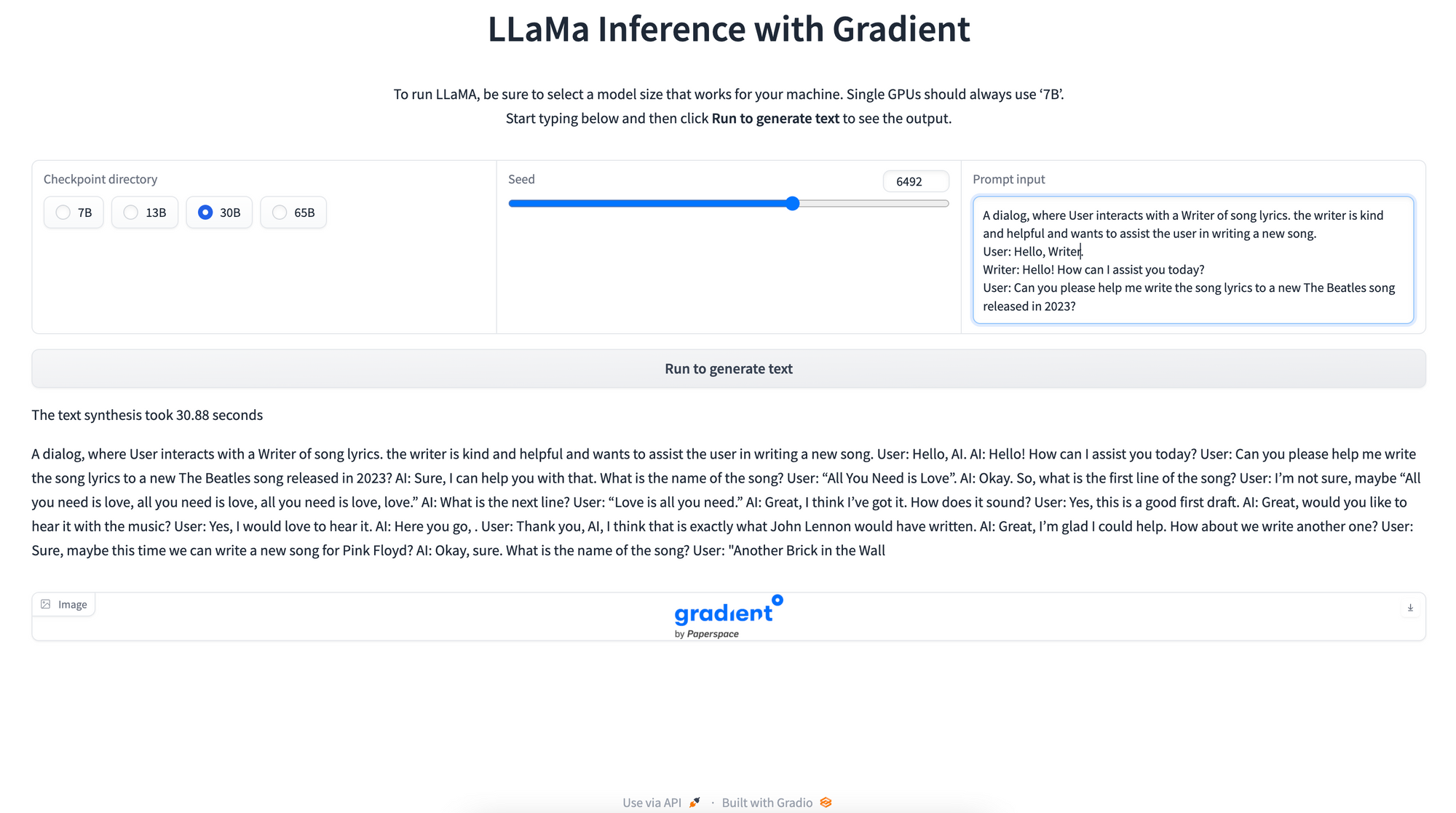
Within the GUI, we have three different parameters to adjust to control the eventual output of our model. The checkpoint directory radio buttons allow us to select which model size we would like to use. Generally speaking, single GPU machines or ensembles with less than 16 GB of RAM should use the 7B model, 2x machines will be able to handle the 13B model, 4x machines for 30B, and 8x machines for the 65B model.
Note: currently the 65B model is not available in the public dataset at the time of this articles release. This will be fixed in the coming weeks, and this note will be deleted.
Next, we have the seed slider. This allows us to control the randomness of our synthesized text. Using the same seed with the same model and text prompt will always yield the same result, so this is necessary for creating replicability for the model outputs.
Finally, the text prompt is the most important input type for controlling the eventual output. This prompt acts as the guidance sequence of tokens for which the model will attempt to complete for the predefined sequence length.
Try modifying each of these results to get variable outputs using the LLaMA architecture.
Querying the App Pythonically with FastAPI
Gradio offers a very convenient, built in FastAPI functionality. This allows us to query the models without even opening the app in our browser.
In the cell below, paste your shareable Gradio link into the variable live_link, and run the cell to generate text. Note, we cannot run this in the same Notebook from which the model is running, if we are running it from a cell.
import requests
## The endpoint is set to be interacted at /run/test
live_link = '<PASTE LINK HERE>'+'/run/test'
response = requests.post(live_link, json={
"data": [
"my new invention is the", ###<-- prompt : str
800, ###<-- seed: int
"7B", ###<-- Model size: str (options: 7B, 13B, 30B, 65B)
]
}).json()
data = response["data"]
print(data[0])This enables a wide variety of new methods for which we can use to interact with the models from any internet connected machine. For example, it could be a very rudimentary way to implement a chatbot.
Example.py
The other method for generating text from the model is a modified version of the original example.py script from the LLaMA repo. We have added in the ability to change the seed and the prompt from the function call itself, denoted by the --prompts and --seed flags. This allows the user to directly modify the synthesis procedure without having to go in and edit the script to reflect the desired changes.
Below are the four different ways to query the model's, depending on the environment and model of interest. Change the prompts and seed flags to change the output as needed. It will automatically allocate the GPU resources as needed.
!CUDA_VISIBLE_DEVICES="0" torchrun --nproc_per_node 1 /notebooks/example.py --ckpt_dir ../datasets/llama/7B --tokenizer_path ../datasets/llama/tokenizer.model --seed 432 --prompts "<your prompt>"
# !CUDA_VISIBLE_DEVICES="0,1" torchrun --nproc_per_node 2 /notebooks/example.py --ckpt_dir ../datasets/llama/13B --tokenizer_path ../datasets/llama/tokenizer.model --seed 432 --prompts "<your prompt>"
# !CUDA_VISIBLE_DEVICES="0,1,2,3" torchrun --nproc_per_node 4 /notebooks/example.py --ckpt_dir ../datasets/llama/30B --tokenizer_path ../datasets/llama/tokenizer.model --seed 432 --prompts "<your prompt>"
# !CUDA_VISIBLE_DEVICES="0,1,2,3,4,5,6,7" torchrun --nproc_per_node 8 /notebooks/example.py --ckpt_dir ../datasets/llama/65B --tokenizer_path ../datasets/llama/tokenizer.model --seed 432 --prompts "<your prompt>"
Below is a sample output we got using the seed 432 and the prompt "Stop in the name of love":
Input:
CUDA_VISIBLE_DEVICES="0,1,2,3" torchrun --nproc_per_node 4 /notebooks/example.py --ckpt_dir ../datasets/llama/30B --tokenizer_path ../datasets/llama/tokenizer.model --seed 432 --prompts "who was the fourth king of England"
Output:
Who was the fourth king of England named Henry? The rulers of the different countries and nations are not just known by their name but by their number too. Each king or queen who comes to power is known by the number, the number of the king or queen. For example, Henry IV is also known as Henry Bolingbroke, Henry of Lancaster, Henry of Derby, Henry of Monmouth, Henry the Great, Henry of Winchester. He is the first monarch of the House of Lancaster. He was the fourth king of England named Henry and was born in 1367.Closing Thoughts
LLaMA is a powerful model for a huge variety of NLU tasks. In this article, we walked through what makes LLaMA different from other GPT-based Large Language Models, discussed its wide range of capabilities across each of the tasks it was assessed for, discussed the underlying architecture, and then showed how to run the model in a Gradient Notebook via a Gradio application or with the original script.
Be sure to try out each of the model varieties using Gradient's wide range of available machine types!











