
Transformers are the backbones to power-up models like BERT, the GPT series, and ViT. However, its attention mechanism has quadratic complexity, making it challenging for long sequences. To tackle this, various token mixers with linear complexity have been developed.
Recently, RNN-based models have gained attention for their efficient training and inference on long sequences and have shown promise as backbones for large language models.
Inspired by these capabilities, researchers have explored using Mamba in visual recognition tasks, leading to models like Vision Mamba, VMamba, LocalMamba, and PlainMamba. Despite this, experiments reveal that state space model or SSM-based models for vision underperform compared to state-of-the-art convolutional and attention-based models.
This recent paper does not focus on designing new visual Mamba models. Instead, investigates a critical research question: Is Mamba necessary for visual recognition tasks?
What is Mamba?
Mamba is a deep learning architecture developed by researchers from Carnegie Mellon University and Princeton University, designed to address the limitations of transformer models, especially for long sequences. It uses the Structured State Space sequence (S4) model, combining strengths from continuous-time, recurrent, and convolutional models to efficiently handle long dependencies and irregularly sampled data.
Recently, researchers have adapted Mamba for computer vision tasks, similar to how Vision Transformers (ViT) are used. Vision Mamba (ViM) improves efficiency by utilizing a bidirectional state space model (SSM), addressing the high computational demands of traditional Transformers, especially for high-resolution images.
Mamba Architecture:
Mamba enhances the S4 model by introducing a unique selection mechanism that adapts parameters based on input, allowing it to focus on relevant information within sequences. This time-varying framework improves computational efficiency.
Mamba also employs a hardware-aware algorithm for efficient computation on modern hardware like GPUs, optimizing performance and memory usage. The architecture integrates SSM design with MLP blocks, making it suitable for various data types, including language, audio, and genomics.
Paperspace GPUs provide a powerful and flexible cloud-based solution for training and deploying deep learning models, making them well-suited for tasks like those involving the Mamba architecture. With high-performance GPUs, Paperspace allows researchers to efficiently handle the computational demands of Mamba models, particularly when dealing with long sequences and complex token mixing operations.
The platform supports popular deep learning libraries like PyTorch, enabling seamless integration and streamlined workflows. Utilizing Paperspace GPUs can significantly accelerate the training process, enhance model performance, and facilitate large-scale experimentation and development of advanced models.
Mamba Variants:
- MambaByte: A token-free language model that processes raw byte sequences, eliminating tokenization and its associated biases.
- Mamba Mixture of Experts (MOE): Integrates Mixture of Experts with Mamba, enhancing efficiency and scalability by alternating Mamba and MOE layers.
- Vision Mamba (ViM):
ViM adapts SSMs for visual data processing, using bidirectional Mamba blocks for visual sequence encoding. This reduces computational demands and shows improved performance on tasks like ImageNet classification, COCO object detection, and ADE20k semantic segmentation. - Jamba:
Developed by AI21 Labs, Jamba is a hybrid transformer and Mamba SSM architecture with 52 billion parameters and a context window of 256k tokens.
Demo using Paperspace
Bring this project to life
Before we start working with the model, we will clone the repo and install few necessary packages,
!pip install timm==0.6.11
!git clone https://github.com/yuweihao/MambaOut.git
!pip install gradioAdditionally, we have added a link that can be used to access the notebook that runs the steps and will perform inferences with MambaOut.
cd /MambaOutThe cell below will help you run the gradio web app.
!python gradio_demo/app.pyMambaOut Demo using Paperspace
RNN-like models and causal attention
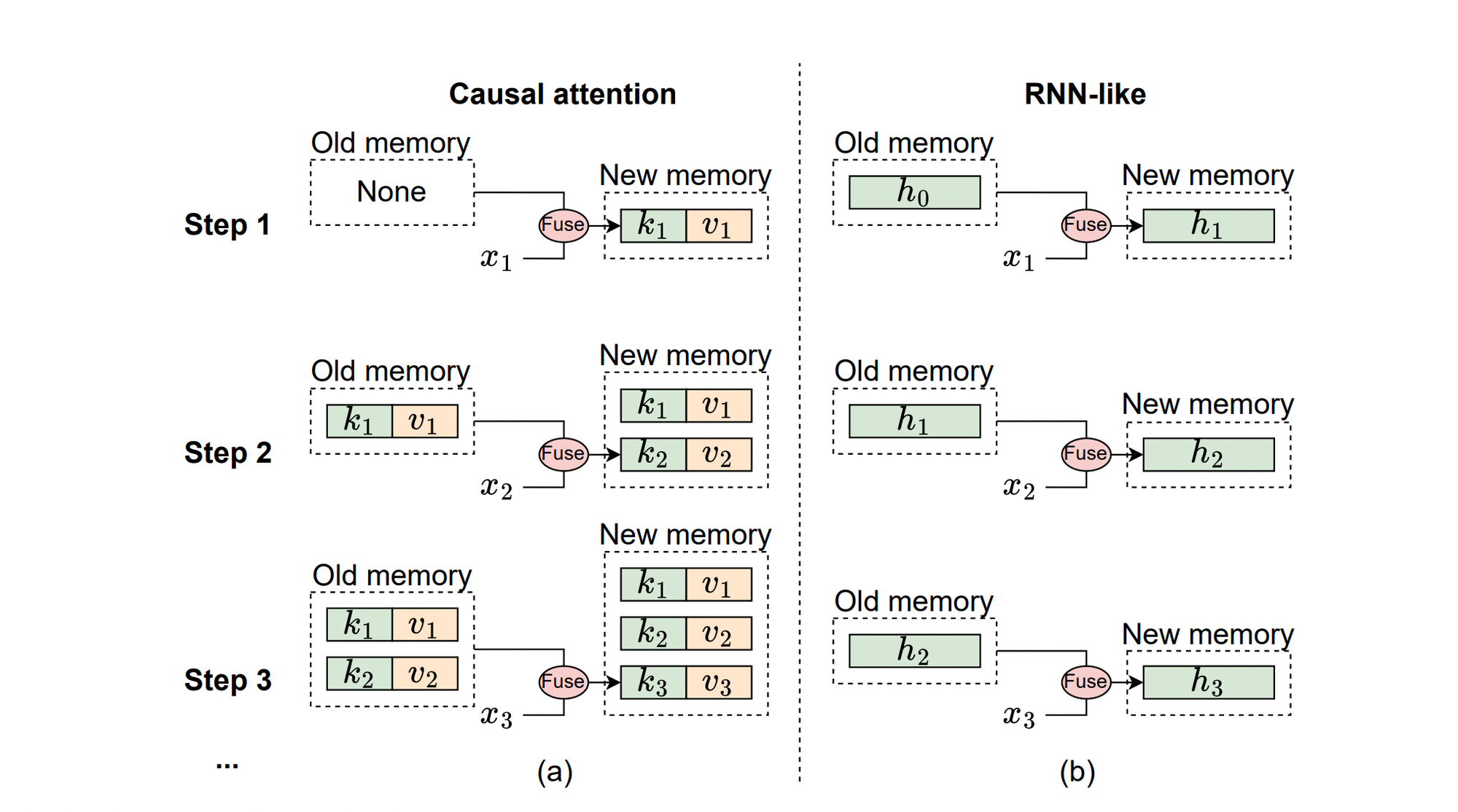
The below illustration explains the mechanism of causal attention and RNN-like models from a memory perspective, where xi represents the input token at the i-th step.
(a) Causal Attention: Stores all previous tokens' keys (k) and values (v) as memory. The memory is updated by continually adding the current token's key and value, making it lossless. However, the computational complexity of integrating old memory with current tokens increases as the sequence lengthens. Thus, attention works well with short sequences but struggles with longer ones.
(b) RNN-like Models: Compress previous tokens into a fixed-size hidden state (h) that serves as memory. This fixed size means RNN memory is inherently lossy and can't match the lossless memory capacity of attention models. Nevertheless, RNN-like models excel in processing long sequences, as the complexity of merging old memory with current input remains constant, regardless of sequence length.
Mamba is particularly well-suited for tasks that require causal token mixing due to its recurrent properties. Specifically, Mamba excels in tasks with the following characteristics:
- The task involves processing long sequences.
- The task requires causal token mixing.
The next question rises is does visual recognition tasks have very long sequences?
For image classification on ImageNet, the typical input image size is 224x224, resulting in 196 tokens with a patch size of 16x16. This number is much smaller than the thresholds for long-sequence tasks, so ImageNet classification is not considered a long-sequence task.
For object detection and instance segmentation on COCO, with an image size of 800x1280, and for semantic segmentation on ADE20K (ADE20K is a widely-used dataset for the semantic segmentation task, consisting of 150 semantic categories. The dataset includes 20,000 images in the training set and 2,000 images in the validation set), with an image size of 512x2048, the number of tokens is around 4,000 with a patch size of 16x16. Since 4,000 tokens exceed the threshold for small sequences and are close to the base threshold, both COCO detection and ADE20K segmentation are considered long-sequence tasks.
Framework of MambaOut
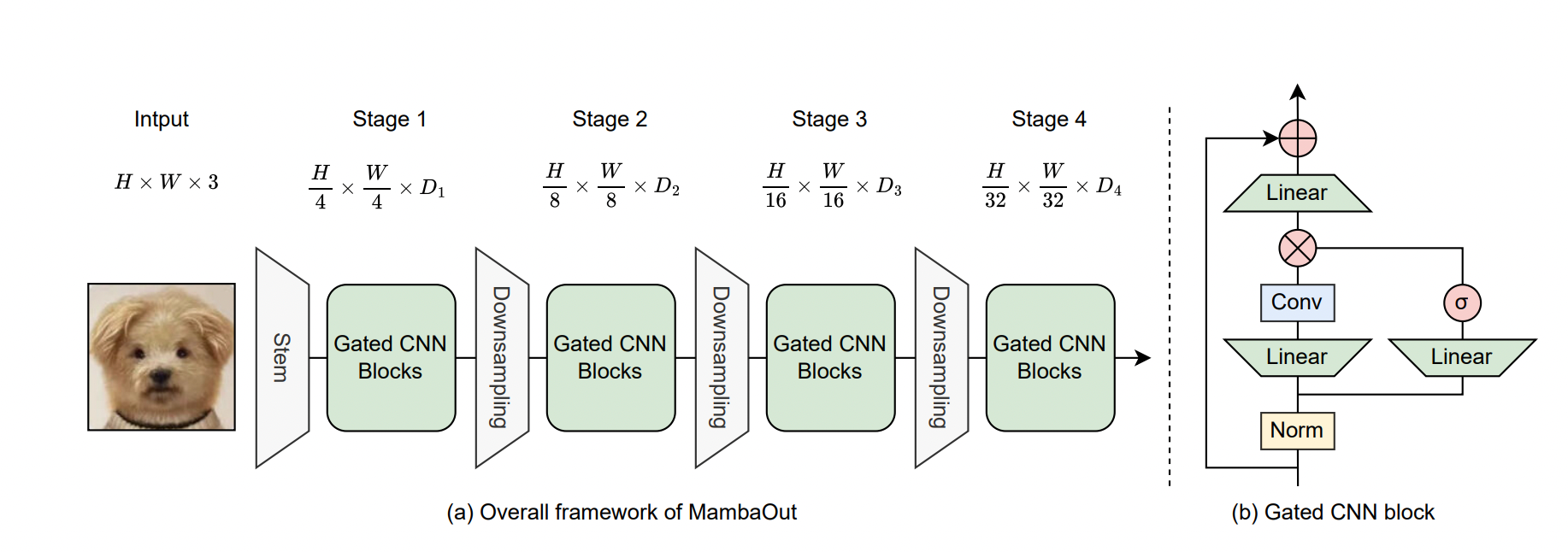
Fig (a) represents overall Framework of MambaOut for Visual Recognition:
MambaOut is designed for visual recognition and follows a hierarchical architecture similar to ResNet. It consists of four stages, each with different channel dimensions, denoted as Di. This hierarchical structure allows the model to process visual information at multiple levels of abstraction, enhancing its ability to recognize complex patterns in images.
(b) Architecture of the Gated CNN Block:
The Gated CNN block is a component within the MambaOut framework. It differs from the Mamba block in that it does not include the State Space Model (SSM). While both blocks use convolutional neural networks (CNNs) with gating mechanisms to regulate information flow, the absence of SSM in the Gated CNN block means it does not have the same capacity for handling long sequences and temporal dependencies as the Mamba block, which incorporates SSM for these purposes.
The primary difference between the Gated CNN and the Mamba block lies in the presence of the State Space Model (SSM).
In MambaOut, a depthwise convolution with a 7x7 kernel size is used as the token mixer of the Gated CNN, similar to ConvNeXt. Similar to ResNet, MambaOut is built using a 4-stage framework by stacking Gated CNN blocks at each stage, as illustrated in Figure.
Before we move further here are the hypothesis regarding the necessity of introducing Mamba for visual recognition.
Hypothesis 1: It is not necessary to introduce SSM for image classification on ImageNet, as this task does not meet Characteristic 1 or Characteristic 2.
Hypothesis 2: It is still worthwhile to further explore the potential of SSM for visual detection and segmentation since these tasks align with Characteristic 1, despite not fulfilling Characteristic 2.
Training
Image classification on ImageNet
- ImageNet is used as the benchmark for image classification, with 1.3 million training images and 50,000 validation images.
- Training follows the DeiT scheme without distillation, including various data augmentation techniques and regularization methods.
- AdamW optimizer is used for training, with a learning rate scaling rule of lr = batchsize/1024 * 10^-3, resulting in a learning rate of 0.004 with a batch size of 4096.
- MambaOut models are implemented using PyTorch and timm libraries and trained on TPU v3.
Results
- MambaOut models, which do not incorporate SSM, consistently outperform visual Mamba models across all model sizes on ImageNet.
- For example, the MambaOut-Small model achieves a top-1 accuracy of 84.1%, outperforming LocalVMamba-S by 0.4% while requiring only 79% of the MACs.
- These results support Hypothesis 1 , suggesting that introducing SSM for image classification on ImageNet is unnecessary.
- Visual Mamba models currently lag significantly behind state-of-the-art convolution and attention models on ImageNet.
- For instance, CAFormer-M36 outperforms all visual Mamba models of comparable size by more than 1% accuracy.
- Future research aiming to challenge Hypothesis 1 may need to develop visual Mamba models with token mixers of convolution and SSM to achieve state-of-the-art performance on ImageNet.
Object detection & instance segmentation on COCO
- COCO 2017 is used as the benchmark for object detection and instance segmentation.
- MambaOut is utilized as the backbone within Mask R-CNN, initialized with weights pre-trained on ImageNet.
- Training follows the standard 1× schedule of 12 epochs, with training images resized to have a shorter side of 800 pixels and a longer side not exceeding 1333 pixels.
- The AdamW optimizer is employed with a learning rate of 0.0001 and a total batch size of 16.
- Implementation is done using the PyTorch and mmdetection libraries, with FP16 precision utilized to save training costs.
- Experiments are conducted on 4 NVIDIA 4090 GPUs.
Results
- While MambaOut can outperform some visual Mamba models in object detection and instance segmentation on COCO, it still lags behind state-of-the-art visual Mambas like VMamba and LocalVMamba.
- For example, MambaOut-Tiny as the backbone for Mask R-CNN trails VMamba-T by 1.4 APb and 1.1 APm.
- This performance difference highlights the benefits of integrating Mamba in long-sequence visual tasks, supporting Hypothesis 2.
- However, visual Mamba still shows a significant performance gap compared to state-of-the-art convolution-attention-hybrid models like TransNeXt. Visual Mamba needs to demonstrate its effectiveness by outperforming other state-of-the-art models in visual detection tasks.
Semantic segmentation on ADE20K
- ADE20K is used as the benchmark for the semantic segmentation task, comprising 150 semantic categories with 20,000 images in the training set and 2,000 images in the validation set.
- Mamba is utilized as the backbone for UperNet, with initialization from ImageNet pre-trained weights.
- Training is conducted using the AdamW optimizer with a learning rate of 0.0001 and a batch size of 16 for 160,000 iterations.
- Implementation is done using the PyTorch and mmsegmentation libraries, with experiments performed on four NVIDIA 4090 GPUs, utilizing FP16 precision to enhance training speed.
Results
- Similar to object detection on COCO, the performance trend for semantic segmentation on ADE20K shows that MambaOut can outperform some visual Mamba models but cannot match the results of state-of-the-art Mamba models.
- For example, LocalVMamba-T surpasses MambaOut-Tiny by 0.5 mIoU in both single scale (SS) and multi-scale (MS) evaluations, further supporting Hypothesis 2 empirically.
- Additionally, visual Mamba models continue to exhibit notable performance deficits compared to more advanced hybrid models that integrate convolution and attention mechanisms, such as SG-Former and TransNeXt.
- Visual Mamba needs to further demonstrate its strengths in long-sequence modeling by achieving stronger performance in the visual segmentation task.
Conclusion
Mamba mechanism is best suited for tasks with long sequences and autoregressive characteristics. Mamba shows potential for visual detection and segmentation tasks, which do align with long-sequence characteristics. MambaOut models that surpass all visual Mamba models on ImageNet, yet still lag behind state-of-the-art visual Mamba models.
However, due to computational resource limitations, this paper focuses on verifying the Mamba concept for visual tasks. Future research could further explore Mamba and RNN concepts, as well as the integration of RNN and Transformer for large language models (LLMs) and large multimodal models (LMMs), potentially leading to new advancements in these areas.










