
Volta is one of the latest GPU architectures developed by NVIDIA. Volta was specifically designed and optimized for training deep neural networks and for machine learning research. One of the main characteristics of this new architecture is that it includes Tensor Cores, a programmable matrix-multiply-and-accumulate units that can deliver up to 125 Tensor FLOPS for training and inference applications[1]. Basically, a new and more efficient way to increase the compute time of matrix manipulation. This optimization allows better performance when training deep neural networks and boosts training speed. (If you want and in depth technical definition of how Tensor Cores work, check out this NVIDIA blog post on the topic.)
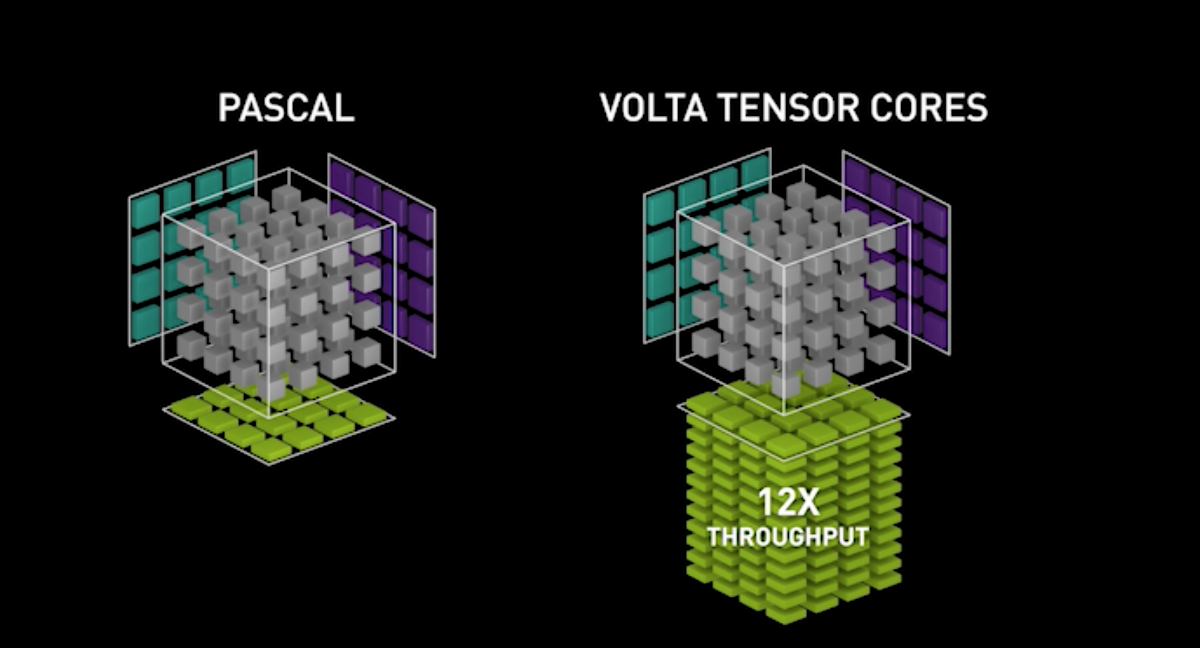
A big advantage of this new architecture design is that it also uses and benefits from lower-precision arithmetic to make calculations faster. This is done by using half-precision floating point numbers instead of single precision.
Half Precision vs Single Precision
A big part of training and developing a deep neural network model, if not most of it, has to do computing the weights, activation functions, inputs and outputs of the network. When using GPU accelerated computing this is managed and computed at lower level by CUDA. CUDA normally stores and keeps track of all the variables involved in training with single precision floating point numbers using 32 bits (FP32) of memory for every number. Using FP32 means higher precision for performing arithmetic computations but also more memory to store all those variables. By contrast, half precision floating number are stored using only 16 bit (FP16) and therefore, use less memory than FP32. The downside is that the precision will not be the same as with FP32. This means that you might get imprecise weight updates, gradients underflow, reductions overflow when training a network.
So how can we benefit from Volta's architectural advantage and ability to use 16 bit floating point number and speed up the training but don't lose precision? The answer has to do with mixed precision training. Mixed precision training is a way of performing some calculations and operations using a combination of FP16 and FP32. For instance, Tensor Core can multiple half precision matrices and accumulate the result into a single precision matrix. Using mixed precision and Volta, networks can:
- Be 2-4x faster than using single precision
- Reduce the size of the network by half
- Does not imply an architectural change to the model.
Using Mixed precision training in Pytorch
As stated in the official NVIDIA documentation, using mixed precision in Pytorch only involves casting the necessary variables and models to half:
model = model.cuda().half()
input = input.cuda().half()
Keep in mind this casting is only done in some parts of the training loop. In the best scenario you will have a FP16 model with the final weights but the training and computation will be done using a mix of FP32 and FP16. For an in-depht explanation of how to use FP16 in Pytorch, Sylvain Gugger wrote an excellent introduction you can find here.
References
- [1] Programming Tensor Cores in CUDA 9 - https://devblogs.nvidia.com/programming-tensor-cores-cuda-9/
- [2] NVIDIA GPU Technology Conference - http://on-demand.gputechconf.com/gtc/2018/video/S81012/
- [3] Fast.ai: Mixed precision training post - http://forums.fast.ai/t/mixed-precision-training/20720









