[12/2/2021 Update: This article contains information about Gradient Experiments. Experiments are now deprecated, and Gradient Workflows has replaced its functionality. Please see the Workflows docs for more information.]
Introducing the new Gradient Python SDK for machine learning model training, building, and deployment. Build out complex end-to-end machine learning pipelines with ease.
For many machine learning developers the ability to interact with their development process through a simple programmatic API has been a long-standing request. The SDK joins our Command-line utility, our builder GUI, and the GradientCI build automation tool as a first-class citizen for building and deploying machine learning models in Gradient.
Note: View the sample Notebook that contains and an end-to-end example you can run in your own account.
Installing
pip install --pre gradient
Quick Start
#Import the SdkClient from the gradient package
from gradient import sdk_client
#create a API Key
api_key = os.getenv("PS_API_KEY")
#access all paperspace entities from a single client
client = sdk_client.SdkClient(api_key)
This new library allows you to programmatically interact with Gradient from within a Python script or application. It supplements the Gradient CLI functionality with the added ability to automate actions and pipelines.
The following is an example using the SDK to perform multinode with multiple workers & a parameter server, observe the state transitions of the experiment & stream the logs during training. After training completes, we take the associated tensorflow model & deploy it for inference using TFServing as a rest endpoint backed by multi-instance GPUs w/ load balancing.
Instantiate the SDK clients
client = sdk_client.SdkClient(api_key)
#or access each component from its own client
deployment_client = sdk_client.DeploymentsClient(api_key)
models_client = sdk_client.ModelsClient(api_key)
jobs_client = sdk_client.JobsClient(api_key)
projects_client = sdk_client.ProjectsClient(api_key)
experiment_client = sdk_client.ExperimentsClient(api_key)
Create a project
project_id = client.projects.create("new project")
The SDK returns the id of any create calls as python objects to enable easy scripting.
Create a multinode distributed experiment
Step 1: Setup the hyperparameters
#Create a dictionary of parameters for running a distributed/multinode experiment
env = {
"EPOCHS_EVAL":5,
"TRAIN_EPOCHS":10,
"MAX_STEPS":1000,
"EVAL_SECS":10
}
Step 2: Create a dictionary with experiment parameters
multi_node_parameters = {
"name": "multinode_mnist",
"project_id": project_id,
"experiment_type_id": 2,
"worker_container": "tensorflow/tensorflow:1.13.1-gpu-py3",
"worker_machine_type": "K80",
"worker_command": "pip install -r requirements.txt && python mnist.py",
"experiment_env": env,
"worker_count": 2,
"parameter_server_container": "tensorflow/tensorflow:1.13.1-gpu-py3",
"parameter_server_machine_type": "K80",
"parameter_server_command": "pip install -r requirements.txt && python mnist.py",
"parameter_server_count": 1,
"workspace_url": "https://github.com/Paperspace/mnist-sample.git",
"model_path": "/storage/models/tutorial-mnist/",
"model_type": "Tensorflow"
}
Step 3: Run the training experiment
#pass the dictionary into experiments client
experiment_id =
client.experiments.run_multi_node(**multi_node_parameters)
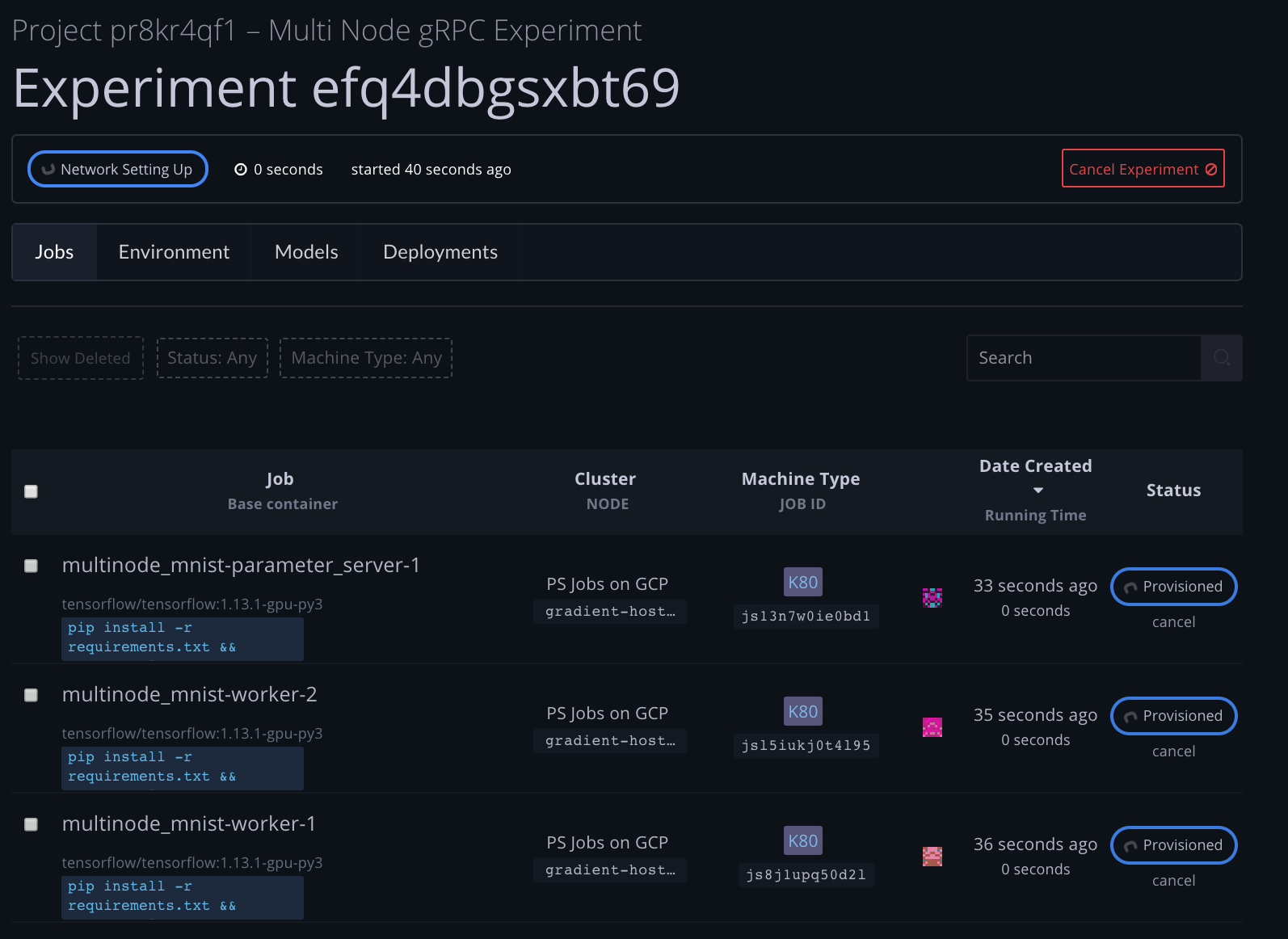
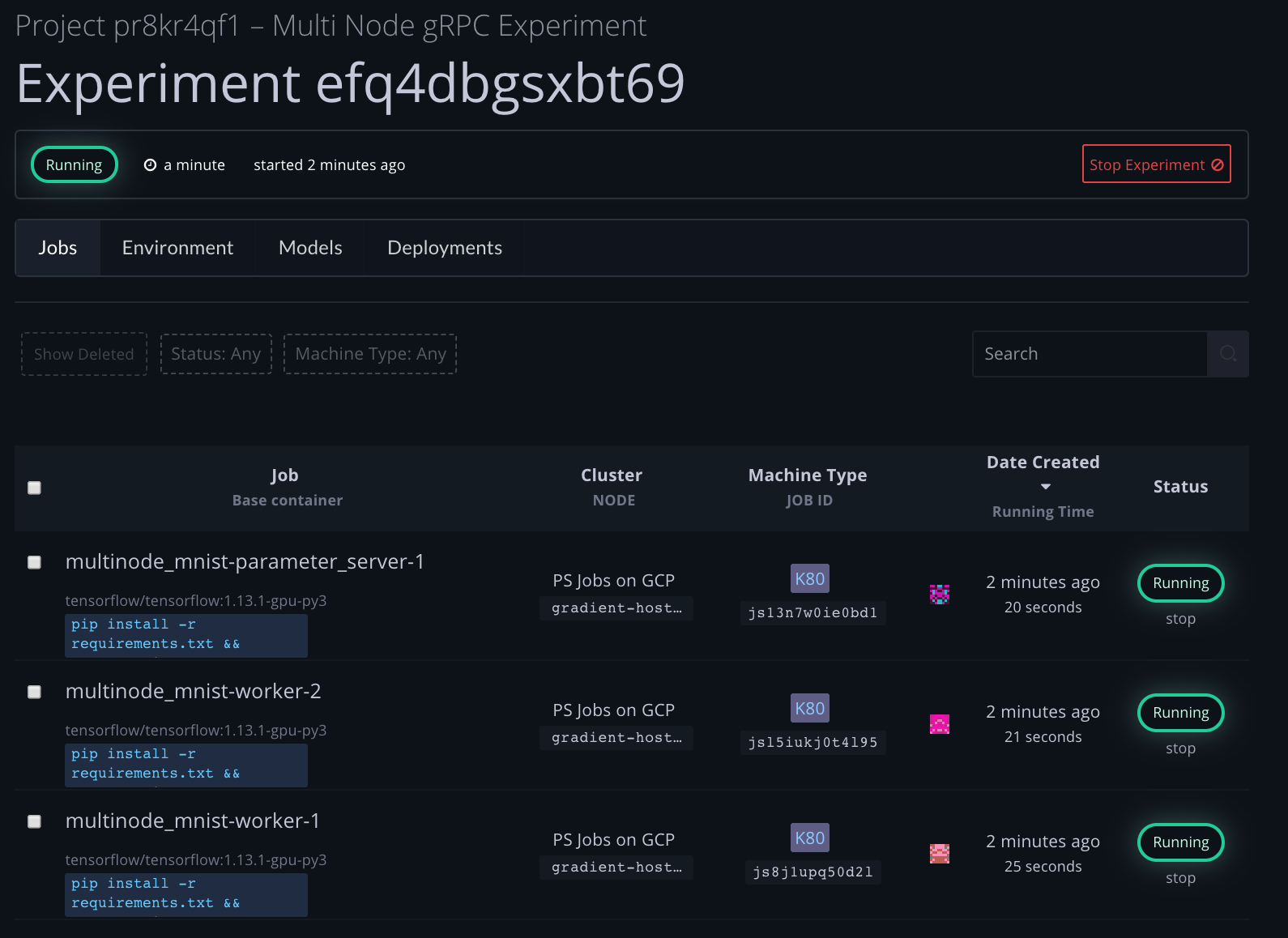
Step 3a: Watch the state transitions as experiment launches
from gradient import constants.ExperimentState
print("Watching state of experiment")
state = ""
while state != "running":
new_state = client.experiments.get(experiment_id).state
new_state = ExperimentState.get_state_str(new_state)
if new_state != state:
print("state: "+new_state)
state = new_state
Watching state of experiment
state: created
state: provisioning
state: provisioned
state: network setting up
state: network setup
state: running
Step 3b: Stream the logs during runtime
log_streamer =
client.experiments.yield_logs(experiment_id)
print("Streaming logs of experiment")
try:
while True:
print(log_streamer.send(None))
except:
print("done streaming logs")
Streaming logs of experiment
LogRow(line=115, message='2019-08-30 02:14:55.746696: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] Created TensorFlow device (/job:worker/replica:0/task:1/device:GPU:0 with 10790 MB memory) -> physical GPU (device: 0, name: Tesla K80, pci bus id: 0000:00:04.0, compute capability: 3.7)', timestamp='2019-08-30T02:14:55.747Z')
LogRow(line=115, message='2019-08-30 02:14:54.799712: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] Created TensorFlow device (/job:master/replica:0/task:0/device:GPU:0 with 10790 MB memory) -> physical GPU (device: 0, name: Tesla K80, pci bus id: 0000:00:04.0, compute capability: 3.7)', timestamp='2019-08-30T02:14:54.799Z')
LogRow(line=115, message='2019-08-30 02:14:55.041046: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] Created TensorFlow device (/job:ps/replica:0/task:0/device:GPU:0 with 10790 MB memory) -> physical GPU (device: 0, name: Tesla K80, pci bus id: 0000:00:04.0, compute capability: 3.7)', timestamp='2019-08-30T02:14:55.041Z')
LogRow(line=116, message='2019-08-30 02:14:55.043605: I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:252] Initialize GrpcChannelCache for job master -> {0 -> 10.138.0.213:5000}', timestamp='2019-08-30T02:14:55.043Z')
LogRow(line=116, message='2019-08-30 02:14:54.802267: I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:252] Initialize GrpcChannelCache for job master -> {0 -> localhost:5000}', timestamp='2019-08-30T02:14:54.802Z')
LogRow(line=116, message='2019-08-30 02:14:55.749520: I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:252] Initialize GrpcChannelCache for job master -> {0 -> 10.138.0.213:5000}', timestamp='2019-08-30T02:14:55.749Z')
LogRow(line=117, message='2019-08-30 02:14:55.749569: I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:252] Initialize GrpcChannelCache for job ps -> {0 -> 10.138.0.71:5000}', timestamp='2019-08-30T02:14:55.749Z')
LogRow(line=117, message='2019-08-30 02:14:54.802300: I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:252] Initialize GrpcChannelCache for job ps -> {0 -> 10.138.0.71:5000}', timestamp='2019-08-30T02:14:54.802Z')
LogRow(line=117, message='2019-08-30 02:14:55.043637: I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:252] Initialize GrpcChannelCache for job ps -> {0 -> localhost:5000}', timestamp='2019-08-30T02:14:55.043Z')
LogRow(line=118, message='2019-08-30 02:14:55.043659: I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:252] Initialize GrpcChannelCache for job worker -> {0 -> 10.138.0.213:5000, 1 -> 10.138.0.29:5000}', timestamp='2019-08-30T02:14:55.043Z')
LogRow(line=118, message='2019-08-30 02:14:54.802311: I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:252] Initialize GrpcChannelCache for job worker -> {0 -> 10.138.0.213:5000, 1 -> 10.138.0.29:5000}', timestamp='2019-08-30T02:14:54.802Z')
LogRow(line=136, message='I0830 02:14:57.358003 140254722529024 basic_session_run_hooks.py:594] Saving checkpoints for 0 into /storage/models/tutorial-mnist/mnist/model.ckpt.', timestamp='2019-08-30T02:14:57.358Z')
LogRow(line=136, message='I0830 02:15:06.821857 140249388017408 session_manager.py:493] Done running local_init_op.', timestamp='2019-08-30T02:15:06.822Z')
LogRow(line=137, message='I0830 02:14:58.314819 140254722529024 util.py:164] Initialize strategy', timestamp='2019-08-30T02:14:58.315Z')
LogRow(line=137, message='I0830 02:15:06.949163 140249388017408 util.py:164] Initialize strategy', timestamp='2019-08-30T02:15:06.949Z')
LogRow(line=138, message='2019-08-30 02:14:58.421029: I tensorflow/stream_executor/dso_loader.cc:152] successfully opened CUDA library libcublas.so.10.0 locally', timestamp='2019-08-30T02:14:58.421Z')
LogRow(line=138, message='I0830 02:15:14.057311 140249388017408 basic_session_run_hooks.py:249] cross_entropy = 0.34506965, learning_rate = 1e-04, train_accuracy = 0.94', timestamp='2019-08-30T02:15:14.057Z')
LogRow(line=139, message='I0830 02:15:14.057899 140249388017408 basic_session_run_hooks.py:249] loss = 0.34506965, step = 159', timestamp='2019-08-30T02:15:14.058Z')
LogRow(line=139, message='I0830 02:15:04.954904 140254722529024 basic_session_run_hooks.py:249] cross_entropy = 2.3063064, learning_rate = 1e-04, train_accuracy = 0.11', timestamp='2019-08-30T02:15:04.955Z')
LogRow(line=140, message='I0830 02:15:15.893357 140249388017408 basic_session_run_hooks.py:247] cross_entropy = 0.09328934, learning_rate = 1e-04, train_accuracy = 0.945 (1.836 sec)', timestamp='2019-08-30T02:15:15.893Z')
Now View & Deploy the resulting model
model = client.models.list(experiment_id = experiment_id)
deploy_param = {
"deployment_type" : "Tensorflow Serving on K8s",
"image_url": "tensorflow/serving:latest-gpu",
"name": "sdk_tutorial",
"machine_type": "K80",
"instance_count": 2,
"model_id" : model[0].id
}
mnist = client.deployments.create(**deploy_param)
client.deployments.start(mnist)
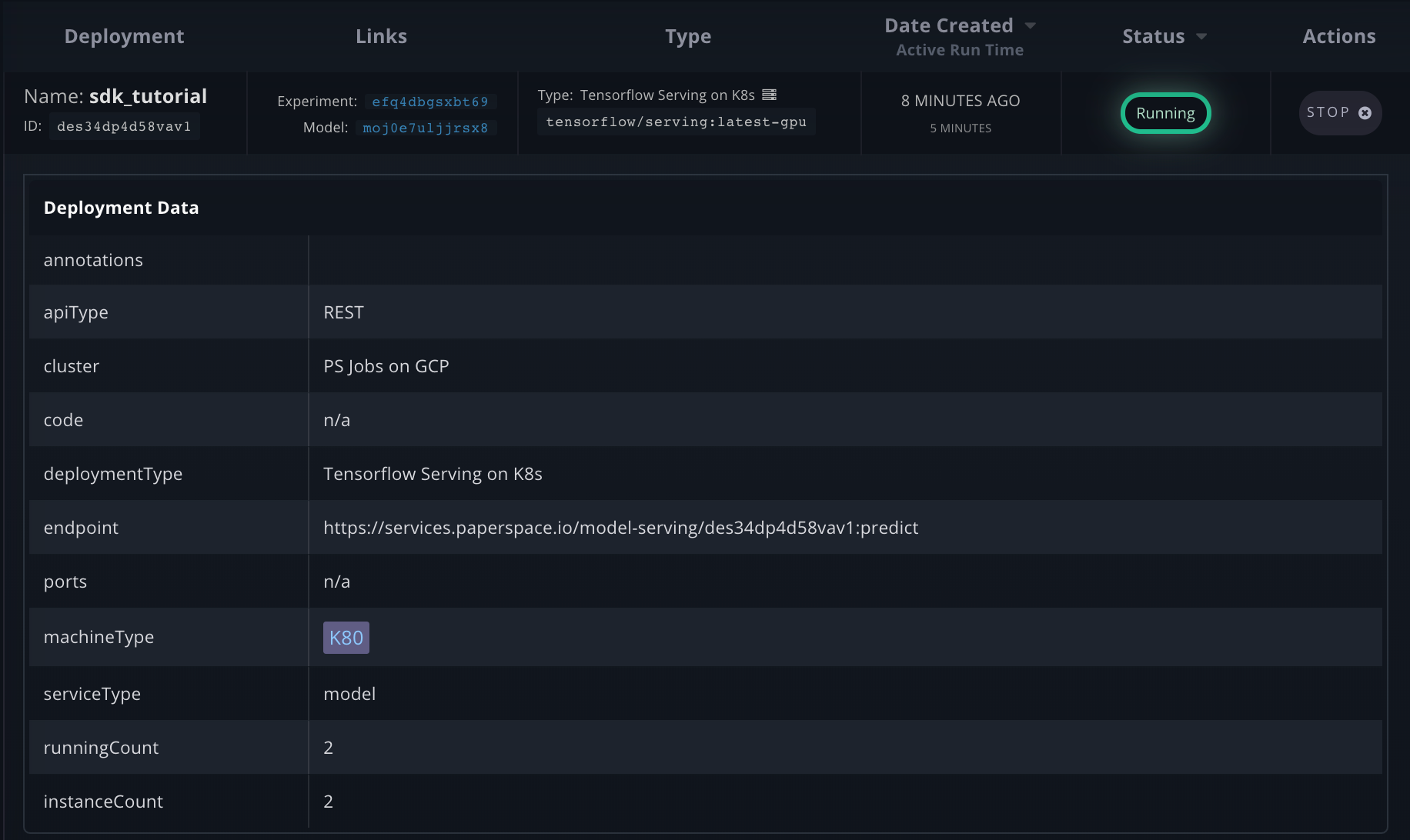
deployment = client.deployments.list(model_id=model[0].id)
Programatically get the resulting endpoint
print(deployment)
print("Endpoint: "+deployment[0].endpoint)
[Deployment(id_='des34dp4d58vav1', name='sdk_tutorial', endpoint='https://services.paperspace.io/model-serving/des34dp4d58vav1:predict', api_type='REST', state='Running', model_id='moj0e7uljjrsx8', project_id='pr8kr4qf1', image_url='tensorflow/serving:latest-gpu', deployment_type='Tensorflow Serving on K8s', machine_type='K80', instance_count=2)]
Endpoint: 'https://services.paperspace.io/model-serving/des34dp4d58vav1:predict'
Performing inference
image = get_image_from_drive('example5.png')
show_selected_image(image)
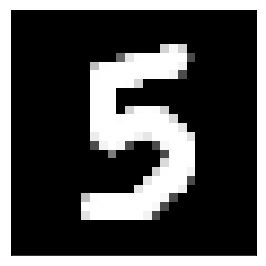
def make_prediction_request(image, prediction_url):
vector = make_vector(image)
json = {
"inputs": [vector]
}
response = requests.post(prediction_url, json=json)
print('HTTP Response %s' % response.status_code)
print(response.text)
make_prediction_request(image, deployment[0].endpoint)
Send a post request to REST endpoint & get classification
HTTP Response 200
{
"outputs": {
"classes": [
5
],
"probabilities": [
[
0.0,
0.0,
0.0,
0.0,
0.0,
1.0,
0.0,
0.0,
Additional resources