


This blog breaks down one of the most overlooked GPU characteristics: memory bandwidth. We will dive into what GPU memory bandwidth is and look at why it should be taken into consideration as one of the qualities an ML expert should look for in a machine learning platform.
Understanding the memory needs for machine learning is an important component of the development process of a model. It is, nevertheless, sometimes easy to overlook.
The basic GPU anatomy
A graphics card, like a motherboard, is a printed circuit board that holds a processor, a memory, and a power management unit. It also has a BIOS chip, which retains the card's settings and performs startup diagnostics on the memory, input, and output.
The graphics processing unit (GPU) on a graphics card is somewhat analogous to the CPU on a computer’s motherboard. A GPU, on the other hand, is designed to do the complicated mathematical and geometric calculations required for graphics rendering or other machine learning related applications.
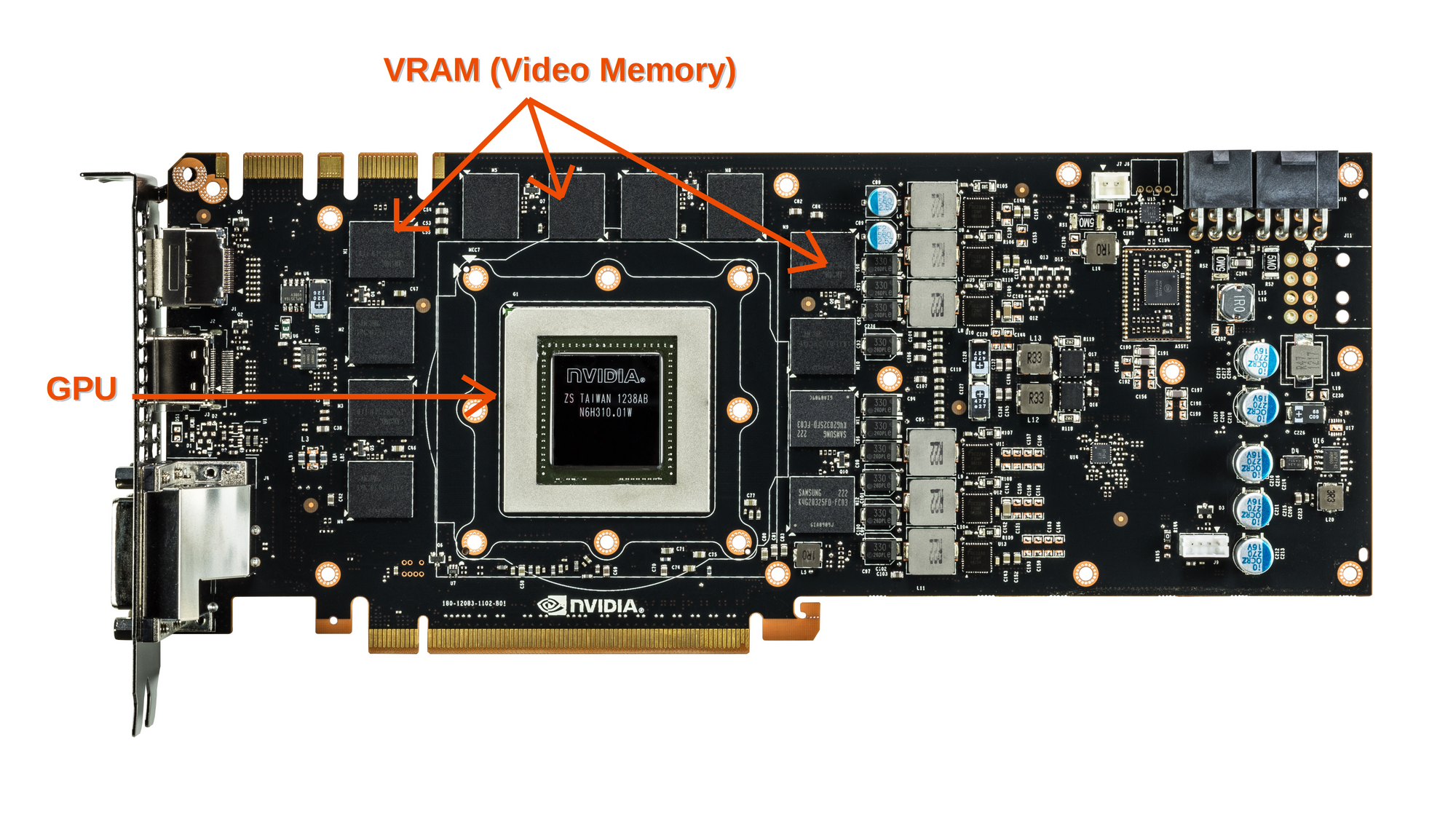
For a graphics card, the computing unit (GPU) is connected to the memory unit (VRAM, short for Video Random Access Memory) via a Bus called the memory interface.
Throughout a computer system, there are numerous memory interfaces. A memory interface is the physical bit-width of the memory bus as it relates to the GPU. Data is sent to and from the on-card memory every clock cycle (billions of times per second). The physical count of bits that may fit along the bus every clock cycle is the width of this interface, which is usually described as "384-bit" or something similar. A 384-bit memory interface allows 384 bits of data to be transferred each clock cycle. So, in establishing maximum memory throughput on a GPU, the memory interface is also an important part of the memory bandwidth calculation. As a result, NVIDIA and AMD are more likely to employ standardized serial point-to-point buses in their graphics cards. The POD125 standard, for example, is used by the A4000, A5000, and A6000 NVIDIA Ampere series graphics cards you can find available for Paperspace users, which essentially describes the communication protocol with GDDR6 vRAMs.
When it comes to memory bandwidth, latency is a second factor to consider. Originally, general-purpose buses such as the VMEbus and S-100 bus were implemented, but contemporary memory buses are designed to connect directly to VRAM chips to reduce latency.
In the case of GDDR5 and GDDR6 memories, which are one of the newest forms of GPU memory standards. Each memory is made up of two chips, each with a 32-bit bus (two parallel 16-bits) that allows multiple memory accesses at the same time. As a result, a GPU with a 256-bit memory interface will have eight GDDR6 memory chips.
Another standard for Memory types is HBM and HBM2 (high bandwidth memory v1 and v2), with these standards each HBM interface is 1024 bits offering generally higher bandwidths than GDDR5 and GDDR6.
The external PCI-Expression connection between the motherboard and the graphics card is not to be confused with this internal memory interface. This bus is also characterized by its bandwidth and speed, although it is orders of magnitude slower.
What is GPU Memory bandwidth ?
The GPU's memory bandwidth determines how fast it can move data from/to memory (vRAM) to the computation cores. It's a more representative indicator than GPU Memory Speed. It is determined by the data transmission speed between memory and computation cores, as well as the number of individual parallel links in the bus between these two parts.
Absolute memory bandwidths in consumer devices have increased by several orders of magnitude since the early 1980s home computers (~1MB/s), but available compute resources have increased even faster, and the only way to avoid constantly hitting bandwidth limits is to ensure that workloads and resources have same order of magnitude in terms of memory size and bandwidth.
Let’s take a look for example at one of the state of the art of ML oriented GPUs, the NVIDIA RTX A4000:
It comes with 16 GB of GDDR6 memory, 256-bit memory interface (number of individual links on the bus between the GPU and VRAM) and an astonishing number of CUDA Cores reaching 6144. With all these memory related characteristics, the A4000 can reach a memory bandwidth of 448 GB/s.
Other GPUs that are available for Gradient users, also offers some high performance memory characteristics:
| GPU | vRAM | Memory interface width | Memory Bandwidth | |
|---|---|---|---|---|
| P4000 | 8GB GDDR5 | 256-bit | 243 GB/s | |
| P5000 | 16GB GDDR5X | 256-bit | 288 GB/s | |
| P6000 | 24GB GDDR5X | 384-bit | 432 GB/s | |
| V100 | 32GB HBM2 | 4096-bit | 900 GB/s | |
| RTX4000 | 8GB GDDR6 | 256-bit | 416 GB/s | |
| RTX5000 | 16GB GDDR6 | 256-bit | 448 GB/s | |
| A4000 | 16GB GDDR6 | 256-bit | 448 GB/s | |
| A5000 | 24GB GDDR6 | 384-bit | 768 GB/s | |
| A6000 | 48GB GDDR6 | 384-bit | 768 GB/s | |
| A100 | 40GB HBM2 | 5120-bit | 1555 GB/s |
Why do we need high memory bandwidth for machine learning applications ?
The effect of memory bandwidth is not inherently obvious. If it’s too slow, the system will bottleneck, meaning all those thousands of GPU compute cores will be idle while they wait for a memory response. And, depending on the type of application the GPU is used for, data blocks can be processed repeatedly by the GPU (call it T times), then the external PCI bandwidth must be 1/Tth of the GPU internal bandwidth.
The most common use of a GPU demonstrates the above limitation. For example, a Model training program would load training data into GDDR RAM and make several runs for a neural network layer in the compute cores, for hours at a time. So the ratio of PCI bus bandwidth to GPU internal bandwidth can be up 20 to one.
The amount of memory bandwidth required is entirely dependent on the type of project you're working on. For example, if you're working on a deep learning project that relies on large volumes of data being fed, reprocessed, and continuously restored in memory, you'll need a wider memory bandwidth. For a video and image-based machine learning project, the requirements for memory and memory bandwidth are not as low as they are for a natural language processing or a sound processing project. For most of the average projects, a good ballpark figure is 300 GB/s to 500 GB/s. This isn't always the case, but it's usually enough memory bandwidth to accommodate a wide range of visual data machine learning applications.
Let’s look at an example of deep learning memory bandwidth requirements validation:
If we consider the 50-Layer ResNet, which has over 25 million weight parameters, and if we use 32-bit floating point to store a single parameter, it would take around 0.8GB of memory space. So, during parallel computing with a mini-batch of size 32 for example, we would need 25.6GB of memory to be loaded during each model pass. With a GPU like the A100 capable of 19.5 TFLOPs and considering that the ResNet model uses 497 GFLOPs in a single pass (for the case of a feature size 7 x 7 x 2048) we would be able to do around 39 full passes per second, which would lead to a bandwidth need of 998 GB/s. So the A100 with its bandwidth of 1555 GB/s would be able to handle this model efficiently and stay far away from bottle-necking.
How to optimize models for lower memory bandwidth usage ?
Machine learning algorithms in general and Deep neural networks in the computer vision field in particular, induce a large memory and memory bandwidth footprint. Some techniques can be used for deploying ML models in resource constrained contexts or even in powerful cloud ML services to reduce cost and time. Here are some of the strategies that can be implemented:
Partial fitting: If the dataset is too large to fit in a single pass. Instead of fitting a model on the data all at once, this feature allows you to fit a model on the data in stages. So it takes a piece of data, fits it to get a weight vector, then continues on to the next piece of data, fits it to get another weight vector, and so on. Needless to say, this lowers VRAM use while increasing training duration. The most significant flaw is that not all algorithms and implementations utilize partial fit or can be technically adjusted to do so. Nonetheless, it should be taken into account wherever possible.
Dimensionality reduction: This is important not only for reducing training time but also for reducing memory consumption during runtime. Some techniques, such as Principal component analysis (PCA), Linear discriminant analysis (LDA), or Matrix Factorization, can drastically reduce dimensionality and yield subsets of the input variables with fewer features while retaining some of the original data's important qualities.
Sparse matrix: When dealing with a sparse matrix, storing only the non-zero entries can result in significant memory savings. Different data structures can be utilized depending on the number and distribution of non-zero items, resulting in significant memory savings as compared to the basic technique. The trade-off is that accessing individual components becomes more difficult, and extra structures are required to retrieve the original matrix without ambiguity, necessitating the use of more core computes in exchange for lower memory bandwidth utilization.
Conclusion
Understanding the memory bandwidth requirements for machine learning is a crucial part of the model construction process. You now know what memory bandwidth is as a result of reading this article. Following a review of the relevance and how memory bandwidth requirements can be assessed. We discussed some of the methods for reducing bandwidth usage and lowering costs by selecting a less powerful cloud package while maintaining timing and accuracy criteria.











