
When working on data science projects to solve complex problems, or when taking a project from the exploratory stage into production, it is important for the components of the project, including code, data, models, and deployments, to be versioned.
In modern software engineering and data science work, GitHub has become the most popular way to enable versioning. Paperspace Gradient therefore enables users' projects to be linked to GitHub repositories via our integration with github.com.
In this example, we show:
- Text generation from a modern deep-learning-based natural language processing model, GPT-2
- Gradient Projects with Workflows linked to GitHub repositories
- Triggering a Workflow to rerun based upon a change in the repository, as needed in many production systems
- Versioned Gradient-managed Datasets as output
If you would like to run the examples for yourself, see our documentation page for this project, and the GitHub repository.
NLP text generation
NLP (Natural Language Processing) has emerged in the last few years as a successful application of deep learning models in a wide range of fields. Here, we show the well-known GPT-2 model running in a Gradient Workflow to generate text. An initial sentence is supplied, and the model continues the writing. This has obvious applications where auto-generation of suitable text is needed.
We use the GPT-2 text generator available from HuggingFace. This is easy to do on Gradient because we have an existing HuggingFace container that contains the necessary software dependencies, and their library supplies simple functions like pipeline() and generator() that point to the model's inference capability for text generation.
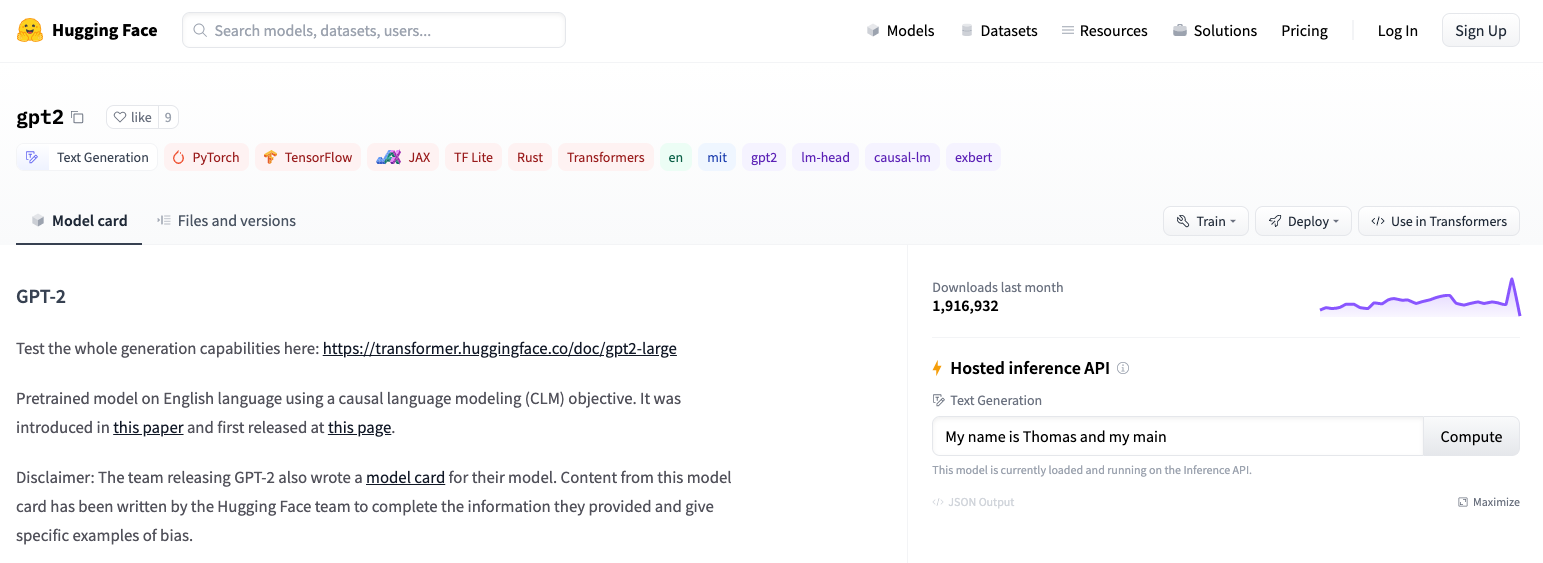
While GPT-2 is not the absolute most recent or largest NLP model available, we choose it over others such as GPT-Neo-1.3B/2.7B for a couple of reasons:
- It is one of the most used: for example, selecting the HuggingFace models list and filtering by the text generation tag, GPT-2 is the model with the most downloads.
- Many of the higher performing larger models will run just fine on Gradient, but at sizes of 5GB or 10GB+, as opposed to GPT-2's roughly 0.5GB, they take much longer to load and are thus less suitable for an example that aims to be quick to run.
When run in Gradient, in either a Notebook or a Workflow, the HuggingFace container is started, then the Python code is run. The output text can be seen directly in the cell, or directed to an output file. In the Workflow, the output file is put in a Gradient-managed dataset.
Linking Gradient Projects to GitHub repositories
Gradient Workflows are contained within Projects. To create a Project in the GUI, we navigate to our main page, where the option to create one is given. A Workflow can be created to run via the command line, or, as we do here, linked to a Github repository. The repository can be copied from one of our example templates, or you can point to one that you have set up yourself.
The Workflow creation screen looks like this:
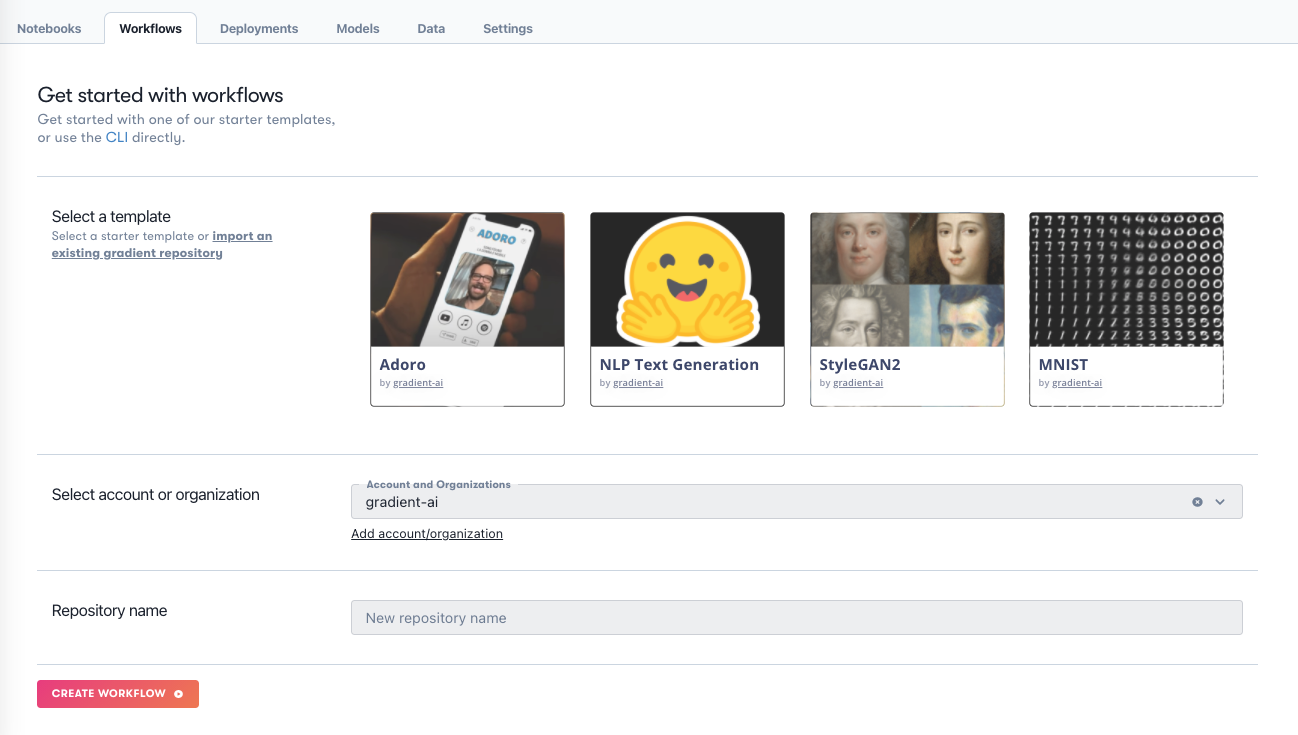
and in this case, the repo linked to is this one:
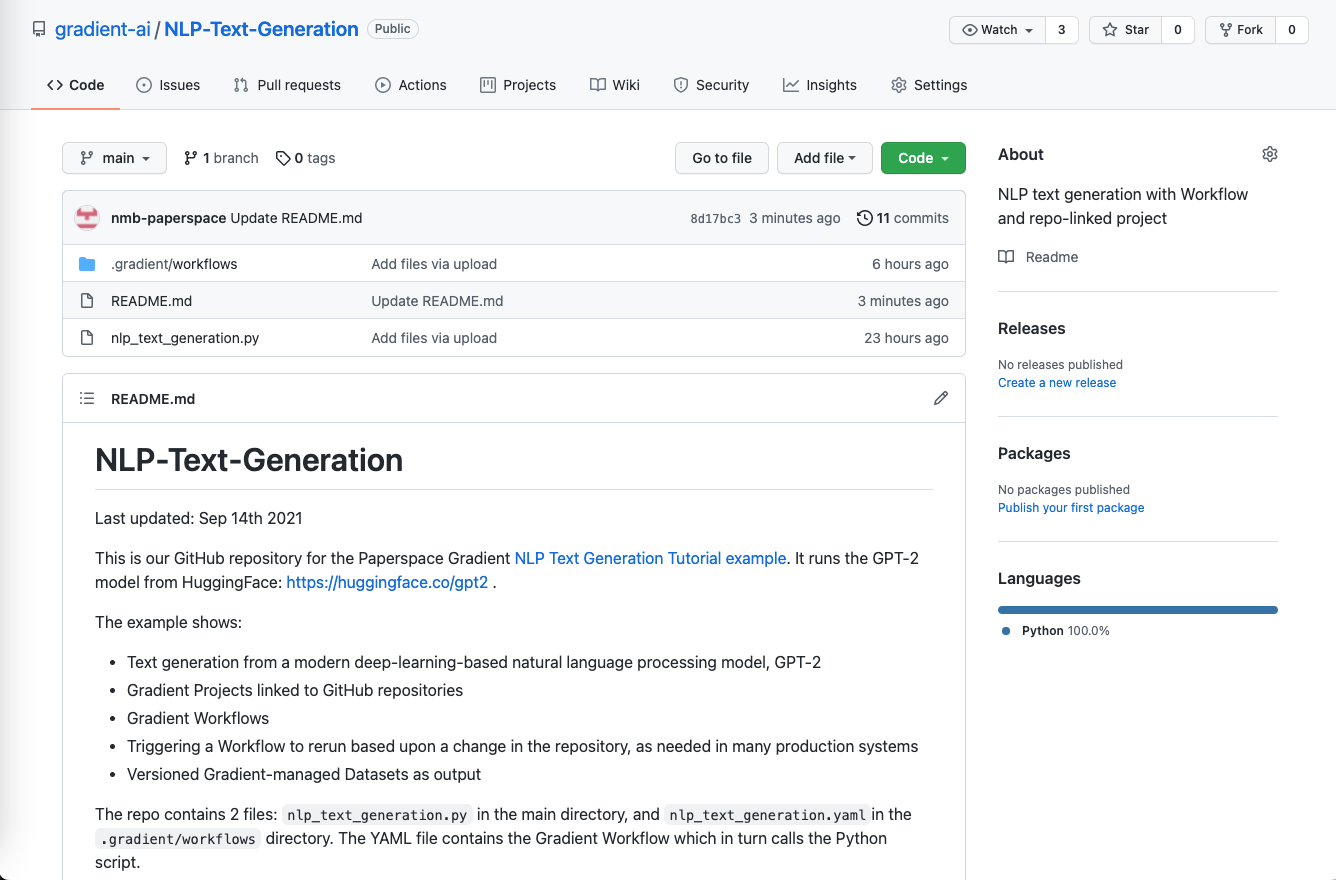
We can see the Python script that is run, and the .gradient directory containing the Workflow, explained below.
Triggering a Workflow rerun
The code to run the text generator model is
# Settings
random_seed = 42
max_length = 30
num_return_sequences = 5
initial_sentence = "Hello, I'm a language model,"
# Run generator
generator = pipeline('text-generation', model='gpt2')
set_seed(random_seed)
output = generator(initial_sentence, max_length = max_length, num_return_sequences = num_return_sequences)
We can see from this that if we change the values under Settings, the model will produce different text as output.
In an MLOps-like or production situation, we would likely want a change of model settings to trigger a rerun of the Workflow. This is easily shown in Gradient: if the file is edited and the updated version is uploaded to the GitHub repository linked to the project, then the Workflow will rerun.
This is provided that:
- The Workflow YAML file is in the directory
.gradient/workflowsin the linked repo - The YAML file contains an
onfield to indicate that it should be triggered to run when a change is made to the repo
An example of the on field is
on:
github:
branches:
only: main
which indicates that any change to the repository main branch will trigger a rerun. This ability to trigger a run, and the placement of the Workflow YAML in the .gradient/workflows directory are similar to GitHub's own Actions functionality.
Currently, if the YAML contains the above code, then any file change to the repo will trigger a rerun, but we will soon be adding the ability to configure this to more specific actions, e.g., only changing certain files causes a rerun. This will be useful when, for example, you want your correction of a typo in the README.md file to not trigger your week-long deep learning training to run again.
When a Workflow rerun is triggered in Gradient, the GUI Workflow list will show a list on the left like this:
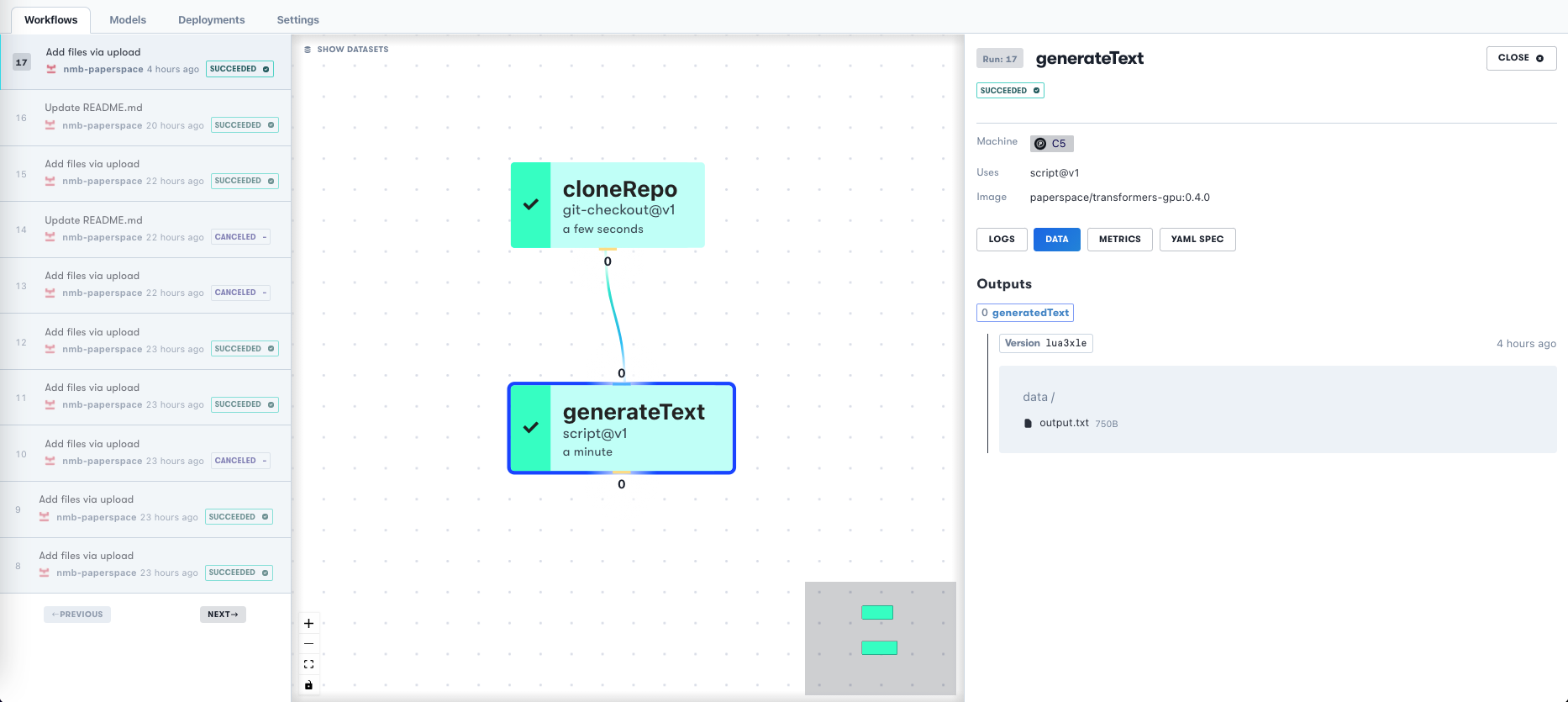
The event that triggered the rerun, for example Update README.md is shown. On the right, we can see the output.txt file from the Workflow that contains the generated text from this run.
Versioned output of Gradient Datasets
In data science, the data itself is just as important as the code or the models. However, data is not normally stored in a GitHub repository because it is too large.
Gradient therefore provides managed storage that when output to from Workflows results in versioned Gradient Datasets. Each Dataset may contain a number of individual data files, or other files, and is accessible by referring to its ID and version number.
When used in combination with a repo-linked project and Workflows, this keeps the processing done by a given Workflow consistent with the version of the data produced.
For our NLP text generation, we can therefore see which model settings produced which output.
What does the text output look like?
We can't leave, of course, without showing some example text output.
Text generated from such models is known to have various issues, such as inheriting biases from the training data supplied to it, or producing output not suitable for all audiences. Since any sentence can be supplied by the user as the initial part of the output, the potential is obvious.
It's beyond the scope of this article to address problematic output, so we just regard it as "this is what the model said", without any interpretation, and show a few examples.
Similarly, NLP text generators can be tuned for higher performance in a specific domain by training on further, more narrowly focused text. The outputs here are from the base model, with maximum output length set to 100 characters.
Hello, I'm a language model, not a programming language. Let's see how you work out your approach. By our experience, Python is the best known language to work with. It has been used in numerous programming languages, including Java, C++, R, C, C#, Lua, C#, PHP, XML, Python, Ruby and more. In addition to such languages as Lua, Javascript, PHP, BSD, PHP, PHP.
But there are some problems
Paperspace Gradient is a visualization of the gradient of the background by the relative humidity based on the total amount of current it takes to change the intensity of the source illumination. While many researchers consider this process as simple, many use the method to solve more complex and complex problems. If it turns out a few other factors would make the process more convenient, or perhaps even more efficient, for example, it might be worthwhile to start incorporating this in the design of your own lights.
Paperspace Gradient is a music editor that automatically scales up and down on the files you're working on. It's a little like how a game can now change up the sound that's playing on your home music system, on PC, iPod, or iOS.
You can also customize the way the music is played for your device, through plugins, apps, or just by tapping and holding on an instrument.
And yes, all of these features have been in the works for
MLOps is really useful. And most importantly, it helps your team's customers, which include your visitors and merchants.
The "Best Practices For Customer Performance"
What are things you would change if you started out selling services for users instead of products?
If it's not at all possible for you to get great customer service, why not start selling software for customers? The software is great. It makes your business better. It helps your customers. It saves you money by
As we can see, the model is able to create sentences that near a level of clarity akin to a human, but there is often a misuse of homographs (words with same spelling, but different meanings) and a general lack of specificity in its understanding, like with the example containing "gradient." Clearly there is potential for more to be explored.
Conclusions
In this example, we have shown
- Text generation from a modern deep-learning-based natural language processing model, GPT-2
- Gradient Projects with Workflows linked to GitHub repositories
- Triggering a Workflow to rerun based upon a change in the repository, as needed in many production systems
- Versioned Gradient-managed Datasets as output
The corresponding tutorial and GitHub repository are available.
Next steps
The usual case of what to do next depending upon what you're looking for applies, but a couple of possibilities are:
- For longer end-to-end examples of Workflows in Gradient, see the Recommender and StyleGAN2 tutorials. Recommender has a Notebook, Workflow, deployment, and non-repo-linked project. StyleGAN2 is repo-linked and shows data preparation, model training, and model inference.
- The flexible interface provided by the HuggingFace models means that the Python code shown in
nlp_text_generation.pycan be altered to use other NLP models by altering thegenerator = pipeline('text-generation', model='gpt2')line that points to the model, and thegenerator()function line to pass the right arguments. For example, the GPT-Neo series mentioned above is at https://huggingface.co/EleutherAI . GPT-Neo-125M is in fact comparable in size to GPT-2, and you can test out the larger -1.3B and -2.7B too. The latter may need a larger instance than the C5 specified in the Workflow, for example C7.











