
Data science in production requires many parts to work together for a true end-to-end capability. This includes data preparation, model training, and deployment, with both a rigorous framework in which to structure and version a project & its components, and the ability to do this at scale with large datasets.
In this project, we show:
- Data preparation using a 42 gigabyte image file and Gradient-managed Datasets
- Use of Gradient Public datasets as a data source
- Model training using StyleGAN2 deep learning on an image sample
- Model evaluation using appropriate metrics
- Model inference to generate new images
- Versioned Gradient objects, including Datasets and models
- Resource control, specifying different-sized machines for different jobs
- Triggering a Workflow rerun via changing the linked GitHub repository
all within the structure provided by Gradient Workflows.
The accompanying tutorial and GitHub repository allow you to run either the end-to-end project at full scale, or just the second part to see the model training.
StyleGAN2
Our demonstration of StyleGAN2 is based upon the popular Nvidia StyleGAN2 repository. We use its image generation capabilities to generate pictures of cats using the training data from the LSUN online database.
StyleGAN2 is an implementation of the StyleGAN method of generating images using Generative Adversarial Networks (GANs). These work by having two networks compete, one to discriminate between classes of images, and the second to try to fool the first into classifying incorrectly. In this way, the performance of the two networks is iteratively improved.
A consequence of this is that the trained network is then able to generate new images that have not been seen previously, but resemble the training set. Hence the proliferation online of pictures of people who don't exist, deepfake videos, and so on. In our case, this means our trained network can generate new pictures of cats.
Data Preparation
Typical real machine learning projects, especially deep learning, can involve using large amounts of images during training or production, and thus large amounts of data. We therefore demonstrate that Gradient Workflows can handle such large datasets in a robust way.
The cat images are stored in a 42GB-sized LMDB format database. This is downloaded from the original online location via curl:
curl -C - -o /outputs/catImageDatabase/cat.zip 'http://dl.yf.io/lsun/objects/cat.zip'
In our case, the connection is reliable, so the options shown here to resume a failed download do not need to be put in a loop in the script, but since arbitrary commands can be executed in the Workflow YAML or scripts called by it, this could be added.
We then extract the images using the Nvidia repository's dataset_tool.py command, called by the Workflow YAML in a separate job within the Workflow after the download has completed.
The images must be extracted from the supplied LMDB database format to the TensorFlow TFRecords format in multiple resolutions so that they can be passed to the model.
When the data preparation Workflow is displayed in the Gradient GUI, it looks like this
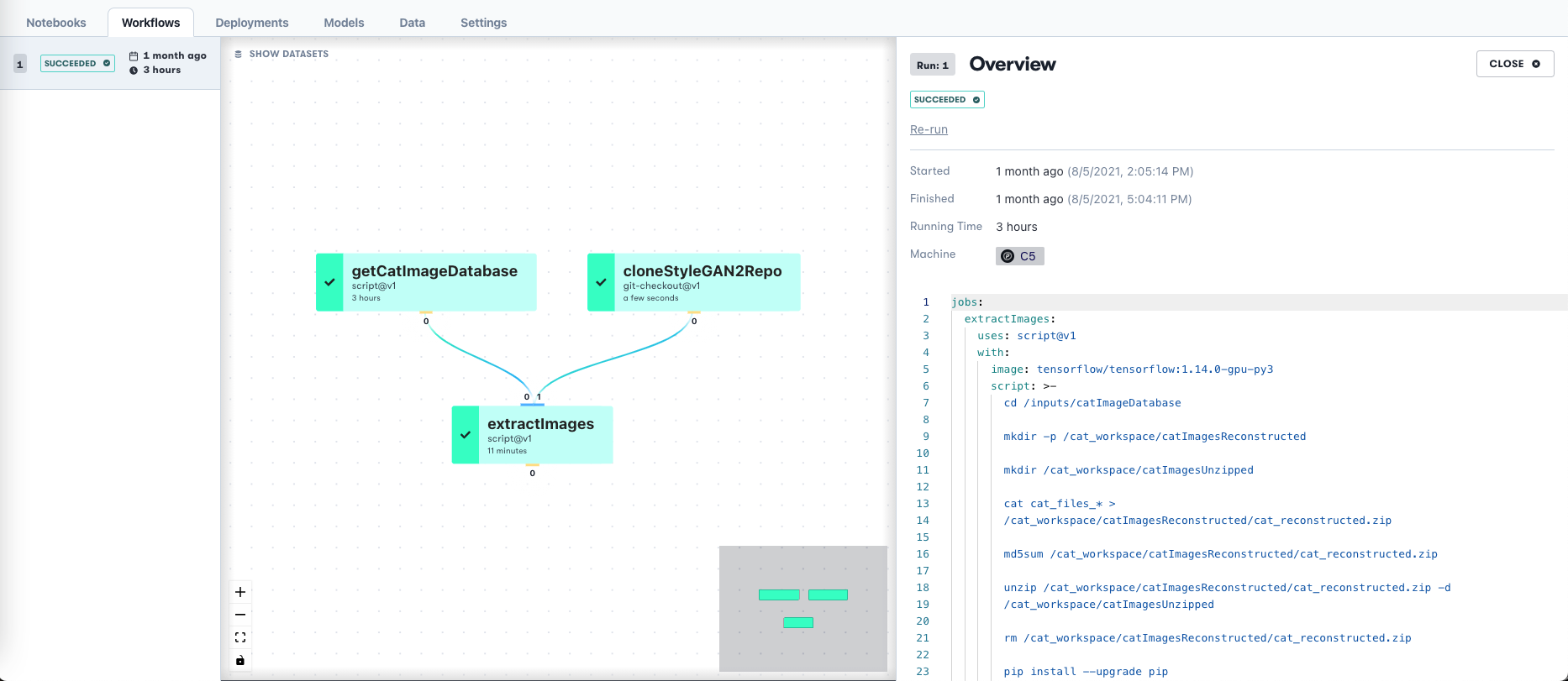
Once extracted, the images are ready to be used in the model.
Model training, inference, and evaluation
Our second Workflow of the two in the project shows both Nvidia's supplied trained model for this dataset, and our own training run of the same model.
Since the two Workflow runs are independent, this means that the second Workflow can either run on the immediate output just generated from the first Workflow, or from some other copy of the same prepared data that was made previously. We store such a previously-made copy in our Gradient Public Datasets managed storage, and in this way the second Workflow can be run without the first one, which involves a 42GB dataset download, being run again each time.
The supplied model is evaluated using appropriate metrics, and used to perform inference on new images. In other words, we use it to generate new cat images. We then do the same for our model, with the addition of training it first.
Part of the mechanism of GAN operation is the usage of both real images, and fake images generated by the network that is trying to fool the other one into classifying incorrectly.
The outputs from the script therefore include a sample of the real images, in other words, a big montage of cats:

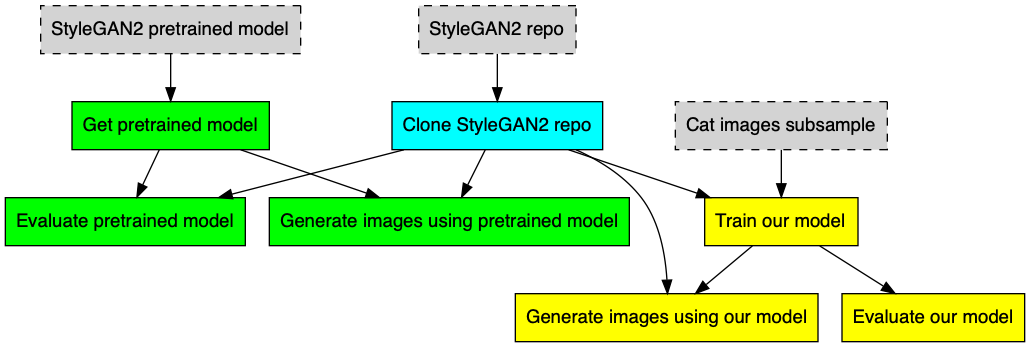
Since we are doing training, evaluation, and inference in one Workflow, this results in a more complicated diagram of what the Workflow is doing. Using GraphViz, we can color the components according to function, and this looks like
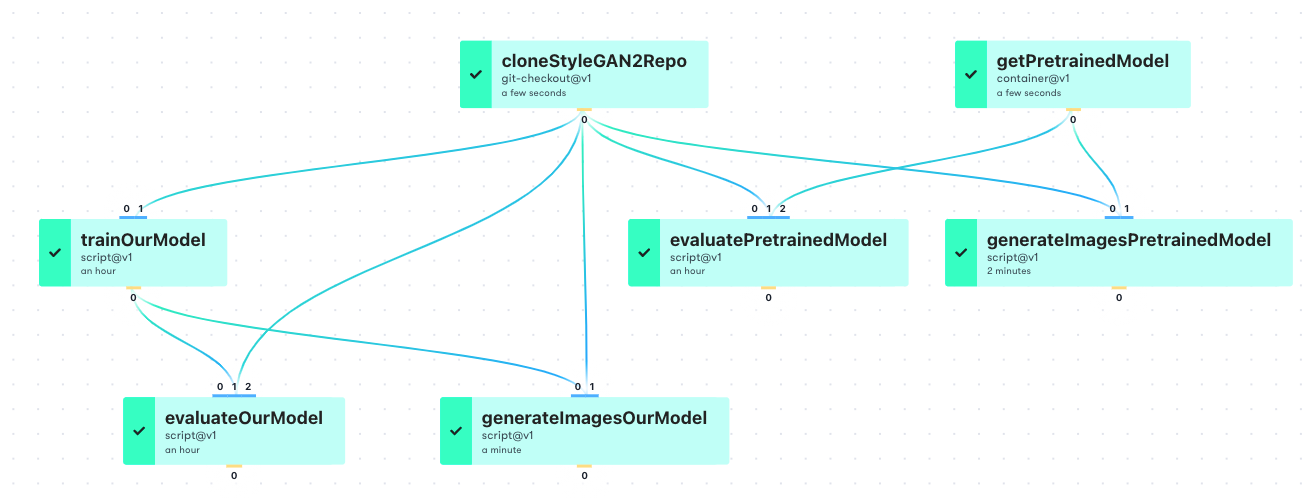
And when represented in the Workflow GUI, it looks like this
In the first diagram, we can see the versioned Gradient-managed Datasets that are fed in (gray boxes) to the instance of the pre-trained model from the StyleGAN2 repo (green boxes), and our instance of the model that we train (yellow boxes). The repo itself is in blue.
In the second diagram, we see the same structure, the names of the jobs in the Workflow, the Gradient Action used (git-checkout@v1, etc.), and the approximate runtime. The GUI Workflow diagram is guaranteed-correct, because it is automatically generated from the YAML.
Results
When the pretrained model from the StyleGAN2 repo is run, it produces new images of cats, as expected. These look like so:
And they look pretty realistic! It is not perfect, however, as can be seem from the appearance of 3 front legs on cat in the third image.
When we switch from the pretrained model to our own trained network, we see the result of the run is not so good, because we subsampled the original large set of images down to 1000 from 1.6 million, and only trained the network for a short time. This is to keep the runtime tractable for a demonstration that a user can run, while seeing the power of the Gradient platform. So the images are essentially low resolution noise:

The user could try a larger training set and running the training for longer (see below), since all of the data and information to do so is present.
Triggering a Workflow rerun
In larger projects or production settings, consistency between the components of a project (code, datasets, models, deployments, etc.) is important. Therefore, when a project is linked to a GitHub repository, we may want a change there, such as a change in model settings, to trigger a model rerun. This ensures that the model is consistent with the settings. Another example would be ensuring that the model that is deployed is the same as the one trained.
In real projects with model experiments, finished models, staging deployments, real deployments, various methods of monitoring and updating, changing data, and so on, maintaining project consistency can get complicated very quickly. Therefore, Workflows allow you to see exactly what is going on by both having it specified in their YAML code, and everything being versioned.
In the project here, the code that represents that the Workflow is to be triggered to run again is
on:
github:
branches:
only: main
which means on any change to the main branch of the repository, run the Workflow again. YAML and our Gradient Actions will allow this to be more fine-grained if you only want particular changes to trigger a rerun.
YAML files that get triggered to be rerun are placed in the .gradient/workflows directory in the repository, similar to GitHub's own Actions capability.
For our StyleGAN2 Workflows, we can easily see a rerun trigger by, for example, changing the random seeds used to generate images
python run_generator.py generate-images \
--network=/inputs/pretrainedNetwork/stylegan2-cat-config-f.pkl \
--seeds=6600-6605 \
--truncation-psi=0.5 \
--result-dir=/outputs/generatedCatsPretrained
When the updated YAML is committed to the repository, this reruns the model training and will output new images, to a new version of the output Gradient-managed Dataset. The rerun is shown in the Workflow GUI, including the event that triggered it.
A larger change can be made by, instead of just changing the seeds, in the first Workflow of the two we have, changing the number of extracted images from the small sample of 1000 mentioned above, to something larger. Then rerun the second Workflow to see if the performance of the resulting trained model is improved.
The combination of Workflow triggers, repositories linked to projects, arbitrary code in Workflow YAML, versioned datasets & models, and in future, integrated model deployments too, forms a powerful system for taking your data science from experimentation to production.
Conclusions
We have used StyleGAN2 deep learning to show:
- Data preparation using a 42 gigabyte image file and Gradient-managed Datasets
- Use of Gradient Public datasets as a data source
- Deep learning model training on an image sample
- Model evaluation using appropriate metrics
- Model inference to generate new images
- Versioned Gradient objects, including Datasets and models
- Resource control, specifying different-sized machines for different jobs
- Triggering a Workflow rerun via changing the linked GitHub repository
Next Steps
The corresponding tutorial and GitHub repository to this blog entry are available. The tutorial contains more details on how to run the Workflows for yourself.
The tutorial for this project is one of the more advanced ones, and takes longer to run, so if you want something simpler or quicker, check out our updated GUI onboarding, Getting Started with Workflows in the documentation, or another tutorial such as NLP text generation (with blog + repo).
Another longer end-to-end example, that also includes Gradient Notebooks, is our Recommender project, that also has a blog and repo.
If you're done with tutorials and want to write something new with Gradient, one possibility is to do this same project using one of StyleGAN2's other datasets, from the same LSUN location, or, say, the Flickr Faces dataset (FFHQ).
There is also an even newer version of GAN image generation, StyleGAN-ADA (TensorFlow or PyTorch versions), which might be runnable in a similar manner, and, coming soon, Alias-Free GAN.











