Object detection is an important computer vision application that enables a computer to see what is inside an image. Due to the unpredictable location of the objects in an image, intensive computations exist to process the entire image to locate the objects.
With the advent of the convolutional neural network (CNN), the time to detect an object has diminished, so that an object might be detected within a few seconds (like with the You Look Only Once (YOLO) model). But even though YOLO is fast, its accuracy isn't as impressive as its speed. A more accurate model, but one which unfortunately takes more time, is the region-based CNN (R-CNN).
This tutorial works on an extension of R-CNN, called Mask R-CNN, to direct it towards the candidate locations of objects. The resulting model is called Directed Mask R-CNN. It works pretty well when there is prior information about the objects' locations.
The outline of this tutorial is as follows:
- Overview of the R-CNN Model
- Region Proposals
- Manipulating Regions Produced by the Region Proposal Network (RPN)
- Directed Mask R-CNN
- References
Bring this project to life
Overview of the R-CNN Model
According to one of my previous Paperspace Blog tutorials titled Faster R-CNN Explained for Object Detection Tasks, the three main steps covered by object detection models are given in the next figure.
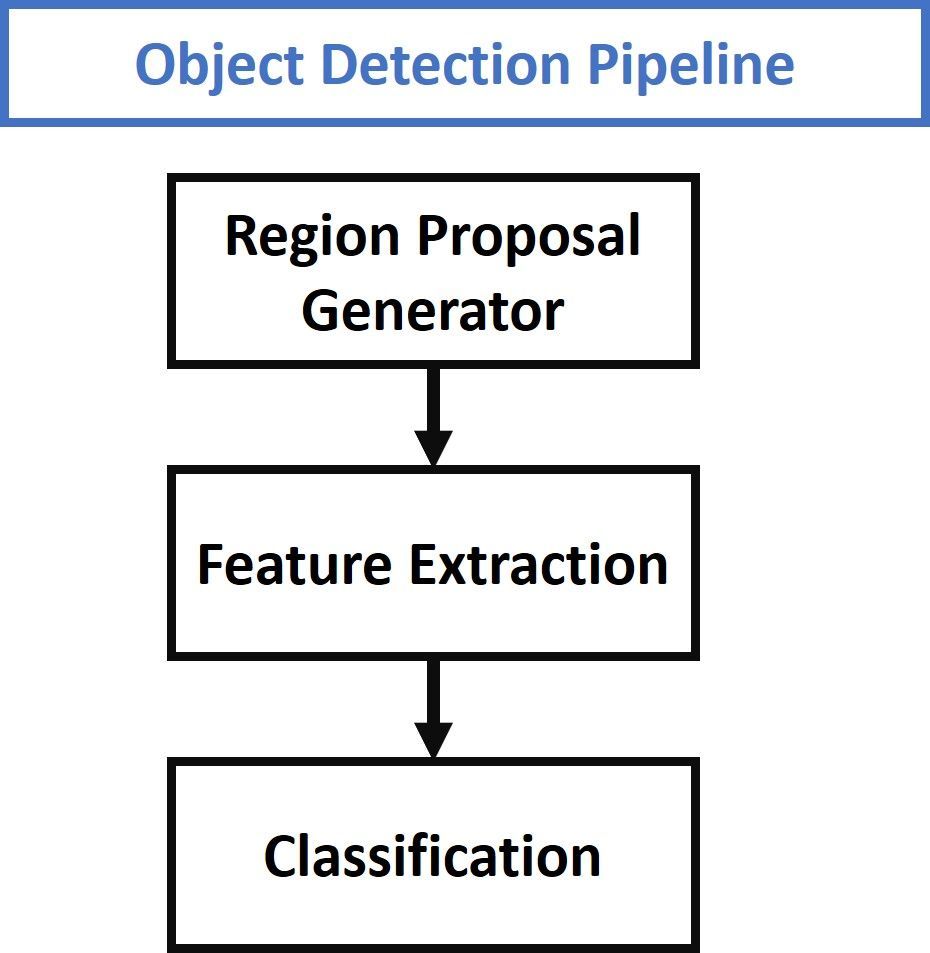
The first step is responsible for proposing candidate regions. The output of this step is simply some regions that may contain objects. In the second step, each region is processed independently to determine whether there is an object or not. This is done by extracting a set of features that are enough to describe the region. Finally, the features from each region are fed to a classifier which predicts whether there is an object or not. If there is an object, then the classifier predicts its class label.
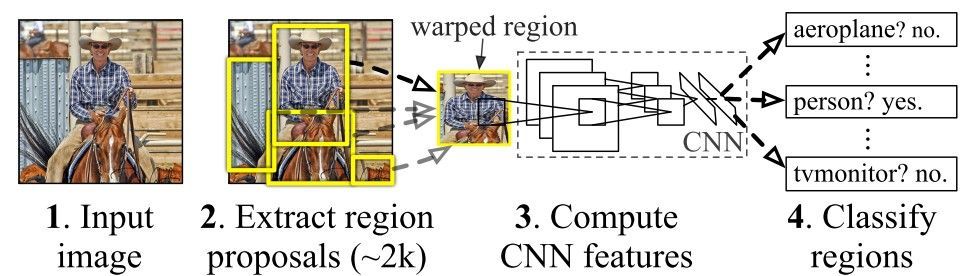
This pipeline is customized according to the model being used. The R-CNN model is described in this paper. Its flowchart is given in the image below.
The region proposals are generated using the Selective Search algorithm. This algorithm returns a large number of regions, where the objects in the image are likely to be in one of these regions.
A CNN pre-trained on the ImageNet dataset is used to extract features from each region. At the end of the R-CNN model, the region feature vector is fed to a class-specific support vector machine (SVM) to predict the object's class label.
One of the drawbacks of the R-CNN model is that the model cannot be trained end-to-end, and the 3 steps discussed previously are independent. To fix this issue, the R-CNN architecture is modified with a new extension. This updated architecture is called Faster R-CNN (introduced in this paper), where:
- The Selective Search algorithm is replaced by a Region Proposal Network (RPN).
- The RPN is connected to the pre-trained CNN, where both of them can be trained end-to-end.
- The SVM classifiers are replaced by a Softmax layer that predicts the probability of each class.
Faster R-CNN is just one big network that consists of 3 parts, where the training occurs end-to-end starting from the RPN up to the Softmax layer.
For more information, please check out this Paperspace Blog tutorial: Faster R-CNN Explained for Object Detection Tasks.
The Mask R-CNN model is an extended version of Faster R-CNN. In addition to predicting the object location, a binary mask of the object is returned. This helps to segment the object from the background.

The next section focuses on the region proposals, to explain one of the main contributions of this tutorial; namely, using static rather than dynamic region proposals.
Region Proposals
A region proposal generator (like Selective Search or RPN) generates a huge number of regions that are likely to have objects. Most of the time consumed by the object detection model is just in checking whether each region contains an object or not. It ends up with many rejected regions and just a few accepted regions that contain an object.
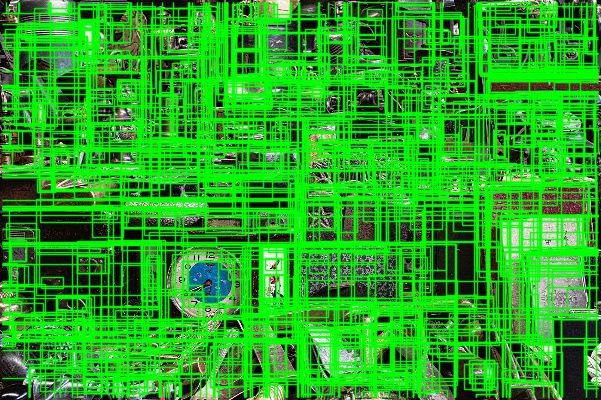
The following Python code (source) uses OpenCV to generate region proposals and draw them over an image. It resizes the image so that its height is 400 pixels. The code only shows 1,000 regions. You can change these numbers and check how the results change.
import sys
import cv2
img_path = "img.jpg"
im = cv2.imread(img_path)
newHeight = 400
newWidth = int(im.shape[1]*400/im.shape[0])
im = cv2.resize(im, (newWidth, newHeight))
ss = cv2.ximgproc.segmentation.createSelectiveSearchSegmentation()
ss.setBaseImage(im)
# High recall Selective Search
ss.switchToSelectiveSearchQuality()
rects = ss.process()
print('Total Number of Region Proposals: {}'.format(len(rects)))
numShowRects = 1000
imOut = im.copy()
for i, rect in enumerate(rects):
if (i < numShowRects):
x, y, w, h = rect
cv2.rectangle(imOut, (x, y), (x+w, y+h), (0, 255, 0), 1, cv2.LINE_AA)
else:
break
cv2.imshow("Output", imOut)
cv2.imwrite("SS_out.jpg", imOut)After feeding a sample image to this code, there were a total of 18,922 region proposals found. The next figure shows the bounding boxes of the first 1,000 regions.
In some object detection applications, you may have prior information about the candidate locations at which the objects might exist. This way, the object detection model will save time by looking only at the locations that you provide.
In the next image (source), we already have information about the locations of the horses, as these locations will not change. There are just 7 regions to look at. So, rather than asking the object detection model to waste time searching for the region proposals, it is much easier to supply these 7 regions to the model. The model will just decide whether a horse exists or not.

Unfortunately, object detection models like Mask R-CNN have no way of telling them explicitly about candidate regions. As a result, the model starts from zero and takes time to search in all the region proposals at which the objects might exist. It may or may not search in the regions you would like it to.
The Selective Search algorithm detected 20K region proposals, where only 1,000 of these regions are shown in the next figure. So, the model will consume time working on all regions, when actually only 7 regions are of interest.

Mask R-CNN Keras Example
An existing GitHub project called matterport/Mask_RCNN offers a Keras implementation of the Mask R-CNN model that uses TensorFlow 1. To work with TensorFlow 2, this project is extended in the ahmedgad/Mask-RCNN-TF2 project, which will be used in this tutorial to build both Mask R-CNN and Directed Mask R-CNN.
This section just gives an example of loading and making a prediction using the Mask R-CNN model. The code below loads the pre-trained weights of the model and then detects the objects. The model was trained on the COCO object detection dataset.
The project has a module called model in which a class named MaskRCNN exists. An instance of this class is created to load the architecture of the Mask R-CNN model. The pre-trained model weights are loaded using the load_weights() method.
After loading the model, it is ready to make predictions. An image is read and fed as input to the detect() method. This method returns 4 outputs representing the following:
- Region of Interest (ROI) for the detected objects.
- Predicted class labels.
- Class scores.
- Segmentation masks.
Finally, the display_instances() function in the visualize module is called to highlight the detected objects.
import mrcnn
import mrcnn.config
import mrcnn.model
import mrcnn.visualize
import cv2
import os
CLASS_NAMES = ['BG', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush']
class SimpleConfig(mrcnn.config.Config):
NAME = "coco_inference"
GPU_COUNT = 1
IMAGES_PER_GPU = 1
NUM_CLASSES = len(CLASS_NAMES)
model = mrcnn.model.MaskRCNN(mode="inference",
config=SimpleConfig(),
model_dir=os.getcwd())
model.load_weights(filepath="mask_rcnn_coco.h5",
by_name=True)
image = cv2.imread("test.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
r = model.detect([image])
r = r[0]
mrcnn.visualize.display_instances(image=image,
boxes=r['rois'],
masks=r['masks'],
class_ids=r['class_ids'],
class_names=CLASS_NAMES,
scores=r['scores'])The following image is fed in the previous code to show how things work.

The labeled objects are shown in the next figure. Each object has a bounding box, mask, class label, and a prediction score.

To know more about using Mask R-CNN in Keras with TensorFlow 1 and 2, please check out these resources:
- Object Detection Using Mask R-CNN with TensorFlow 1.14 and Keras
- Object Detection Using Mask R-CNN with TensorFlow 2.0 and Keras
To serve the purposes of this tutorial, which is building a directed Mask R-CNN that only investigates a set of pre-defined regions, the next section discusses how to manipulate the Region Proposal Network (RPN) to retrieve and edit the region proposals.
Manipulating Regions Produced by the Region Proposal Network (RPN)
The part of the Mask R-CNN architecture that is responsible for producing the region proposals is (as you might have guessed) the region proposal network (RPN). It uses the concept of anchors, which help to produce region proposals at different scales and aspect ratios.
In the Mask_RCNN project, there is a layer called ProposalLayer which receives the anchors, filters them, and produces a number of region proposals. The number of returned regions can be customized by the user.
By default, the outputs of the model returned after calling the detect() method are ROIs, class labels, prediction scores, and segmentation masks. This section edits the model to return the region proposals returned by the ProposalLayer, and then these regions are investigated.
In essence, the MaskRCNN class is edited so that its last layer becomes the ProposalLayer. Here is the reduced code of the MaskRCNN class that returns the region proposals.
class MaskRCNN():
def __init__(self, mode, config, model_dir):
assert mode in ['training', 'inference']
self.mode = mode
self.config = config
self.model_dir = model_dir
self.set_log_dir()
self.keras_model = self.build(mode=mode, config=config)
def build(self, mode, config):
assert mode in ['training', 'inference']
h, w = config.IMAGE_SHAPE[:2]
if h / 2**6 != int(h / 2**6) or w / 2**6 != int(w / 2**6):
raise Exception("Image size must be dividable by 2 at least 6 times "
"to avoid fractions when downscaling and upscaling."
"For example, use 256, 320, 384, 448, 512, ... etc. ")
input_image = KL.Input(
shape=[None, None, config.IMAGE_SHAPE[2]], name="input_image")
input_image_meta = KL.Input(shape=[config.IMAGE_META_SIZE],
name="input_image_meta")
input_anchors = KL.Input(shape=[None, 4], name="input_anchors")
if callable(config.BACKBONE):
_, C2, C3, C4, C5 = config.BACKBONE(input_image, stage5=True,
train_bn=config.TRAIN_BN)
else:
_, C2, C3, C4, C5 = resnet_graph(input_image, config.BACKBONE,
stage5=True, train_bn=config.TRAIN_BN)
P5 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c5p5')(C5)
P4 = KL.Add(name="fpn_p4add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p5upsampled")(P5),
KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c4p4')(C4)])
P3 = KL.Add(name="fpn_p3add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p4upsampled")(P4),
KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c3p3')(C3)])
P2 = KL.Add(name="fpn_p2add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p3upsampled")(P3),
KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c2p2')(C2)])
P2 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p2")(P2)
P3 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p3")(P3)
P4 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p4")(P4)
P5 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p5")(P5)
P6 = KL.MaxPooling2D(pool_size=(1, 1), strides=2, name="fpn_p6")(P5)
rpn_feature_maps = [P2, P3, P4, P5, P6]
anchors = input_anchors
rpn = build_rpn_model(config.RPN_ANCHOR_STRIDE,
len(config.RPN_ANCHOR_RATIOS), config.TOP_DOWN_PYRAMID_SIZE)
layer_outputs = []
for p in rpn_feature_maps:
layer_outputs.append(rpn([p]))
output_names = ["rpn_class_logits", "rpn_class", "rpn_bbox"]
outputs = list(zip(*layer_outputs))
outputs = [KL.Concatenate(axis=1, name=n)(list(o))
for o, n in zip(outputs, output_names)]
rpn_class_logits, rpn_class, rpn_bbox = outputs
proposal_count = config.POST_NMS_ROIS_INFERENCE
rpn_rois = ProposalLayer(
proposal_count=proposal_count,
nms_threshold=config.RPN_NMS_THRESHOLD,
name="ROI",
config=config)([rpn_class, rpn_bbox, anchors])
model = KM.Model([input_image, input_image_meta, input_anchors],
rpn_rois,
name='mask_rcnn')
if config.GPU_COUNT > 1:
from mrcnn.parallel_model import ParallelModel
model = ParallelModel(model, config.GPU_COUNT)
return modelBecause the detect() method expects that the model returns information about the detected objects, like ROIs, this method must be edited since the model now returns the region proposals. The new code for this method is given below.
def detect(self, images, verbose=0):
assert self.mode == "inference", "Create model in inference mode."
assert len(images) == self.config.BATCH_SIZE, "len(images) must be equal to BATCH_SIZE"
if verbose:
log("Processing {} images".format(len(images)))
for image in images:
log("image", image)
molded_images, image_metas, windows = self.mold_inputs(images)
image_shape = molded_images[0].shape
for g in molded_images[1:]:
assert g.shape == image_shape, "After resizing, all images must have the same size. Check IMAGE_RESIZE_MODE and image sizes."
anchors = self.get_anchors(image_shape)
anchors = np.broadcast_to(anchors, (self.config.BATCH_SIZE,) + anchors.shape)
if verbose:
log("molded_images", molded_images)
log("image_metas", image_metas)
log("anchors", anchors)
rois = self.keras_model.predict([molded_images, image_metas, anchors], verbose=0)
return roisFor the complete code of the new model.py file that applies the changes in both the ProposalLayer layer and detect() method, go here.
The next code block gives an example that uses the new MaskRCNN class to return the region proposals and draw them over the image. You can find script here.
Compared to the previous example, the module name is changed from mrcnn to mrcnn_directed.
import mrcnn_directed
import mrcnn_directed.config
import mrcnn_directed.model
import mrcnn_directed.visualize
import cv2
import os
CLASS_NAMES = ['BG', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush']
class SimpleConfig(mrcnn_directed.config.Config):
NAME = "coco_inference"
GPU_COUNT = 1
IMAGES_PER_GPU = 1
NUM_CLASSES = len(CLASS_NAMES)
model = mrcnn_directed.model.MaskRCNN(mode="inference",
config=SimpleConfig(),
model_dir=os.getcwd())
model.load_weights(filepath="mask_rcnn_coco.h5",
by_name=True)
image = cv2.imread("test.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
r = model.detect([image], verbose=0)
r = r[0]
r2 = r.copy()
r2[:, 0] = r2[:, 0] * image.shape[0]
r2[:, 2] = r2[:, 2] * image.shape[0]
r2[:, 1] = r2[:, 1] * image.shape[1]
r2[:, 3] = r2[:, 3] * image.shape[1]
mrcnn_directed.visualize.display_instances(image=image,
boxes=r2)After the code runs, the input image is displayed with the bounding boxes of the region proposals. The number of region proposals is 1,000, and can be changed by setting the POST_NMS_ROIS_INFERENCE attribute in the SimpleConfig class.

Here are the first 4 region proposals returned by the model:
r[0]
Out[8]: array([0.49552074, 0.0, 0.53763664, 0.09105143], dtype=float32)
r[1]
Out[9]: array([0.5294977, 0.39210293, 0.63644147, 0.44242138], dtype=float32)
r[2]
Out[10]: array([0.36204672, 0.40500385, 0.6706183 , 0.54514766], dtype=float32)
r[3]
Out[11]: array([0.48107424, 0.08110721, 0.51513755, 0.17086479], dtype=float32)The coordinates of the regions are scaled from 0.0 to 1.0. To return them to the original scale, the region coordinates are multiplied by the image width and height. Here are the new values:
r2[0]
array([144.19653, 0.0, 156.45226, 40.517887], dtype=float32)
r2[1]
Out[5]: array([154.08383, 174.48581, 185.20447, 196.87752], dtype=float32)
r2[2]
Out[6]: array([105.3556, 180.22672, 195.14992, 242.59071], dtype=float32)
r2[3]
Out[7]: array([139.9926, 36.09271, 149.90503, 76.03483], dtype=float32)Note how there is a large number of regions to be processed. If this number is reduced, then the model will be much faster. The next section discusses directing the Mask R-CNN model, where the user tells the model about the regions in which to search for objects.
Directed Mask R-CNN
Compared to the Mask R-CNN model that uses the RPN to search for the region proposals, Directed Mask R-CNN only searches within some user-defined regions. Thus, Directed Mask R-CNN is suitable for applications where objects can be located in some predefined set of regions. The code for the Directed Mask R-CNN is available here.
We can start with an experiment, where the model is forced to keep only the first 4 region proposals. The idea here is to multiply the tensor that holds the region proposals by a mask which is set to 1.0 for the coordinates of the first 4 region proposals, and 0.0 otherwise.
At the end of the ProposalLayer and exactly before the return proposals line, the following 3 lines can be used.
zeros = np.zeros(shape=(1, self.config.POST_NMS_ROIS_INFERENCE, 4), dtype=np.float32)
zeros[0, :4, :] = 1.0
proposals = KL.Multiply()([proposals, tf.convert_to_tensor(zeros)])Here is the new code for the ProposalLayer that only uses 4 regions.
class ProposalLayer(KE.Layer):
def __init__(self, proposal_count, nms_threshold, config=None, **kwargs):
super(ProposalLayer, self).__init__(**kwargs)
self.config = config
self.proposal_count = proposal_count
self.nms_threshold = nms_threshold
def call(self, inputs):
scores = inputs[0][:, :, 1]
deltas = inputs[1]
deltas = deltas * np.reshape(self.config.RPN_BBOX_STD_DEV, [1, 1, 4])
anchors = inputs[2]
pre_nms_limit = tf.minimum(self.config.PRE_NMS_LIMIT, tf.shape(anchors)[1])
ix = tf.nn.top_k(scores, pre_nms_limit, sorted=True,
name="top_anchors").indices
scores = utils.batch_slice([scores, ix], lambda x, y: tf.gather(x, y),
self.config.IMAGES_PER_GPU)
deltas = utils.batch_slice([deltas, ix], lambda x, y: tf.gather(x, y),
self.config.IMAGES_PER_GPU)
pre_nms_anchors = utils.batch_slice([anchors, ix], lambda a, x: tf.gather(a, x),
self.config.IMAGES_PER_GPU,
names=["pre_nms_anchors"])
boxes = utils.batch_slice([pre_nms_anchors, deltas],
lambda x, y: apply_box_deltas_graph(x, y),
self.config.IMAGES_PER_GPU,
names=["refined_anchors"])
window = np.array([0, 0, 1, 1], dtype=np.float32)
boxes = utils.batch_slice(boxes,
lambda x: clip_boxes_graph(x, window),
self.config.IMAGES_PER_GPU,
names=["refined_anchors_clipped"])
def nms(boxes, scores):
indices = tf.image.non_max_suppression(
boxes, scores, self.proposal_count,
self.nms_threshold, name="rpn_non_max_suppression")
proposals = tf.gather(boxes, indices)
# Pad if needed
padding = tf.maximum(self.proposal_count - tf.shape(proposals)[0], 0)
proposals = tf.pad(proposals, [(0, padding), (0, 0)])
return proposals
proposals = utils.batch_slice([boxes, scores], nms,
self.config.IMAGES_PER_GPU)
zeros = np.zeros(shape=(1, self.config.POST_NMS_ROIS_INFERENCE, 4), dtype=np.float32)
zeros[0, :4, :] = 1.0
proposals = KL.Multiply()([proposals, tf.convert_to_tensor(zeros)])
return proposals
def compute_output_shape(self, input_shape):
return (None, self.proposal_count, 4)The next figure shows the 4 regions.

It is also possible to supply your own custom coordinates to the model by hardcoding their values, but they must be scaled between 0.0 and 1.0.
The following code assigns the static coordinate values of 5 region proposals.
zeros = np.zeros(shape=(1, self.config.POST_NMS_ROIS_INFERENCE, 4), dtype=np.float32)
zeros[0, 0, :] = [0.0, 0.0 , 0.2, 0.3]
zeros[0, 1, :] = [0.42, 0.02, 0.8, 0.267]
zeros[0, 2, :] = [0.12, 0.52, 0.55, 0.84]
zeros[0, 3, :] = [0.61, 0.71, 0.87, 0.21]
zeros[0, 4, :] = [0.074, 0.83, 0.212, 0.94]
proposals = tf.convert_to_tensor(zeros)The code of the ProposalLayer can now be reduced to the following.
class ProposalLayer(KE.Layer):
def __init__(self, proposal_count, nms_threshold, config=None, **kwargs):
super(ProposalLayer, self).__init__(**kwargs)
self.config = config
def call(self, inputs):
zeros = np.zeros(shape=(1, self.config.POST_NMS_ROIS_INFERENCE, 4), dtype=np.float32)
zeros[0, 0, :] = [0.0, 0.0 , 0.2, 0.3]
zeros[0, 1, :] = [0.42, 0.02, 0.8, 0.267]
zeros[0, 2, :] = [0.12, 0.52, 0.55, 0.84]
zeros[0, 3, :] = [0.61, 0.71, 0.87, 0.21]
zeros[0, 4, :] = [0.074, 0.83, 0.212, 0.94]
proposals = tf.convert_to_tensor(zeros)
return proposalsThe next figure shows the bounding boxes of the 5 regions specified by the user. This way, the user forces the model to search for the objects within the pre-defined regions.
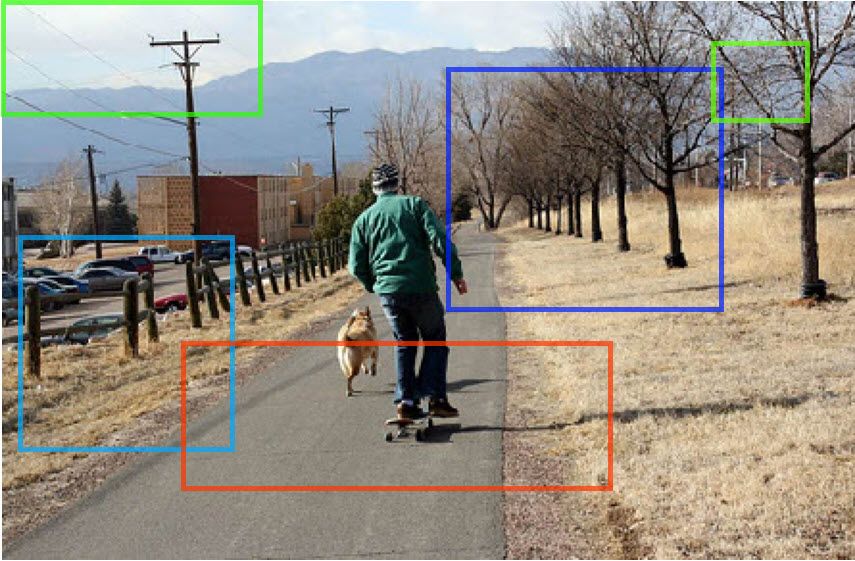
Note that the default value of the POST_NMS_ROIS_INFERENCE attribute in the Config class is 1,000, which means the previous code searches for objects in 1,000 regions. In case you would like to search for objects in a specific number of regions, you may set the POST_NMS_ROIS_INFERENCE attribute in the Config class, as in the following code. This forces the model to only work on 5 regions.
class SimpleConfig(mrcnn_directed.config.Config):
NAME = "coco_inference"
GPU_COUNT = 1
IMAGES_PER_GPU = 1
NUM_CLASSES = len(CLASS_NAMES)
POST_NMS_ROIS_INFERENCE = 5The next section discusses the changes made in the Python implementation of Directed Mask R-CNN compared to Mask R-CNN.
Changes in Directed Mask R-CNN
Here you can find all the files that implement Directed Mask R-CNN. The most important file is model.py.
Compared to the mrcnn directory, there are 4 changes made:
- The
config.Configclass. - The
ProposalLayerclass. - The
MaskRCNNclass. - The
visualize.display_instances()method.
First Change
The first change is that the mrcnn_directed.config.Config class has a new attribute called REGION_PROPOSALS. The default value for this attribute is None, which means the region proposals will be generated by the RPN. The REGION_PROPOSALS attribute does not exist in the mrcnn.config.Config class.
The user may set the value of this attribute to pass some pre-defined region proposals where the model will look. This is how the user directs the Mask R-CNN model to look at some specific regions.
To use the REGION_PROPOSALS attribute, first create a NumPy array of shape (1, POST_NMS_ROIS_INFERENCE, 4), where POST_NMS_ROIS_INFERENCE is the number of region proposals.
In the next code block, the POST_NMS_ROIS_INFERENCE attribute is set to 5 to just use 5 region proposals. A new NumPy array of zeros is created and then the coordinates of the region proposals are specified.
POST_NMS_ROIS_INFERENCE = 5
REGION_PROPOSALS = numpy.zeros(shape=(1, POST_NMS_ROIS_INFERENCE, 4), dtype=numpy.float32)
REGION_PROPOSALS[0, 0, :] = [0.49552074, 0. , 0.53763664, 0.09105143]
REGION_PROPOSALS[0, 1, :] = [0.5294977 , 0.39210293, 0.63644147, 0.44242138]
REGION_PROPOSALS[0, 2, :] = [0.36204672, 0.40500385, 0.6706183 , 0.54514766]
REGION_PROPOSALS[0, 3, :] = [0.48107424, 0.08110721, 0.51513755, 0.17086479]
REGION_PROPOSALS[0, 4, :] = [0.45803332, 0.15717855, 0.4798005 , 0.20352092]After that, create an instance of the mrcnn_directed.config.Config class with the 2 attributes POST_NMS_ROIS_INFERENCE and REGION_PROPOSALS set to the 2 attributes created in the previous code. This way, the model is forced to use the region proposals defined above.
Note that if REGION_PROPOSALS is set to None, then the region proposals will be generated by the RPN. This is the end of the first change.
class SimpleConfig(mrcnn_directed.config.Config):
NAME = "coco_inference"
GPU_COUNT = 1
IMAGES_PER_GPU = 1
NUM_CLASSES = len(CLASS_NAMES)
POST_NMS_ROIS_INFERENCE = POST_NMS_ROIS_INFERENCE
# If REGION_PROPOSALS is None, then the region proposals are produced by the RPN.
# Otherwise, the user-defined region proposals are used.
REGION_PROPOSALS = REGION_PROPOSALS
# REGION_PROPOSALS = NoneSecond Change
The second change is that in addition to the mrcnn/ProposalLayer class in the mrcnn/model.py script, the mrcnn_directed/model.py script has a new class named ProposalLayerDirected.
The ProposalLayerDirected class works on the user-defined region proposals passed in the REGION_PROPOSALS attribute. The ProposalLayer class works as usual on the region proposals generated by the RPN.
Based on whether the REGION_PROPOSALS attribute is set to None or not, which layer to use is determined according to the next code. If the attribute is None, then the ProposalLayer class is used. Otherwise, the ProposalLayerDirected class is used.
if type(config.REGION_PROPOSALS) != type(None):
proposal_count = config.POST_NMS_ROIS_TRAINING if mode == "training"\
else config.POST_NMS_ROIS_INFERENCE
rpn_rois = ProposalLayerDirected(proposal_count=proposal_count,
nms_threshold=config.RPN_NMS_THRESHOLD,
name="ROI",
config=config)([rpn_class, rpn_bbox, anchors])
else:
proposal_count = config.POST_NMS_ROIS_TRAINING if mode == "training"\
else config.POST_NMS_ROIS_INFERENCE
rpn_rois = ProposalLayer(proposal_count=proposal_count,
nms_threshold=config.RPN_NMS_THRESHOLD,
name="ROI",
config=config)([rpn_class, rpn_bbox, anchors])Third Change
The third change is that the mrcnn/MaskRCNN class in the mrcnn/model.py script is replaced with 2 classes in the mrcnn_directed/model.py script:
MaskRCNNDirectedRPN: This class is used for just returning the outputs of the region proposal layer. Based on whether theREGION_PROPOSALSattribute isNoneor not, theMaskRCNNDirectedRPNclass can either return the region proposals generated by the RPN or the user-defined region proposals (for the purpose of making sure things are working well).MaskRCNNDirected: This class is used for detecting the objects in the returned region proposals. Based on whether theREGION_PROPOSALSattribute isNoneor not, theMaskRCNNDirectedclass can either detect the objects in the region proposals generated by the RPN or the user-defined region proposals.
Both the 2 classes MaskRCNNDirectedRPN and MaskRCNNDirected are instantiated in the same way, according to the following code:
model = mrcnn_directed.model.MaskRCNNDirectedRPN(mode="inference",
config=SimpleConfig(),
model_dir=os.getcwd())
model = mrcnn_directed.model.MaskRCNNDirected(mode="inference",
config=SimpleConfig(),
model_dir=os.getcwd())What actually matters about the 2 classes is the output(s) of the detect() method. For the MaskRCNNDirectedRPN class, the detect() method returns an array of shape (1, POST_NMS_ROIS_INFERENCE, 4).
For the MaskRCNNDirected class, the detect() method returns 4 arrays of the following shapes:
(POST_NMS_ROIS_INFERENCE, 4)(ImgHeight, ImgWidth, POST_NMS_ROIS_INFERENCE)(POST_NMS_ROIS_INFERENCE)(POST_NMS_ROIS_INFERENCE)
Where ImgHeight and ImgWidth are the height and width of the input image, respectively.
Fourth Change
The fourth change is that in addition to the visualize.display_instances() method in the visualize.py script, there is an additional method called display_instances_RPN().
The display_instances() method annotates the detected objects exactly like we did before, by showing the bounding box, class label, prediction score, and segmentation mask over each object. Here is an example:
r = model.detect([image])
r = r[0]
mrcnn_directed.visualize.display_instances(image=image,
boxes=r['rois'],
masks=r['masks'],
class_ids=r['class_ids'],
class_names=CLASS_NAMES,
scores=r['scores'])The display_instances_RPN() method just shows the bounding box over each region proposal. It has less arguments compared to the display_instances() method. Here is an example:
r = model.detect([image])
r = r[0]
r2 = r.copy()
mrcnn_directed.visualize.display_instances_RPN(image=image,
boxes=r2)Examples Using Directed Mask R-CNN
The Directed Mask R-CNN model has 2 main uses:
- Working on the region proposals only using the
MaskRCNNDirectedRPNclass. - Using the region proposals to annotate the detected objects using the
MaskRCNNDirectedclass.
The next code block gives an example of how to work on the user-defined region proposals where the MaskRCNNDirectedRPN class is used. It is also possible to set the REGION_PROPOSALS attribute in the SimpleConfig class to None to force the model to generate the region proposals using the RPN.
import mrcnn_directed
import mrcnn_directed.config
import mrcnn_directed.model
import mrcnn_directed.visualize
import cv2
import os
import numpy
CLASS_NAMES = ['BG', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush']
POST_NMS_ROIS_INFERENCE = 5
REGION_PROPOSALS = numpy.zeros(shape=(1, POST_NMS_ROIS_INFERENCE, 4), dtype=numpy.float32)
REGION_PROPOSALS[0, 0, :] = [0.0, 0.0 , 0.2, 0.3]
REGION_PROPOSALS[0, 1, :] = [0.42, 0.02, 0.8, 0.267]
REGION_PROPOSALS[0, 2, :] = [0.12, 0.52, 0.55, 0.84]
REGION_PROPOSALS[0, 3, :] = [0.61, 0.71, 0.87, 0.21]
REGION_PROPOSALS[0, 4, :] = [0.074, 0.83, 0.212, 0.94]
class SimpleConfig(mrcnn_directed.config.Config):
NAME = "coco_inference"
GPU_COUNT = 1
IMAGES_PER_GPU = 1
NUM_CLASSES = len(CLASS_NAMES)
POST_NMS_ROIS_INFERENCE = POST_NMS_ROIS_INFERENCE
# If REGION_PROPOSALS is None, then the region proposals are produced by the RPN.
# Otherwise, the user-defined region proposals are used.
REGION_PROPOSALS = REGION_PROPOSALS
# REGION_PROPOSALS = None
model = mrcnn_directed.model.MaskRCNNDirectedRPN(mode="inference",
config=SimpleConfig(),
model_dir=os.getcwd())
model.load_weights(filepath="mask_rcnn_coco.h5",
by_name=True)
image = cv2.imread("test.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
r = model.detect([image], verbose=0)
r = r[0]
r2 = r.copy()
r2[:, 0] = r2[:, 0] * image.shape[0]
r2[:, 2] = r2[:, 2] * image.shape[0]
r2[:, 1] = r2[:, 1] * image.shape[1]
r2[:, 3] = r2[:, 3] * image.shape[1]
mrcnn_directed.visualize.display_instances_RPN(image=image,
boxes=r2)The next code block gives an example that, in addition to working on the region proposals, also annotates the detected objects. Note that the MaskRCNNDirected class is used. This code is available here.
It is also possible to set the REGION_PROPOSALS attribute in the SimpleConfig class to None to force the model to generate the region proposals using the RPN.
import mrcnn_directed
import mrcnn_directed.config
import mrcnn_directed.model
import mrcnn_directed.visualize
import cv2
import os
import numpy
CLASS_NAMES = ['BG', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush']
POST_NMS_ROIS_INFERENCE = 5
REGION_PROPOSALS = numpy.zeros(shape=(1, POST_NMS_ROIS_INFERENCE, 4), dtype=numpy.float32)
REGION_PROPOSALS[0, 0, :] = [0.49552074, 0. , 0.53763664, 0.09105143]
REGION_PROPOSALS[0, 1, :] = [0.5294977 , 0.39210293, 0.63644147, 0.44242138]
REGION_PROPOSALS[0, 2, :] = [0.36204672, 0.40500385, 0.6706183 , 0.54514766]
REGION_PROPOSALS[0, 3, :] = [0.48107424, 0.08110721, 0.51513755, 0.17086479]
REGION_PROPOSALS[0, 4, :] = [0.45803332, 0.15717855, 0.4798005 , 0.20352092]
class SimpleConfig(mrcnn_directed.config.Config):
NAME = "coco_inference"
GPU_COUNT = 1
IMAGES_PER_GPU = 1
NUM_CLASSES = len(CLASS_NAMES)
POST_NMS_ROIS_INFERENCE = POST_NMS_ROIS_INFERENCE
# If REGION_PROPOSALS is None, then the region proposals are produced by the RPN.
# Otherwise, the user-defined region proposals are used.
REGION_PROPOSALS = REGION_PROPOSALS
# REGION_PROPOSALS = None
model = mrcnn_directed.model.MaskRCNNDirected(mode="inference",
config=SimpleConfig(),
model_dir=os.getcwd())
model.load_weights(filepath="mask_rcnn_coco.h5",
by_name=True)
image = cv2.imread("test.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
r = model.detect([image])
r = r[0]
mrcnn_directed.visualize.display_instances(image=image,
boxes=r['rois'],
masks=r['masks'],
class_ids=r['class_ids'],
class_names=CLASS_NAMES,
scores=r['scores'])
print(r['rois'].shape)
print(r['masks'].shape)
print(r['class_ids'].shape)
print(r['scores'].shape)Conclusion
In this tutorial we saw how to edit Mask R-CNN to build a directed network, where the user specifies some regions where the model should look for objects. Reducing the number of region proposals that the model processes reduces the computational time of the model. This work could be applied only when the objects are always visible in some predefined locations, like vehicle stalls.
References
- Faster R-CNN Explained for Object Detection Tasks, Paperspsce Blog
- Object Detection Using Mask R-CNN with TensorFlow 1.14 and Keras
- Object Detection Using Mask R-CNN with TensorFlow 2.0 and Keras
- https://github.com/ahmedfgad/Mask-RCNN-TF2
- https://github.com/ahmedfgad/Mask-RCNN-TF2/tree/master/mrcnn_directed
- Girshick, Ross, et al. "Rich feature hierarchies for accurate object detection and semantic segmentation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2014
- Ren, Shaoqing, et al. "Faster r-cnn: Towards real-time object detection with region proposal networks." IEEE transactions on pattern analysis and machine intelligence 39.6 (2016): 1137-1149
- He, Kaiming, et al. "Mask r-cnn." Proceedings of the IEEE international conference on computer vision. 2017