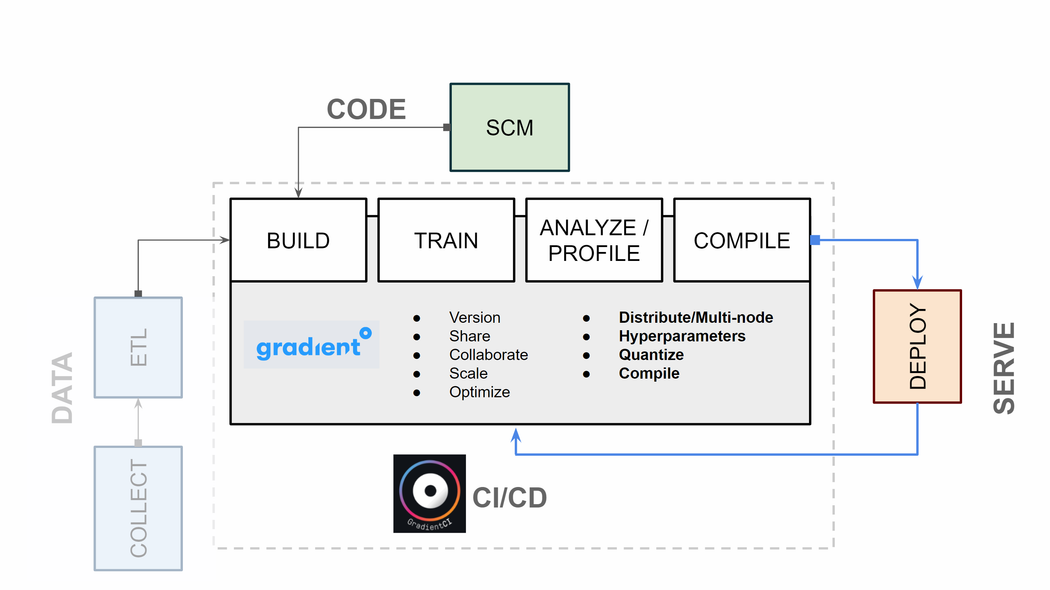

Introduction
Paperspace Gradient and Amazon SageMaker are two of the most popular end-to-end machine learning platforms.
End-to-end machine learning platform means a toolset that supports machine learning model development from the research or prototype stage to deployment at scale.
Platform means that there is some level of automation that makes it easier to perform machine learning tasks.
Similarities Between Paperspace Gradient and Amazon SageMaker
Paperspace Gradient and Amazon SageMaker make it easier to take machine learning models from research to production.
Whereas before it was necessary to hack together tools and services to productionize a machine learning model, it is now possible to write, manage, and orchestrate models on a single platform with your choice of frameworks and packages.
The result is a model development process that is more robust, reliable, predictable, reproducible, and useful over time for most applications than a hacked-together workflow.
The advantages of using a fully managed service such as Gradient or SageMaker are numerous:
- Collaboration: machine learning platforms include a cloud IDE or notebook environment that makes it easy to share and deploy code
- Visibility: models change over time and visibility into testing and training data and results is the only way to ensure models consistently improve
- Versioning: versioning is the key to improving fault isolation and model efficiency
- Reproducibility: working with a team requires the ability to recreate experiments
Both Gradient and SageMaker have features that speed-up the development cycle for a machine learning model.
The disadvantages of not using a managed service for developing machine learning models also include several other factors:
- Hacked-together tools are difficult to scale, especially when working with a team
- Manual processes make it easier to introduce errors
- Costs can get out of control, since each piece of a hacked-together workflow can have associated costs
- Compatibility becomes a complex problem
- Models improve less over time, which represents a logarithmic loss of business efficiency
As your machine learning deployments grow in size and complexity, an ML platform will become more useful to your team. The following document presents some of the important factors to consider when selecting an ML platform.
Differences Between Paperspace Gradient and Amazon SageMaker
The primary difference between Paperspace Gradient and Amazon SageMaker is that Gradient is an easy-to-use orchestration tool to write and deploy machine learning models at scale, while SageMaker is a series of confusing industrial products from data labeling to a pre-built algorithm marketplace.
The differences are explained as follows:
Cognitive Overhead and Design Philosophy
Effortless ML means writing machine learning code, not troubleshooting infrastructure tooling.
With Amazon SageMaker, you will need to have strong DevOps knowledge. You will need to manage user permissions with IAM. You will need to be able to perform application-scale tooling to set up an ML pipeline.
With Paperspace Gradient, there is an intuitive GUI and a GradientCI command line tool. Most tooling is already set up out of the box. Compute allocation, package dependencies, and model versioning are also available out of the box.
If you already have substantial AWS and/or SageMaker expertise, you will appreciate that Gradient makes many of the repetitive orchestration tasks far easier.
Philosophically, Gradient gives you access to the entire infrastructure stack. Information is surfaced regarding the entire deployment pipeline – from, for example, the job runner down to the application layer, and down to the underlying compute hardware.
Incentive Alignment
Paperspace Gradient is a multi-cloud solution. The motivation behind Gradient is to provide every machine learning team with the best tools – regardless of where they live.
Many AWS applications – including those within SageMaker – are designed to encourage the end user to adopt other AWS applications or managed services. SageMaker for example already has a managed service for pre-built algorithms, for deploying to the edge, and for adding human review to model predictions.
If you are fully organized around AWS, you probably know that AWS Managed Services can be a black hole – and using a single-cloud ML platform can and will push you to that cloud's expensive managed services.
Gradient is geared to your productivity. It will not limit you through architectural lock-in, it will not push you to adopt managed services, and it will not forcibly curtail your ML capability through opinionated platform-specific design.
CI/CD Approach and Feedback Loops
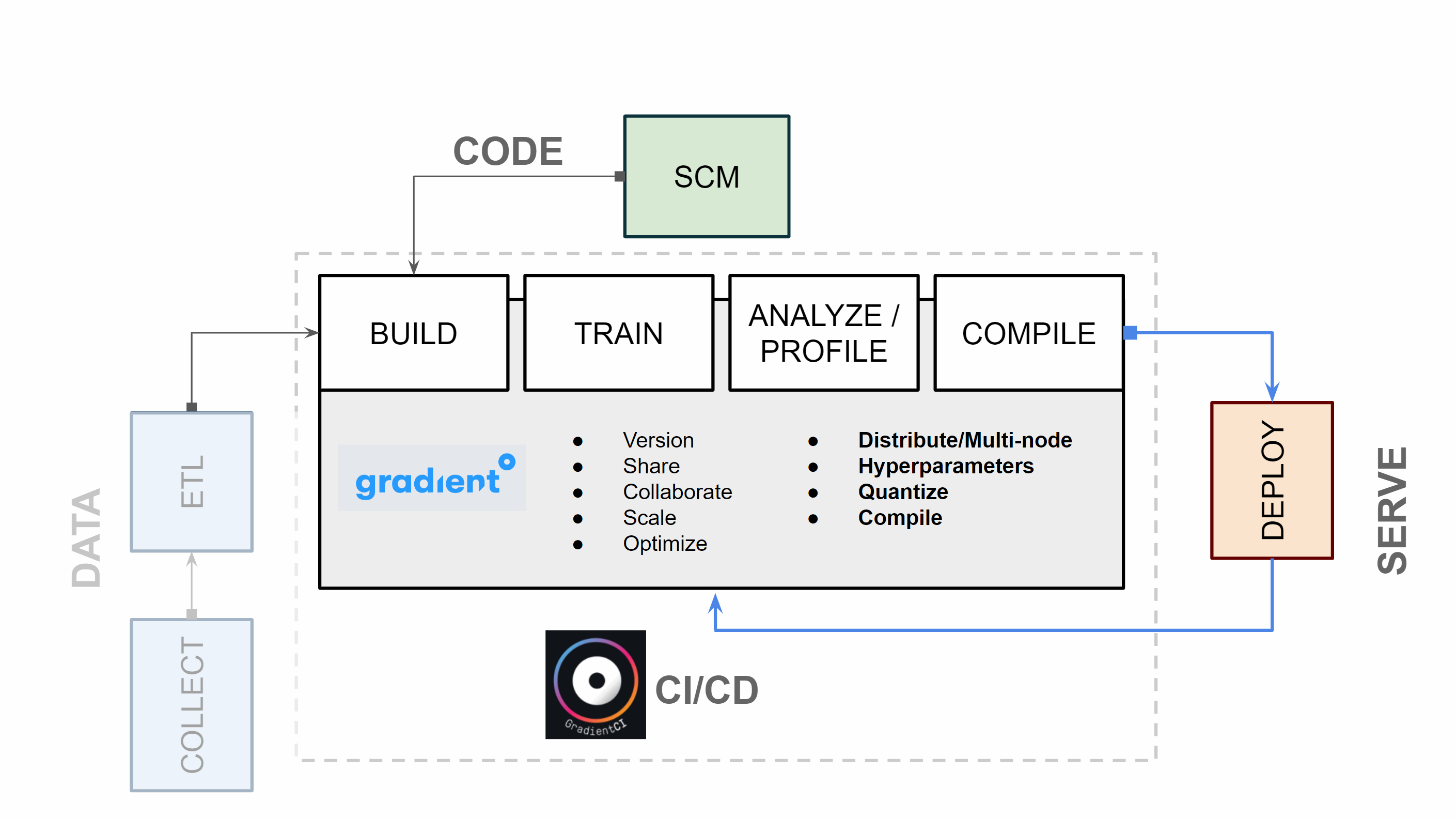
Many high-functioning software teams use some version of CI/CD in their workflow. The advantages are multiple:
- Shorter development cycle
- Greater team visibility and collaboration
- Smaller code changes improve failure identification
- Greater code improvement velocity
Machine learning processes benefit for the same reasons. Model development and deployment cycles are more efficient using a CI/CD tool like Paperspace Gradient.
Amazon SageMaker also has tools for tuning (e.g. one-click hyperparameter optimization), but you will find these same capabilities in Gradient as standard features.
Infrastructure Management
AWS applications are notoriously difficult to manage but very powerful at scale. Many AWS services are so complex that they have standalone certification programs!
To deploy machine learning models at scale, Amazon SageMaker requires understanding of permissions (e.g. IAM), allocation of compute resources (e.g. EC2), and deep knowledge of data flow through AWS properties.
Tooling infrastructure on Gradient is far simpler. Gradient features an integrated job runner that automatically provisions compute resources in the most cost effective manner available.
Speed of Deployment
With Paperspace Gradient, you can go from a Jupyter notebook to production in 5 minutes or less.
Amazon SageMaker, which is known for infrastructure performance, requires more effort to get to insight – the first time and every time. Paperspace is more intuitive, especially for data scientists who are not accustomed to orchestrating compute loads.
Both Gradient and SageMaker offer "1-click deploy" but in Gradient this includes provisioning of compute resources (using the serverless job runner) while in SageMaker provisioning remains a tooling challenge.
In other words, although SageMaker can be fine-tuned to reach maximum performance, infrastructure performance is meaningless if it takes forever to deploy a model.
Cost (Pay for What You Use)
Paperspace Gradient and Amazon SageMaker both have some form of per-instance billing.
SageMaker refers to its service as Managed Spot Training, which uses EC2 Spot instances. These instances are pulled form a pool of shared instances that are available at a given time on the AWS cloud given real-time supply and demand. AWS then fills the compute requirements of your ML job from this bucket of available resources and performs your compute actions.
The problem with spot instances is that your job can be preempted by another customer, substantially lengthening the training time for a given experiment. And if you do use EC2 machine learning instances, the cost is very difficult to control.
Gradient, on the other hand, makes it easy to simply pay for exactly the instance you need – whether it's on-prem, on AWS, or on GCP. This on-demand billing is referred to as Serverless ML. This means that there is an integrated job runner that automatically provisions compute resources for a given job. You are always only billed for the resources you actually use. This prevents a great deal of cost overruns due to user error or bad system design.
Topology
Many machine learning and deep learning applications require training models for deployment at the edge or integrated with an IoT framework. Models are often optimized for inference. Pruning or quantization is performed. The model shrinks to fit the deployment criteria.
Since Gradient is a Kubernetes application, it is easy to distribute training to processing hubs, which can be spun up and down easily. Clusters can be set up in a way that suits business needs, and there is a single pane of glass to administer multi-cloud compute workloads.
SageMaker, by comparison, limits you to a particular data center region by default and makes it difficult to distribute.
Vendor Lock-in and Extensibility
Amazon SageMaker runs exclusively on AWS. This is not a problem if you run your business on AWS or have deep familiarity with the AWS ecosystem. However, an additional problem arises not as a function of vendor lock-in, but as a function of extensibility.
Paperspace Gradient is a software layer installed on top of any cloud or on-prem infrastructure. The application itself is a Kubernetes app. Gradient may be orchestrated across multiple cloud environments, which means that models may be administered under a single pane of glass.
With SageMaker, the machine learning workflow is prisoner to the AWS ecosystem. If new products or tools are offered on other public clouds, there is no way to access them.
Gradient, by comparison, will allow you to connect any new feature on any cloud to your machine learning workflow. Ultimately the lack of lock-in and the extensibility protect critical business intellectual property and competitive advantage.
Deep Learning Flexibility and Compatibility
As your machine learning sophistication grows, it is possible that your algorithmic work will also grow in complexity.
Similarly, it is possible that classical machine learning techniques will not be sufficient for your application – especially if your application involves audio or video, or if a particular classical algorithm is limiting the accuracy of your results.
When deep learning is required, Paperspace Gradient makes it much easier to deploy models to GPUs.
The reasons for this are multiple:
- Distributed training on GPU-accelerated machines is simple via the Gradient job runner
- GPU pricing is more attractive on Gradient than on AWS EC2
- Gradient has out-of-the-box compatibility with the most popular deep learning frameworks such as PyTorch and TensorFlow
- Easy to go from a single node deployment to massive distributed training
- Easy to onboard, easy to develop, easy to scale
Gradient generally enables faster development of a deep learning model from research to production, thus accelerating the speed at which a deep learning model may be trained, deployed, and improved over time.
Critically, Gradient also makes it exceptionally easy to scale a model to massive distributed training.
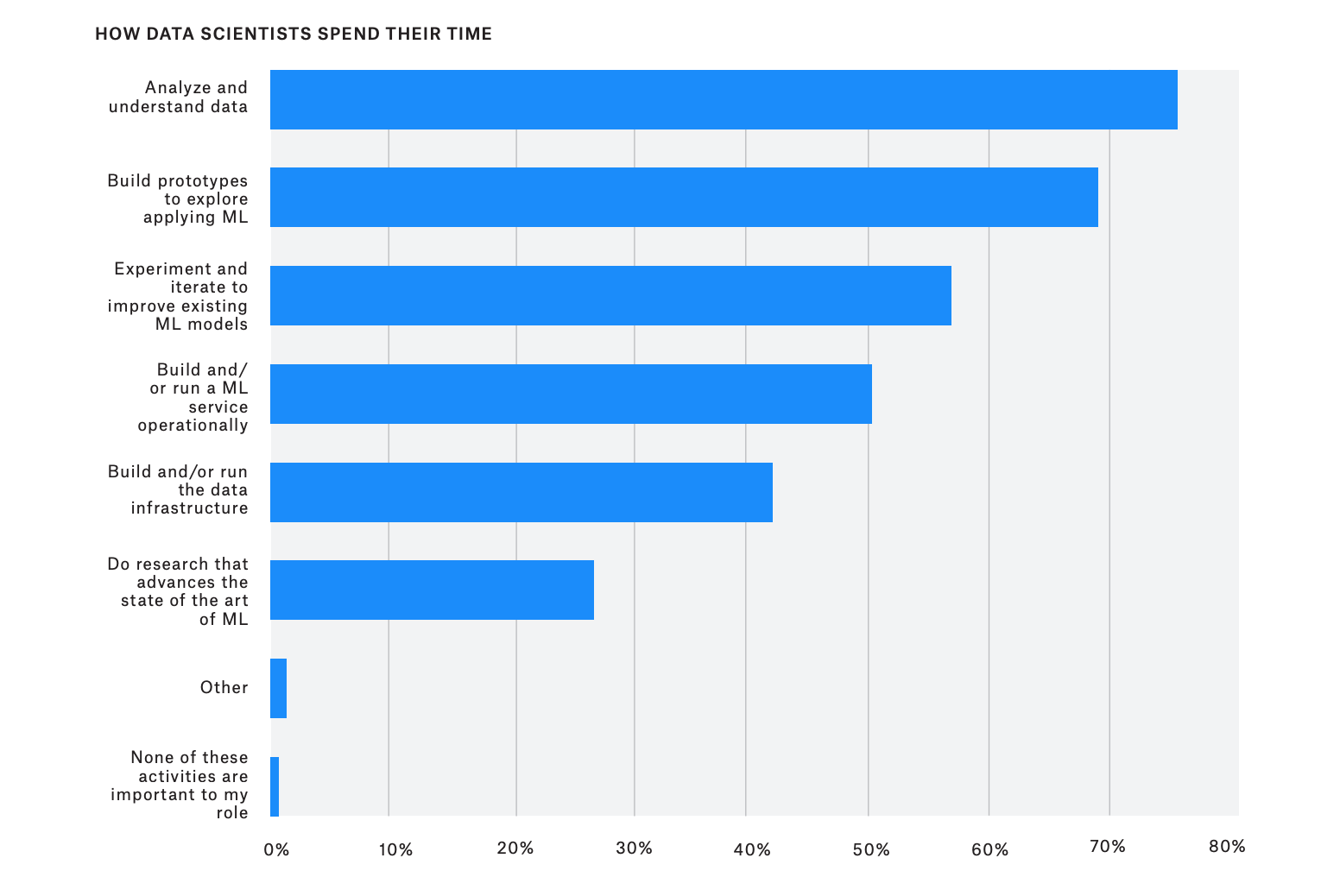
A Final Note: Time Spent Tooling
As the data from the Kaggle State of Data Science and Machine Learning 2019 reveal, a major part of a data scientist's time is spent on data infrastructure and service operation.
First-rate data science teams often also include DevOps and/or infrastructure engineers.
Since the goal for any data science team should be to return more insight per unit time, it does not make sense that data scientists are still spending so much of their time on tooling.
Gradient makes it easier to forget about tooling and get back to the real work.
Conclusion: A Unified Platform for Machine Learning
Effortless machine learning means writing ML code, not troubleshooting infrastructure tooling. A CI/CD platform provides access to the entire stack -- from the compute layer up through the management layer -- while abstracting away tasks that don’t scale.
Ultimately the successful implementation of a CI/CD workflow for machine learning will mean better reliability, stability, determinism, and a faster pace of innovation.











