
Bring this project to life
Introduction
The process of detecting objects is important but challenging. Due in large part to recent developments in deep convolutional neural networks, object detectors have made impressive strides in accuracy in recent years. For example, one-stage object detectors strike a good balance between speed and accuracy. It's no secret that the YOLO series (YOLOv1, YOLOv2, YOLOv3, YOLOv4, Ultralytics YOLOv5, YOLOv6, YOLOv7, and the currently top performing Ultralytics YOLOv8) models are among the most well-known collections. Along the development process for these architectures, there occurred a very substantial change to the network architecture between YOLO and YOLOv3. On the foundation of YOLOv3, YOLOv4 takes into account multiple strategies, including bag of freebies and bag of specials, which significantly enhance the detector's performance. This article introduces an improved YOLOv3 model based on PaddlePaddle (PP-YOLO).
The code and model we will be exploring in this article have been released in the PaddleDetection code-base: https://github.com/PaddlePaddle/PaddleDetection. For additional, more code-based tutorials on using YOLO with Paperspace, be sure to check out our guide to training a custom model with YOLOv8, and the rest of the great articles in the Paperspace Blog YOLO tag.
The Way Toward PP-YOLO
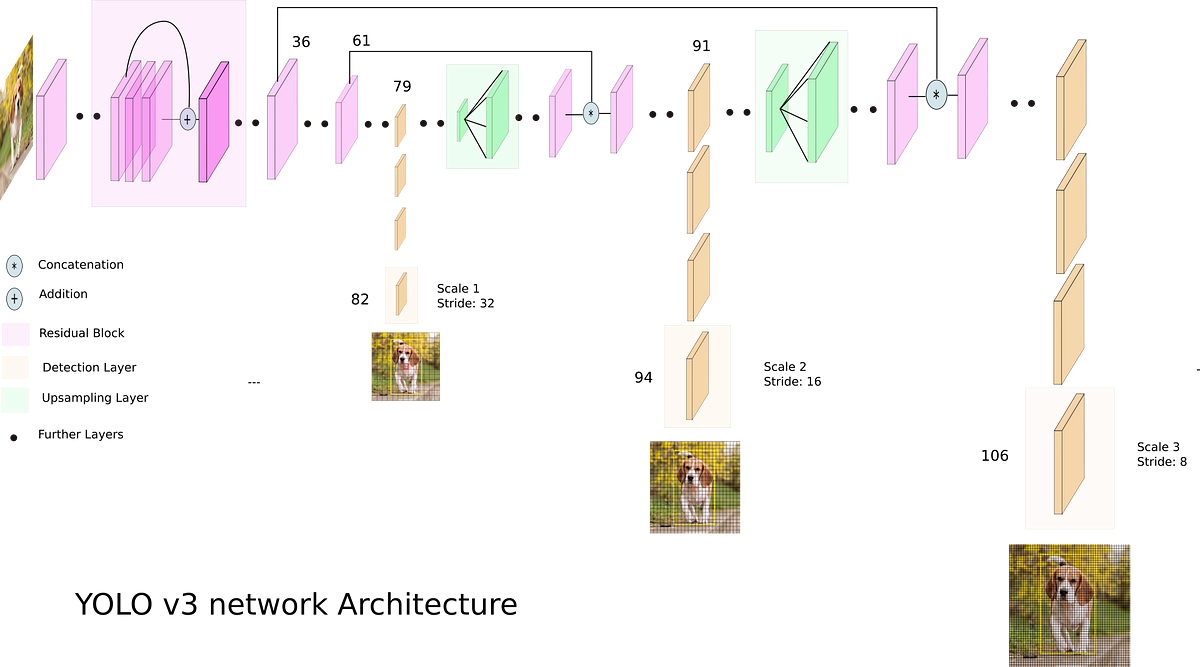
The emphasis of this study is on stacking a few efficient strategies to get higher performance. Because of the unique nature of the YOLOv3 network architecture, many of these tricks need little adjustment before they can be used successfully. Further, one should think about and experiment with where to add tricks. This research does not attempt to propose a ground-breaking detector of objects, but it's more like a recipe detailing the steps required to build an improved detector.
The YOLOv3 detector has been studied extensively, and several valuable techniques have been discovered to reduce development time.
What Does PP Stand For?
PP-YOLO stands for PaddlePaddle. YOLO for "You Only Look Once". This framework aims to make building, training, optimizing, and deploying these models for object detection more straightforward and efficient. PP-YOLO offers many standard algorithms to improve modularity, as well as data augmentation techniques, loss functions, and other features that aid in reducing the platform's footprint and facilitating high-performance deployment. Significant features are highlighted below:
- Numerous pre-trained models, including object identification, instance segmentation, face detection, etc., are available in PP-YOLO.
- A key feature of PP-YOLO is its use of modular architectures, which speed up the time it takes to create new pipelines.
- PP-YOLO offers complete lifecycle methods for data augmentation, construction, training, optimization, compression, and deployment.
- PP-YOLO also works effectively with distributed training environments.
Related Works
- Early proposal-based detectors, like Fast R-CNN, paved the way for what is now the dominant approach to object detection: anchor-based methods. Their central concept is to use anchor boxes as a priori ideas for bounding box regression. One-stage detectors and two-stage detectors are the two main categories within this field.
- To improve state-of-the-art performance in object detection, a wide variety of one-stage detectors like YOLOv2, YOLOv3, YOLOv4, RetinaNet, RefineDet, EfficentDet, FreeAnchor, and two-stage detectors such as faster R-CNN, FPN, Cascade R-CNN, Trident-Net have been proposed.
- Anchor-free detectors have recently received more and more attention. In the past two years, many new anchor-free methods have been proposed. Earlier works such as YOLOv1, DenseBox, and UnitBox can be considered as early anchor-free detectors.
- Anchor-point detectors, in contrast to anchor-box detectors, use anchor points to conduct object bounding box regression. To identify objects, keypoint-based detectors reframe the challenge as one of pinpointing their locations. Anchor-free solutions have tremendous promise for very large or oddly shaped objects since they eliminate the constraints imposed by hand-craft anchors.
Due to their high efficiency and reliability, YOLO series detectors have seen widespread practical use. Up to the time of this paper's writing, it had reached YOLOv4. Many "bag of freebies" are discussed in YOLOv4, which do not add to the infer time, and numerous "bag of specials" are also discussed, which add to the inference cost by a tiny amount but can significantly enhance the accuracy of the object detection. Compared to its predecessor, YOLOv3, YOLOv4 is much more powerful and efficient. This study explores various techniques like the YOLOv3 model on which it is based.
In contrast to YOLOV4, the authors have not dug into some of the more well-researched aspects, such as data augmentation or the backbone.
The Method
A one-stage anchor-based detector is normally made up of a backbone network, a detection neck, which is typically a feature pyramid network(FPN), and a detection head for object classification and localization.
Most anchor-point-based one-stage detectors also use these components. In the paper, the authors start by replacing the backbone to ResNet50-vd-dcn. Then, they provide a set of techniques that, when combined, can boost YOLOv3's performance without losing efficiency.
YOLOv3 Architecture
Backbone:
- Below is a diagram depicting the general structure of YOLOv3. In the original YOLOv3 implementation, feature maps of various sizes are first extracted using DarkNet-53. More variations of ResNet are available for selection, and deep learning frameworks have improved their optimizations of ResNet due to its widespread usage and significant study. Therefore, in PP-YOLO, ResNet50-vd was chosen to serve as the new backbone in place of DarkNet-53.
- The YOLOv3 detector's effectiveness will suffer if you switch directly from DarkNet-53 to ResNet50-vd. The researchers swap out parts of the regular convolutional layers with deformable ones. Numerous detection models have corroborated DCN's efficacy. While DCN alone does not add many more parameters or FLOPs to a model, adding too many DCN layers may considerably increase infer time.
- Therefore, they replace the last three 3x3 convolution layers with DCNs to strike a good compromise between efficiency and efficacy.
Detection Neck:
The FPN is used to build a feature pyramid with lateral connections between feature maps. Feature maps C3, C4, and C5 are input to the FPN module. The authors denote the output feature maps of pyramid level l as Pl, where l = 3, 4, 5 in their experiments.
Detection Head:
- The detection head of YOLOv3 is straightforward. Both convolutional layers are present in this structure. A 3X3 convolutional layer is used, followed by a 1X1 convolutional layer to get the final predictions.
- Each final prediction has an output channel of 3(K + 5), where K is the total number of classes.
- There are three anchors assigned to each position on the final prediction map. The first K channels for each anchor represent the predicted probabilities for the first K classes.
- Assumptions for bounding box localization include the following four channels. Objectness score prediction is conveyed on the last channel. Cross entropy loss and L1 loss are used for classification and localization. An objectness loss is applied to supervise the objectness score, which is used to identify whether there is an object or not.
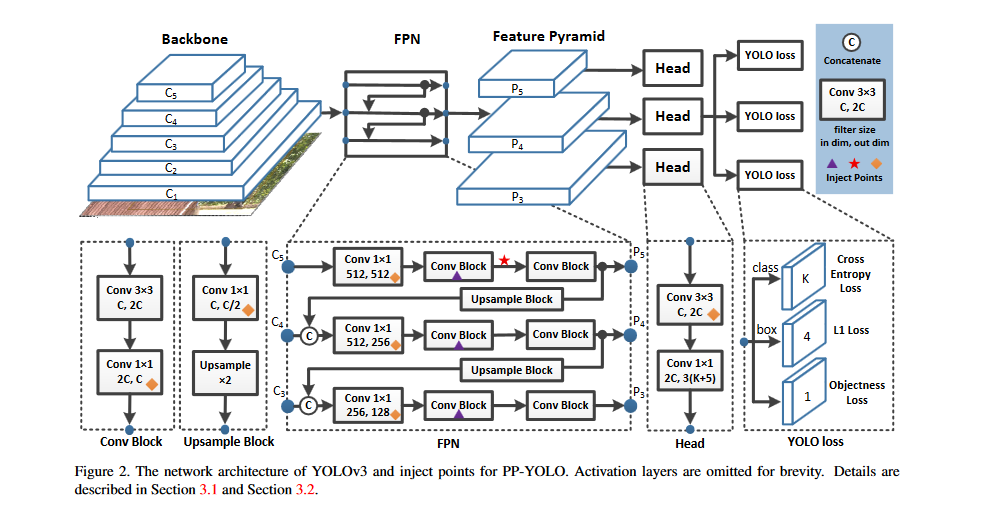
Selection of Tricks
Bring this project to life
The authors detail the methods and strategies used in the entire paper. All of these techniques are taken from various sources already in existence. This research does not provide a new way of detection but instead focuses on merging current methods to create a robust and efficient detector. Many of the old techniques won't work with YOLOv3 unless we make some changes to them to fit the new architecture.
- Larger Batch Size: Training stability and accuracy can be enhanced by increasing the batch size. In the paper, the authors raise the training batch size from 64 to 192 and then adjust the training schedule and the learning rate.
- EMA: Maintaining moving averages of the trained parameters is useful during model training. The averaged parameters used in an evaluation outperform the final values obtained after training by a significant margin. To calculate moving averages of parameters that have been trained, the Exponential Moving Average (EMA) uses exponential decay. We keep a "shadow" parameter value for every parameter we use(W).
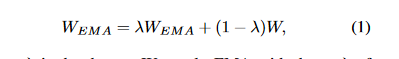
where λ is the decay. We apply EMA with decay λ of 0.9998 and use the shadow parameter WEMA for evaluation.
- DropBlock; The units in a contiguous section of a feature map are dropped collectively, making DropBlock a kind of organized dropout. To avoid a performance hit, we apply DropBlock to the FPN, unlike the original study, which applies it to the whole network. In the above figure, the "triangles" indicate the precise inject points for the DropBlock.
- IoU Loss: One of the most important aspects of object detection is bounding box regression. L1 loss is used in YOLOv3's bounding box regression. It is not tailored to the mAP evaluation metric, which strongly relies on Intersection over Union(IoU). Solutions to this issue have included IoU loss and its variants, CIoU loss, and GIoU loss. In contrast to YOLOv4, the researchers do not directly replace the L1-loss with the IoU loss; instead, they add a second branch to compute the IoU loss. Having determined that the benefits of various IoU loss are roughly the same, they have opted for the most basic IoU loss.
- IoU Aware: Without considering localization accuracy, YOLOv3's ultimate detection confidence is calculated by multiplying the classification probability and objectness score. An IoU prediction branch is added to evaluate localization accuracy. The IoU prediction branch is trained using an IoU-aware loss throughout the training process. Final detection confidence is computed during inference by multiplying the predicted IoU by the classification probability and the objectiveness score; this confidence correlates more with localization accuracy. The output of the final detection confidence is sent into the next NMS as an input. IoU aware branch will add additional computational cost. However, the incremental increase of just 0.0001% in FLOPs and 0.01% in the total number of parameters is hardly perceptible.
- Grid Sensitive: YOLOv4 has included a proper new technique called Grid Sensitive. Original YOLOv3's center x and y coordinates can be decoded as follows:
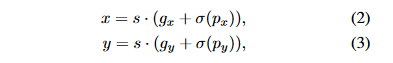
where σ is the sigmoid function, gx and gy are integers, and s is a scale factor. x and y cannot be precisely equal to s · gx or s · (gx + 1). Because of this, estimating the centers of bounding boxes right on the grid boundary is challenging. To solve this issue, we can change the equation to:
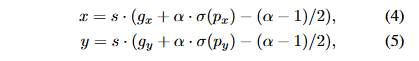
This facilitates the model's ability to predict the center of the bounding box to be on the grid boundary. The extra FLOPs provided by Grid Sensitive are insignificant and not worth considering.
- Matrix NMS: Matrix NMS is motivated by Soft-NMS, which decays the other detection scores as a monotonic decreasing function of their overlaps. Like the classic Greedy NMS, this procedure is sequential and hence unsuitable for parallel implementation. The Matrix NMS takes a different approach to this procedure and runs it in parallel. Therefore, the Matrix NMS is faster than traditional NMS, which will not bring any loss of efficiency.
- CoordConv: The key to the operation of CoordConv is the addition of coordinate channels, which allow the convolution operation to access the input coordinates directly. Networks can be taught using CoordConv to ultimately be translation invariant or have variable degrees of translation dependency. To minimize performance loss, we stick with the same number of convolutional layers in the backbone and swap out the 1x1 convolution layer in the FPN and the first convolutional layer in the detection head with CoordConv. The detailed inject points of the CoordConv are marked by" diamonds" in the figure above.
- SPP(Spatial Pyramid Pooling): Instead of using a bag-of-words operation, SPP incorporates SPM into CNN and uses max-pooling. The SPP module is used in YOLOv4 by concatenating the results of max-pooling with a kernel size of kXk, where k = 1, 5, 9, 13, and stride = 1. In this configuration, the receptive field of the backbone feature can be efficiently expanded by using a large k X k max-pooling. As shown in the "star" marked figure above, the SPP was only applied on the top feature map. Although SPP does not add any new parameters, it does increase the number of input channels for the subsequent convolutional layer. Consequently, an extra 2% of parameters and 1% of FLOPs are introduced.
- Better Pre-train model: Better detection performance could be achieved using a pre-train model with greater classification accuracy on ImageNet. Here we use the distilled ResNet50-vd model as the pre-train mode, and the detector's effectiveness is not compromised in any way by this.
Ablation Study
The effectiveness of each module is shown below in a progressive order.
Since each trick does not function in isolation, this is why some strategies work well individually, but when combined, they become less efficient. Performing a thorough study is challenging due to various possible permutations of different tricks. As a result, the researchers demonstrate how to incrementally enhance the object detector's performance in the order in which they discovered and tested the effisciency of the techniques. Results are shown in Table 1, where infer time and FPS do not consider the influence of NMS following YOLOv4.
- A → B: First of all, the researchers try to build a basic version of PP-YOLO. Initially, they switched over the YOLOv3's original Darknet53 for ResNet50-vd since the ResNet series is more popular. They discovered, however, that this would lead to a dramatic drop in mAP. The ResNet50-vd network has fewer parameters and FLOPs than Darknet53; therefore, they swap out the last 3x3 convolutional layer with a deformable one.
In this way, we get a basic PP-YOLO model (B) with a mAP of 39.1%, which is slightly higher than the original YOLOv3 (A), but its parameters, FLOPs, and infer time is much shorter than the original YOLOv3 model.
- B → C: They attempt to optimize the training strategy. They use DropBlock to prevent overfitting and employ a larger batch size and EMA to stabilize the model. Model mAP goes up to 41.4% after using these strategies, with no decrease in overall efficiency.
- C → F: They consider modifying the YOLO loss to make the model more efficient, as changing the loss usually affects the training process and seldom affects the infer time. The researchers add IoU Loss (D), IoU Aware (E) and Grid Sensitive (F) modules, and increase the mAP by 0.5%, 0.6% and 0.3% respectively. In particular, the number of parameters and the inferred time will be unaffected by IoU loss. Postprocessing time will increase by 0.7ms and 0.1ms, respectively, when using IoU Aware and Grid Sensitive due to inefficiencies in the current implementation; however, these delays may be mitigated by merging them as a single OP in PaddlePaddle in the future. On the whole,we have increased the mAP of PP-YOLO from 41.4% to 42.8%.
- F → G: It's also possible to boost performance in the postprocessing stage. They have replaced the typical greedy NMS with Matrix NMS (G). The mAP has increased by 0.6%. Because Table 1's infer time does not account for NMS, its impact is not shown. Since MatrixNMS is more effective than classic NMS, it can reduce the overall infer time.
- G → I: It is becoming more difficult to further enhance mAP without adding more parameters and FLOPs. Thus, they evaluated two approaches, CoordConv and SPP, which only need a little increase in parameters and FLOPs but can provide significant improvements. When using CoordConv, the input channel of convolutional layers will increase by 2, the number of parameters will increase by 0.03M, and the FLOPs will increase by 0.05G. Although SPP does not directly boost parameters, it does expand the input channel of the convolutional layer that follows it, leading to a 1M boost in parameters and a 0.36G boost in FLOPs. By doing so, 0.3% more mAP may be added to PP-YOLO. Due to the incorporation of these two modules, the infer time has increased by 0.3ms.
- I → J: It is usual practice to use a new model instead of one already trained. It's important to note that just because a pretrained classification model has a higher accuracy does not automatically suggest that the resulting detection model is more effective; the degree of improvement depends on the specific tricks we use.
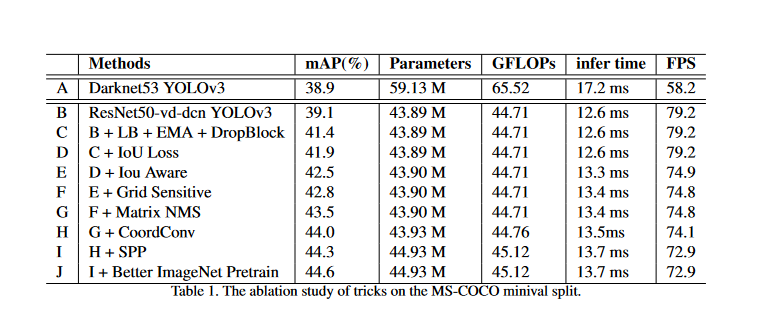
For fair comparisons, we still use ImageNet for pre-training. We use a distilled ResNet50-vd model for backbone initialization. The mAP of PP-YOLO can be further improved by 0.3%. Using other detection datasets for pre-training can significantly enhance the performance of the model, but this is beyond the scope of this paper.
Comparison with Other State-of-the-Art Detectors
A comparison of the results on the MS-COCO test split with other state-of-the-art object detectors is shown in Figure 1 and Table 2. Our PP- YOLO offers several benefits over other state-of-the-art approaches regarding speed and accuracy.
We found that our PP-YOLO enhanced the mAP on COCO from 43.5% to 45.2% and the FPS from 62 to 72.9 compared to YOLOv4. The relative improvement of PP-YOLO (around 100%) is more significant than YOLOv4(around 70%). We think this is because tensorRT optimizes for the ResNet model more effectively than Darknet.
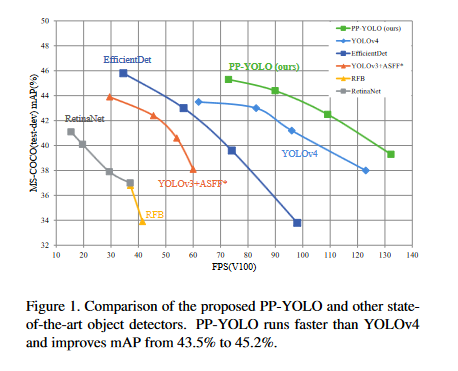
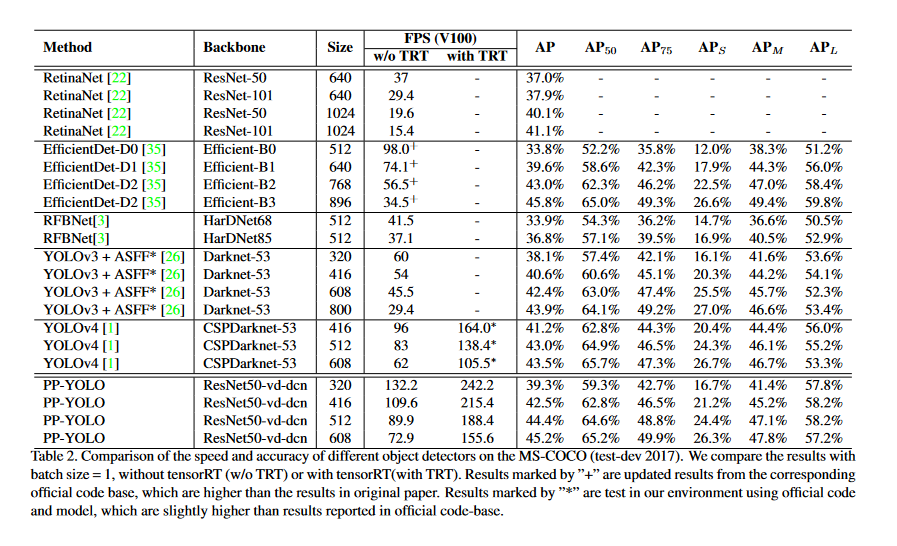
When comparing YOLOv5 to PP-YOLO, it looks that YOLOv5 still provides the best inference time vs. accuracy performance (AP vs. FPS) tradeoff on a V100. There has not yet been a paper published on YOLOv5. It has been shown that YOLOv4 architecture training on the YOLOv5 Ultralytics repository outperforms YOLOv5, and YOLOv4 trained on YOLOv5 contributions would surpass the PP-YOLO findings presented here. While these findings have not yet been properly published, they can be traced back to this GitHub discussion.
Conclusion
PP-YOLO is a novel PaddlePaddle-based object detector that is introduced in this study. Compared to other state-of-the-art detectors, such as EfficientDet and YOLOv4, PP-YOLO is faster (FPS) and more accurate (COCO mAP). In this article, we investigate various tricks, demonstrate their usefulness when combined using the YOLOv3 detector.
References
PP-YOLO: An Effective and Efficient Implementation of Object Detector: https://arxiv.org/pdf/2007.12099v3.pdf
Guide To PP-YOLO: An Effective And Efficient Implementation Of Object Detector: https://analyticsindiamag.com/guide-to-pp-yolo-an-effective-and-efficient-implementation-of-object-detector/
PP-YOLO Surpasses YOLOv4 - State of the Art Object Detection Techniques: https://blog.roboflow.com/pp-yolo-beats-yolov4-object-detection/










