
The process of handling text data is a little different compared to other problems. This is because the data is usually in text form. You therefore have to figure out how to represent the data in a numeric form that can be understood by a machine learning model. In this article, we'll take a look at how you can do just that. Finally, you will build a deep learning model using TensorFlow to classify the given text.
Let's get started. Note that you can run all of the code in this tutorial on a free GPU from a Gradient Community Notebook.
Bring this project to life
Loading data
The first step is to download and load the data. The data we'll use is a sentiment analysis dataset. It has two columns; one with the sentiment and another with its label. Let's download and load it.
!wget --no-check-certificate \ https://drive.google.com/uc?id=13ySLC_ue6Umt9RJYSeM2t-V0kCv-4C-P -O /tmp/sentiment.csv \ -O /tmp/sentiment.csv
import pandas as pd
df = pd.read_csv('/tmp/sentiment.csv')Here is a sample of the data.
Let's now select the features and the target, then split the data into a training and test set.
X = df['text']
y = df['sentiment']
from sklearn.model_selection import train_test_split
X_train, X_test , y_train, y_test = train_test_split(X, y , test_size = 0.20)Data preprocessing
Since this is text data, there are several things you have to to clean it. This includes:
- Converting all sentences to lowercase
- Removing all quotation marks
- Representing all words in some numerical form
- Removing special characters such as
@and%
All the above can be achieved in TensorFlow using Tokenizer. The class expects a couple of parameters:
num_words: the maximum number of words you want to be included in the word indexoov_token: the token to be used to represent words that won't be found in the word dictionary. This usually happens when processing the training data. The number 1 is usually used to represent the "out of vocabulary" token ("oov" token)
The fit_on_texts function is used to fit the Tokenizer on the training set once it has been instantiated with the preferred parameters.
from keras.preprocessing.text import Tokenizer
vocab_size = 10000
oov_token = "<OOV>"
tokenizer = Tokenizer(num_words = vocab_size, oov_token=oov_token)
tokenizer.fit_on_texts(X_train)The word_index can be used to show the mapping of the words to numbers.
word_index = tokenizer.word_index
Converting text to sequences
The next step is to represent each sentiment as a sequence of numbers. This can be done using the texts_to_sequences function.
X_train_sequences = tokenizer.texts_to_sequences(X_train)Here is how these sequences look.

Let's do the same for the test set. When you check a sample of the sequence you can see that words that are not in the vocabulary are represented by 1.
X_test_sequences = tokenizer.texts_to_sequences(X_test)

Padding the sequences
At the moment, the sequences have different lengths. Usually, you will pass a sequence of the same length to a machine learning model. You therefore have to ensure that all sequences are of the same length. This is done by padding the sequences. Longer sequences will be truncated while shorter ones will be padded with zeros. You will therefore have to declare the truncation and padding type.
Let's start by defining the maximum length of each sequence, the padding type, and the truncation type. A padding and truncation type of "post" means that these operations will take place at the end of the sequence.
max_length = 100
padding_type='post'
truncation_type='post'With those in place, let's start by padding the X_test_sequences. This is done using the pad_sequences function while passing the parameters defined above.
from keras.preprocessing.sequence import pad_sequences
X_test_padded = pad_sequences(X_test_sequences,maxlen=max_length,
padding=padding_type, truncating=truncation_type)The same should be done for the X_train_sequences.
X_train_padded = pad_sequences(X_train_sequences,maxlen=max_length, padding=padding_type,
truncating=truncation_type)Printing the final results shows that zeros have been added at the end of the sequences to make them of the same length.
Using GloVe word embeddings
TensorFlow enables you to train word embeddings. However, this process not only requires a lot of data but can also be time and resource-intensive. To tackle these challenges you can use pre-trained word embeddings. Let's illustrate how to do this using GloVe (Global Vectors) word embeddings by Stanford. These embeddings are obtained from representing words that are similar in the same vector space. This is to say that words that are negative would be clustered close to each other and so will positive ones.
The first step is to obtain the word embedding and append them to a dictionary. After that, you'll need to create an embedding matrix for each word in the training set. Let's start by downloading the GloVe word embeddings.
!wget --no-check-certificate \
http://nlp.stanford.edu/data/glove.6B.zip \
-O /tmp/glove.6B.zipThe next step is to extract them into a temporary folder.
import os
import zipfile
with zipfile.ZipFile('/tmp/glove.6B.zip', 'r') as zip_ref:
zip_ref.extractall('/tmp/glove')Next, create that dictionary with those embeddings. Let's work with the glove.6B.100d.tx embeddings. The 100 in the name is the same as the maximum length chosen for the sequences.
import numpy as np
embeddings_index = {}
f = open('/tmp/glove/glove.6B.100d.txt')
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
print('Found %s word vectors.' % len(embeddings_index))The next step is to create a word embedding matrix for each word in the word index that you obtained earlier. If a word doesn't have an embedding in GloVe it will be presented with a zero matrix.
embedding_matrix = np.zeros((len(word_index) + 1, max_length))
for word, i in word_index.items():
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
# words not found in embedding index will be all-zeros.
embedding_matrix[i] = embedding_vectorHere is what the word embedding for the word "shop" looks like.
Creating the Keras embedding layer
The next step is to use the embedding you obtained above as the weights to a Keras embedding layer. You also have to set the trainable parameter of this layer to False so that is not trained. If training happens again the weights will be re-initialized. This will be similar to training a word embedding from scratch. There are also a couple of other things to note:
- The Embedding layer takes the first argument as the size of the vocabulary.
1is added because0is usually reserved for padding - The
input_lengthis the length of the input sequences - The
output_dimis the dimension of the dense embedding
from tensorflow.keras.layers import Embedding, LSTM, Dense, Bidirectional
embedding_layer = Embedding(input_dim=len(word_index) + 1,
output_dim=max_length,
weights=[embedding_matrix],
input_length=max_length,
trainable=False)Creating the TensorFlow model
The next step is to use the embedding layer in a Keras model. Let's define the model as follows:
- The embedding layer as the first layer
- Two Bidirectional LSTM layers to ensure that information flows in both directions
- The fully connected layer, and
- A final layer responsible for the final output
from tensorflow.keras.models import Sequential
model = Sequential([
embedding_layer,
Bidirectional(LSTM(150, return_sequences=True)),
Bidirectional(LSTM(150)),
Dense(128, activation='relu'),
Dense(1, activation='sigmoid')
])Training the model
The next step is to compile and train the model.
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
As the model is training, you can set an EarlyStopping callback to stop the training process once the mode stops improving. You can also set a TensorBoard callback to quickly see the model's performance later.
from tensorflow.keras.callbacks import EarlyStopping, TensorBoard
%load_ext tensorboard
rm -rf logs
log_folder = 'logs'
callbacks = [
EarlyStopping(patience = 10),
TensorBoard(log_dir=log_folder)
]
num_epochs = 600
history = model.fit(X_train_padded, y_train, epochs=num_epochs, validation_data=(X_test_padded, y_test),callbacks=callbacks)You can use the evaluate method to quickly check the performance of the model.
loss, accuracy = model.evaluate(X_test_padded,y_test)
print('Test accuracy :', accuracy)
Visualization
The performance of the model can be seen by launching TensorBoard from the log directory.
%tensorboard --logdir logs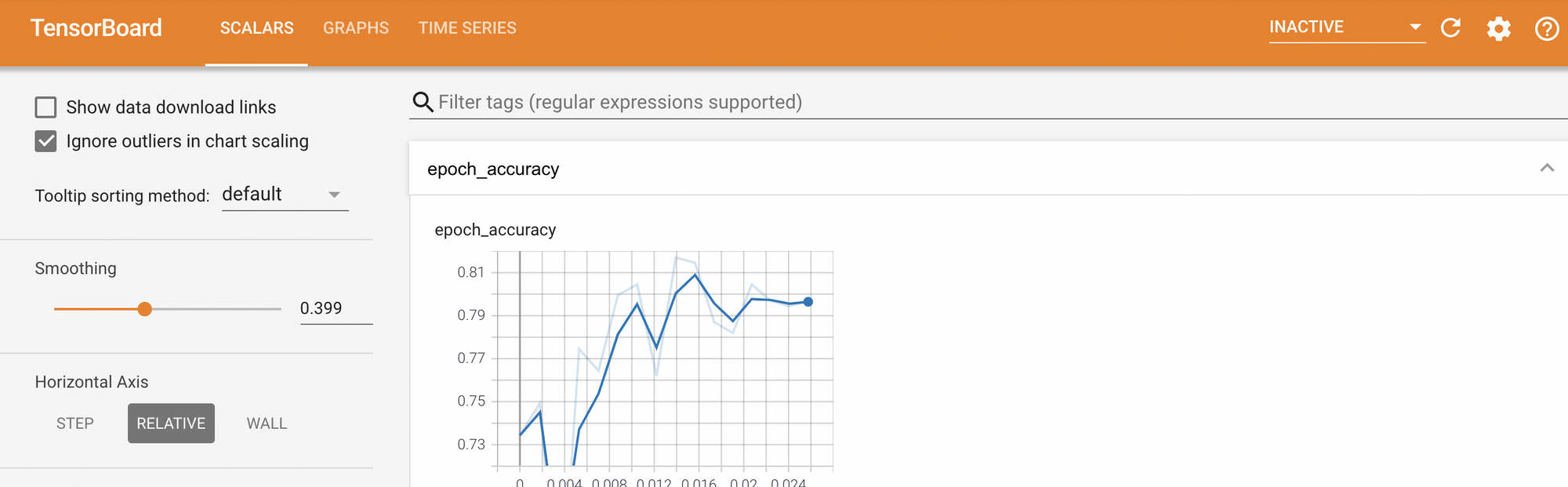
You can also use the Graph's section of TensorBoard to visualize the model in-depth.
Final Thoughts
In this article, you have walked through an example of how to use pre-trained word embedding in natural language processing problems. You can try and improve this model by:
- Changing the size of the vocabulary
- Using different pre-trained word embeddings
- Using different model architectures
You can also try your hands on this example by running it on a free GPU in a Gradient Community Notebook.











