
Bring this project to life
Prompt-based NLP is one of the hottest topics in the natural language processing space being discussed by people these days. And there is a strong reason for it, prompt-based learning works by utilizing the knowledge acquired by the pre-trained language models on a large amount of text data to solve various types of downstream tasks such as text classification, machine translation, named-entity detection, text summarization, etc. And that too under the relaxed constraint of not having any task-specific data in the first place. Unlike the traditional supervised learning paradigm, where we train a model to learn a function that maps input x to output y, here the idea is based on language models that model the probability of text directly.
Some of the interesting questions that you can ask here are, Can I use GPT to do Machine Translation? Can I use BERT to do Sentiment Classification? and all of it without having to train them for these tasks, specifically. And that’s exactly where prompt-based NLP comes to the rescue. So in this blog, We’ll try to summarise some initial segments from this exhaustive and beautifully written paper -Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing. In this blog, we discuss various types of learning paradigms present in NLP, notations often used in prompt-based paradigm, demo applications of prompt-based learning, and discuss some of the design considerations to make while designing a prompting environment. This blog is part 1 of 3 blog series that will soon follow up discussing other details from the paper like Challenges of such a system, Learning to design the prompts automatically, etc.
Evolution of NLP Learning Space
- Paradigm 1: Fully Supervised (Non-neural Networks) — These were the initial days when TF-IDF and other manually-designed features with Support Vector Machines, Decision Trees, K-Nearest Neighbours, etc, were considered fashionable
- Paradigm 2: Fully Supervised (Neural Networks) — Computation got a little cheaper, and research on neural networks finally progressed. These were the days when the use of Word2Vec with Long short-term memory (LSTM), other deep neural network architectures, etc became popular.
- Paradigm 3: Pre-train, Fine-tune — Cut to around 2017 till date, these are the days when fine-tuning the pre-trained models like BERT, CNN, etc on specific tasks was the most popular methodology.
- Paradigm 4: Pre-train, Prompt, Predict — Since last year, everyone is talking about Prompt-based NLP. Unlike the previous learning paradigm, where we were trying to push the model to fit the data, here we are trying to accommodate data to fit the pre-trained model.
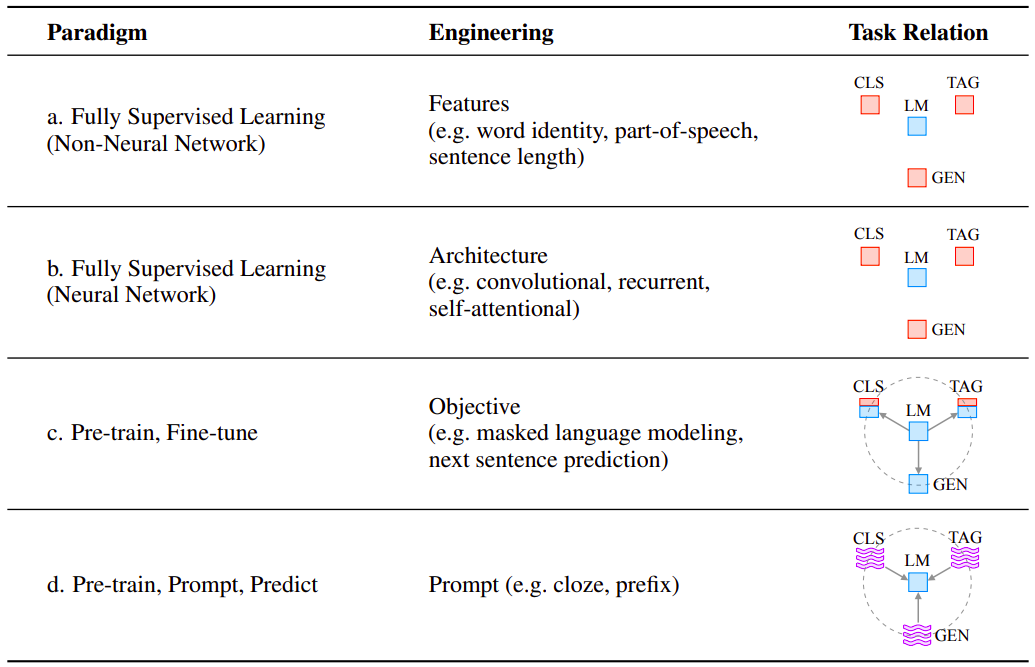
Until Paradigm 3: Pre-train, Fine-tune, the use of Language Models as a base model for almost every task didn't exist. That’s why we don’t see an arrow under the "Task Relation" column in the figure above amongst the boxes. Also, as discussed above, with Prompt-based learning the idea is to design input to fit the model. The same is depicted in the above table with incoming arrows to LM (Language Model), where the tasks are CLS (Classification), TAG (Tagging), GEN (Generation).
Prompting Notations
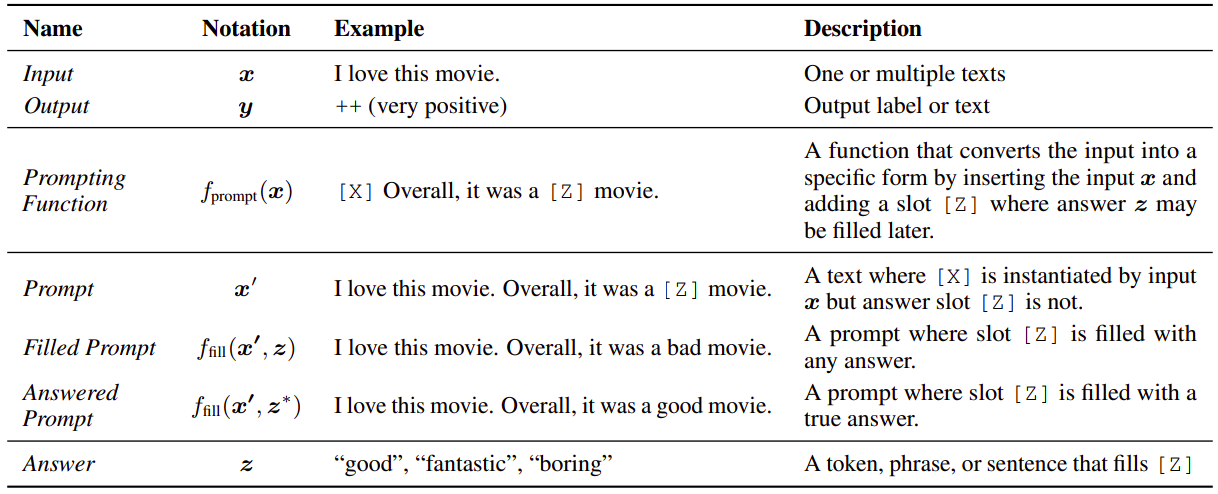
As can be seen in the below figure, we start with input (x) (Let’s say a movie review), and output expected (y). The first task is to re-format this input using a prompt function (mentioned Fprompt in the image), the output of which is denoted as (x'). Now it’s the task of our language model to predict z values in place of the placeholder Z. Then for prompts where the slot Z is filled with an answer, we refer to it as called Filled prompt, and if that answer is true, we call it Answered prompt.
Applications
Some of the popular applications of this paradigm are Text Generation, Question Answering, Reasoning, Named Entity Recognition, Relation Extraction, Text Classification, etc.
- Text Generation - Text generation involves generating text, usually conditioned on some other piece of information. With the use of models trained in an auto-regressive setting, the task of text generation becomes natural. Often, the prompts designed are prefixed in nature with a trigger token as a hint for the model to start the generation process.
- Question Answering - Question answering (QA) aims to answer a given input question, often based on a context document. For example - given an input passage if we want to get all the names mentioned in the passage, we can formulate our prompt to be "Generate all the person names mentioned in the above passage. Our model now behaves similarly to text generation, where the question becomes the prefix.
- Named Entity Recognition - Named entity recognition (NER) is a task of identifying named entities (e.g., person name, location) in a given sentence. For example - if the input is "Prakhar likes playing cricket", to determine what type of entity "Prakhar" is, we can formulate the prompt as "Prakhar is a Z entity", and the answer space Z generated by the pre-trained language model should be person, organization, etc, which "person" having the highest probability.
- Relation Extraction - Relation extraction is the task of predicting the relation between two entities in a given sentence. This video explanation talks about modeling the relation extraction task as a natural language inference task using a pre-trained language model in a zero-shot setting.
- Text Classification - Text classification is the task of assigning a pre-defined label to a given text piece. The possible prompt for this task could be "the topic of this document is Z.", which is then fed into mask pre-trained language models for slot filling.
Feel free to checkout GPT-3 playground and test your prompts -
 GPT-3 Demo
GPT-3 Demo
Demo
Bring this project to life
We will be using OpenPrompt - An Open-Source Framework for Prompt-learning for coding a prompt-based text classification use-case. It supports pre-trained language models and tokenizers from huggingface transformers.
You can install the library with a simple pip command as shown below -
>> pip install openpromptWe simulate a 2-class problem with classes being sports and health. We also define three input examples for which we are interested in getting the classification labels.
from openprompt.data_utils import InputExample
classes = [
"Sports",
"Health"
]
dataset = [
InputExample(
guid = 0,
text_a = "Cricket is a really popular sport in India.",
),
InputExample(
guid = 1,
text_a = "Coronavirus is an infectious disease.",
),
InputExample(
guid = 2,
text_a = "It's common to get hurt while doing stunts.",
)
]Next, we load our language model and we choose RoBERTa for our purposes.
from openprompt.plms import load_plm
plm, tokenizer, model_config, WrapperClass = load_plm("roberta", "roberta-base")Next, we define our template that allows us to put in our input example stored in "text_a" variable dynamically. The {"mask"} token is what the model fills-in. Feel free to check out How to Write a Template? for more detailed steps in designing yours.
from openprompt.prompts import ManualTemplate
promptTemplate = ManualTemplate(
text = '{"placeholder":"text_a"} It was {"mask"}',
tokenizer = tokenizer,
)Next, we define verbalizer that allows us to project our model's prediction to our pre-defined class labels. Feel free to check out How to Write a Verbalizer? for more detailed steps in designing yours.
from openprompt.prompts import ManualVerbalizer
promptVerbalizer = ManualVerbalizer(
classes = classes,
label_words = {
"Health": ["Medicine"],
"Sports": ["Game", "Play"],
},
tokenizer = tokenizer,
)Next, we create our prompt model for classification by passing in necessary parameters like templates, language model and verbalizer.
from openprompt import PromptForClassification
promptModel = PromptForClassification(
template = promptTemplate,
plm = plm,
verbalizer = promptVerbalizer,
)Next, we create our data loader for sampling mini-batches from a dataset.
from openprompt import PromptDataLoader
data_loader = PromptDataLoader(
dataset = dataset,
tokenizer = tokenizer,
template = promptTemplate,
tokenizer_wrapper_class=WrapperClass,
)Next, we set our model in evaluation mode and make prediction for each of the input example in a Masked-language model (MLM) fashion.
import torch
promptModel.eval()
with torch.no_grad():
for batch in data_loader:
logits = promptModel(batch)
preds = torch.argmax(logits, dim = -1)
print(tokenizer.decode(batch['input_ids'][0], skip_special_tokens=True), classes[preds])Below snippet shows the output for each of the input example.
>> Cricket is a really popular sport in India. The topic is about Sports
>> Coronavirus is an infectious disease. The topic is about Health
>> It's common to get hurt while doing stunts. The topic is about HealthDesign Considerations for Prompting
Here we discuss a few of the basic design considerations that can be used while designing the prompt environment —
- Choice of Pre-trained Models — This is one of the very important steps in designing the entire prompting system. The pre-trained objective and training style derives the suitability of any model for a downstream task. For example — a BERT-like objective can be used for classification tasks but is not too suitable for text generation tasks, whereas, the models based on an Autoregressive training strategy like GPT suit really well on Natural Language Generation tasks.
- Designing Prompts — Once the pre-trained model is fixed, designing the prompts/signals and formatting the input text in a way that returns the desirable answer is again a very important task. It has a large effect on the overall accuracy of the system. One obvious way is to manually craft these prompts, but considering the limitations of such a method that is labor intensive and time taking process, there has been extensive research to automate the prompt generation process. An example of a prompt could be, let’s say — X Overall, it was a Z movie. Here, X is the review (original input), and Z is what our model predicts and the entire “bold” sequence is termed as prompt.
- Designing Answers — Every task will have its own set of markers that commonly occur in the task-specific corpus. Coming up with such a set is also important and then having a mapping function that translates these markers to actual answers/labels is another thing which we have to design. For example — "I love this movie. Overall, it was a Z movie." In this sentence, the model might predict great, awesome, very nice, nice, etc, kinds of words in place of Z. And let’s say our task is to detect sentiment, then we need to have a mapping of such words (very nice, great, etc) to their corresponding label i.e. very positive let’s say.
- Prompt-based Training Strategies: There might be situations when we have training data available for downstream tasks. Under those circumstances, we can derive methods to train parameters, either of the prompt, the LM, or both.
It's interesting to see a new stream of research coming up in NLP dealing with minimal training data and utilizing large pre-trained language models out there. We will expand to each of the above-mentioned design considerations in the follow-up parts of this blog.











