
Zero-shot learning (ZSL) is a Machine Learning paradigm that introduces the idea of testing samples with class labels that were never observed during the initial training phase. This is similar to how we humans also extrapolate our learnings to new concepts based on existing knowledge that we gather over time. The ZSL paradigm has gotten more popular lately, and that's largely because getting any domain-specific labelled data is a pretty expensive and time-consuming process. And depending on how much cost you'd want to optimize, you can have subject matter experts (SME) either label each of the input samples or seek help from them in writing tasks and domain-specific hand-crafted rules helping kick start the training phase in a weekly-supervised fashion. There have been many applications of ZSL across various verticals in machine learning, some of the popular and interesting ones being Text Classification, Image Classification, Text-to-Image Generation, Speech Translation, etc.
Text classification is the task of assigning a set of predefined categories to a given text snippet. It's often modeled in a supervised setting, where you have labelled data of domain-specific text and its associated class label/category. And then you learn some mapping function X->Y; where, X: Input Sample, Y: Category. Some examples of text classification include - Sentiment Analysis, Email Spam Classification, News categorization and so on. Feel free to follow this blog for a quick tutorial on using Transformers for text classification.
Hence, zero-shot text classification is about categorizing a given piece of text to some pre-defined group or class label without explicitly training a dedicated machine learning model on a downstream dataset containing text and label mapping.
It's possible that you might have not heard about Hugging Face 🤗 if you don't regularly practice NLP. But still, as a refresher, Hugging Face is an open-source and platform provider of machine learning technologies. It has gotten really popular among NLP developers because of its Transformers support which provides an easy way to download, train and infer state-of-the-art NLP models. The Gradient Notebook is an easy-to-use web-based Jupyter IDE with free GPUs that allow for using any library or framework underneath. It also facilitates collaborative development and public sharing - Perfect for ML developers 🚀
In this blog, we will go through a quick tutorial on playing around with the zero-shot text classification pipeline from Hugging Face 🤗 and also discuss what goes under the hood of the algorithm that makes it possible.
Bring this project to life
The notebook
Let's start by installing transformer library -
>> pip install transformersHugging Face provides the concept of pipelines that make it really easy to infer from already trained models by abstracting most of the complex code. We will be using the same idea for the task of "zero-shot-classification". The Pipeline class is the base class from which all task-specific pipelines inherit. Hence, defining the task in the pipeline triggers a task-specific child pipeline, in this case, it would be ZeroShotClassificationPipeline. There are many other tasks which you can explore, and it is worth spending some time on seeing the entire list of tasks at Hugging Face Pipeline Tasks.
Next, we go ahead and import the pipeline and define a relevant task, underlying model that facilitates the task (more about the model in later sections), and device (device=0 or for that matter any positive value is for using GPU, device=-1 is for using CPU).
from transformers import pipeline
classifier = pipeline(
task="zero-shot-classification",
device=0,
model="facebook/bart-large-mnli"
)Once our classifier object is ready, we pass in our examples for the text_piece, candidate labels and the choice of multi-class prediction or not.
import pprint
text_piece = "The food at this place is really good."
labels = ["Food", "Employee", "Restaurant", "Party", "Nature", "Car"]
predictions = classifier(text_piece, labels, multi_class=False)
pprint.pprint(predictions){'labels': ['Food', 'Restaurant', 'Employee', 'Car', 'Party', 'Nature'],
'scores': [0.6570185422897339,
0.15241318941116333,
0.10275784879922867,
0.04373772069811821,
0.027072520926594734,
0.01700017973780632],
'sequence': 'The food at this place is really good.'}As can seen in the above snippet, our model outputs a Softmax distribution across our candidate label set. The model seems to have perfectly captured the intent around the central theme being talked about, i.e Food.
Now, let's tweak this by adding in a specific pattern that tries to perform classification in a way we'd like. I have written down the template as "The diners are in the {}", where the model is supposed to fill the brackets "{}" with a contextually relevant Location. Let's see if the model is smart enough to do that.
import pprint
text_piece = "The food at this place is really good."
labels = ["Food", "Employee", "Restaurant", "Party", "Nature", "Car"]
template = "The diners are in the {}"
predictions = classifier(text_piece,
labels,
multi_class=False,
hypothesis_template=template
){'labels': ['Food', 'Restaurant', 'Employee', 'Car', 'Party', 'Nature'],
'scores': [0.6570185422897339,
0.15241318941116333,
0.10275784879922867,
0.04373772069811821,
0.027072520926594734,
0.01700017973780632],
'sequence': 'The food at this place is really good.'}Wow! The model got this correct (in the most probable sense). Given the fact that our model was never trained explicitly on question-answering style text classification, the performance still seems to be pretty good!
Let's frame another template and different candidate set this time to define the overall sentiment conveyed in the text.
import pprint
text_piece = "The food at this place is really good."
labels = ["Positive", "Negative", "Neutral"]
template = "The sentiment of this review is {}"
predictions = classifier(text_piece,
labels,
multi_class=False,
hypothesis_template=template
)
pprint.pprint(predictions){'labels': ['Positive', 'Neutral', 'Negative'],
'scores': [0.8981141448020935, 0.07974622398614883, 0.02213958650827408],
'sequence': 'The food at this place is really good.'}Nice! With the examples discussed above, it's pretty evident that this problem formulation can generalize to various downstream tasks. You can now go ahead and play around building other zero-shot use-cases. Also, feel free to check out this online demo. Now, let's move forward and delve into little details.
Under the hood
In this segment, we will look into what steps go under the hood when calling the Pipeline, and see how exactly the system can correctly classify our text into relevant labels without explicitly being trained on them.
The pipeline workflow is a set of stacked functions as defined below -
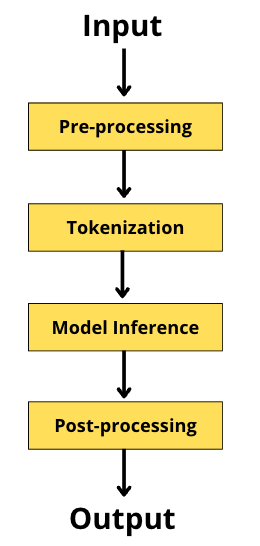
As can be seen in the figure above, we start with text sequence as our input, and next add any necessary special tokens (like SEP, CLS, etc.) wherever required as per the underlying pre-trained model and use-case. We then use the tokenizer, split our sequence into smaller chunks, map it to pre-defined vocabulary index and pass it through our model for inference purposes. The next step , post-processing, is optional and depends on the use-case and underlying model's output. This includes any additional work that needs to be done like removing special tokens, trimming to a specific maximum length, etc. Finally, we end with our output.
Talking more about the inference step in the fig. above, the underlying model (facebook/bart-large-mnli) was trained on the task of Natural Language Inference(NLI). NLI is the task of determining whether two sequences, "premise" and "hypothesis" follow each other(entails) or not (contradict) or are undetermined (neutral) or unrelated to each other. Follow the below example from nlpprogress to understand it better -
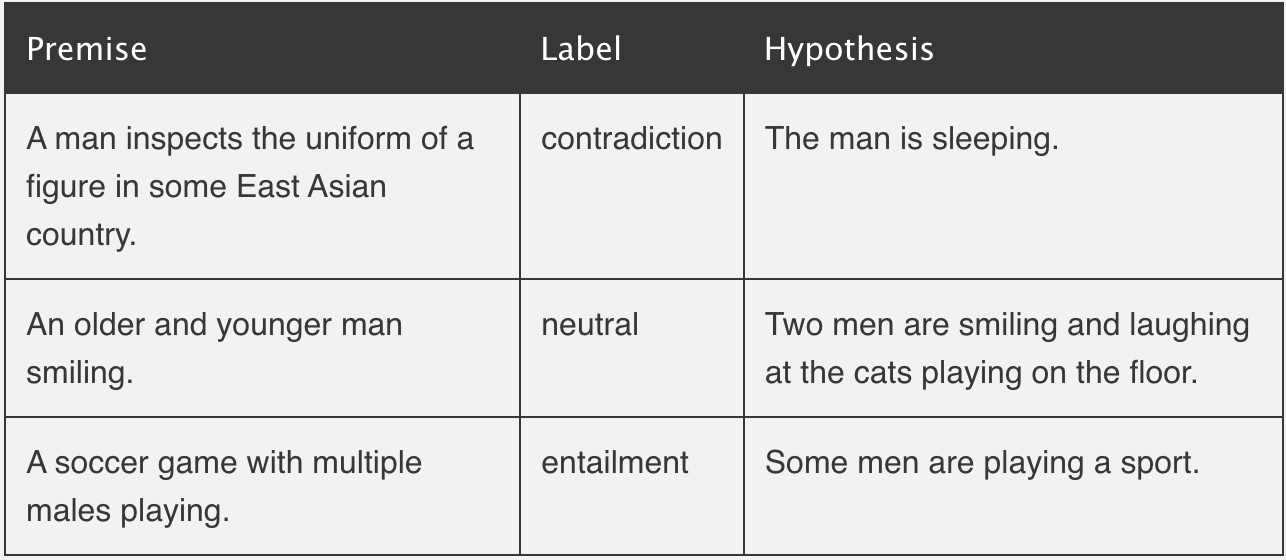
"facebook/bart-large-mnli" fine-tunes the BART model on the Multi-Genre Natural Language Inference ( MNLI) corpus. The corpus has close to 500k sentence pairs annotated with textual entailment information. The input to the BART model is a pair of sequences (Premise & Hypothesis), trained against the one hot output vector of length 3 (Entailment, Neutral, Contradict).
Surprisingly, this problem formulation can be adapted to the task of zero-shot text classification by treating text snippets and candidate labels as Premise and Hypothesis respectively. And the hope is that with the model being pre-trained on the NLI task, it now understands and learns the intricacies of relating two text pieces. This knowledge can now be used to determine if any label from the candidate set entails the text piece or not. If it does, we treat that candidate label as the true label. You can scale the same technique to Non-English sentences by loading "joeddav/xlm-roberta-large-xnli", a cross-lingual model fine-tuned on the XNLI dataset on top of XLM RoBERTa.
Concluding thoughts
So that's it for this blog. Whatever we discussed today is just one possible way of performing zero-shot text classification. We saw ways to extend NLI problem formulation to do Topic Identification, Question Answering and Sentiment Analysis. But depending on how the prompt is formatted, the possibilities are endless. You can read about a few more methods at Zero-Shot Learning in Modern NLP and follow this playlist for recent research on Zero-shot and Few-shot learning in NLP.
Thank you!











