

Bring this project to life
The promise of Large Language Model's is becoming increasingly more apparent, and their use more and more prevalent, as the technology continues to improve. With the release of LLaMA 3, we are finally starting to see Open Source language models getting reasonably close in quality to the walled garden releases that have dominated the scene since the release of ChatGPT.
One of the more enticing use cases for these models is as a writing aid. While even the best LLMs are subject to hallucinations and confident misunderstandings, the utility of being able to rapidly generate writing material on any well-known topic is useful for a multitude of reasons. As the scope of these LLM models training data increases in robustness and size, this potential only grows.
The latest and most exciting applications that take advantage of this potential is Stanford OVAL's STORM pipeline. STORM (Synthesis of Topic Outlines through Retrieval and Multi-perspective Question Asking) models enact a pre-writing stage using a collection of diverse expert agents that simulate conversations about the topic with one another, and then integrate the collated information into an outline that holistically considers the agents perspective. This allows STORM to then use the outline to generate a full Wikipedia-like article from scratch on nearly any topic. STORM impressively outperforms Retrieval Augmented Generation based article generators in terms of organization and coverage of the material.
In this article, we are going to show how to use STORM with VLLM hosted HuggingFace models to generate articles using Paperspace Notebooks. Follow along to get a short overview of how STORM works before jumping into the coding demo. Use the link at the top of the page to instantly launch this demo in a Paperspace Notebook.
What does STORM do?
STORM is a pipeline which uses a series of LLM agents with the Wikipedia and You.com search APIs to generate Wikipedia like articles on any subject, in high quality. To achieve this, the pipeline first searches Wikipedia for pertinent articles related to a submitted topic and extracts their table of contents to generate a novel outline on the topic. The information from these is then used to set up a series of subject-master, conversational agents to quickly prime an informed Wikipedia writer. The informed writer then writes the article using the outline as a scaffold.
How does STORM work?
To start, STORM uses the you.com search API to access the Wikipedia articles for the LLM. To get started with STORM, be sure to setup your API key and add it to secrets.toml in the Notebook. For the LLM writer agents, we are going to leverage VLLM to run models downloaded to the cache from HuggingFace.co. Specifically, we are going to be using Mistral's Mistral-7B-Instruct-v0.2.

From the STORM article, here is a high-level overview of different approaches to the challenge of generating Wikipedia-like articles. To do this, most approaches use a technique called pre-writing. This is the discovery stage where the LLM gets parses through material for the topic together from separate sources.
The first they considered is probably the most direct and obvious: an LLM agent generates a large amount of questions and queries the model with each. They are then recorded and ordered by the agent with subheaders to create the outline.
The second method they mentioned is Perspective-Guided Question Asking. This process involves the model first discovering diverse perspectives thorugh analysis of different, but relevant, Wiipedia articles. The LLM is then personified by these perspectives, which allows for a more accurate formation of the direct prompting questions that would generate the article outline.
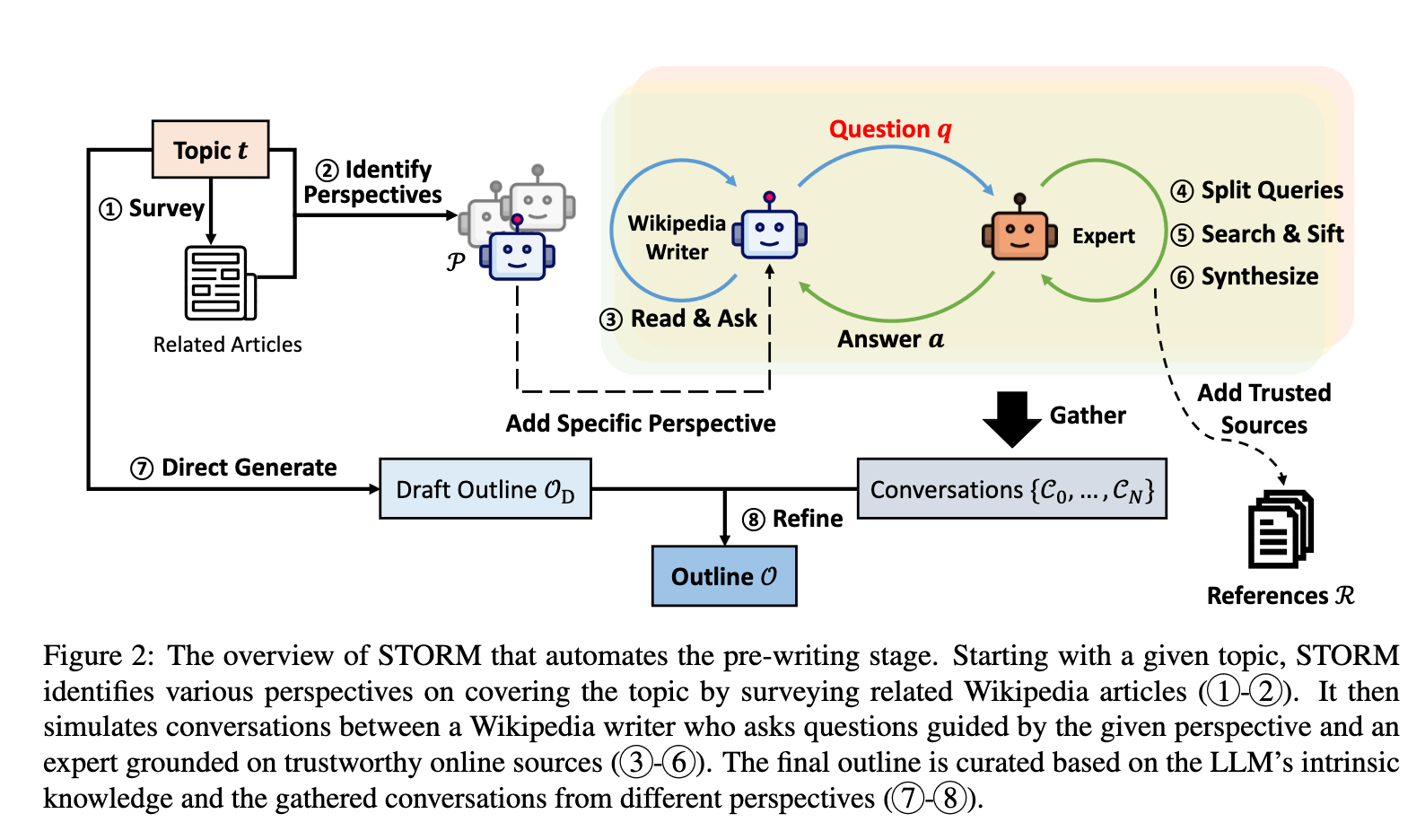
The third method is the one developed for the STORM release: Conversational Question Asking. This method involves an augmented form of Perspective-Guided Question Asking. The pipeline surveys "prompts an LLM to generate a list of related topics and subsequently extracts the tables of contents from their corresponding Wikipedia articles, if such articles can be obtained through Wikipedia API" (Source). The articles are then used to each provide a set number of perspectives to converse with the topic expert as Wikipedia writer agent. For each perspective, the Wikipedia writer and the topic expert simulate a conversation. After a set number of interactions, a topic-relevant question is generated with the context of the perspective and conversation history. The question is broken down into uncomplicated search terms, and the search results are used to exclude untrustworthy sources from being considered. The trustworthy search results are then synthesized together to generate the final answer to the question. The final question-answer interaction is then collated in a reference guide for the LLM to reference during the writing stage. The final outline uses the intrinsic knowledge to piece together the gathered knowledge from the references into a high quality article.
After the pre-writing stage is completed and before writing, the LLM is first prompted to generate a generic outline for the article from the topic. This generic outline is then used along with the input topic again and the simulated conversations to generate an improved outline from the original. This is then used during writing to guide the Wikipedia writer. The article is generated piece by piece from each section of the outline. The final outputs are concatenated to generate the full article.
Run STORM on Paperspace
Bring this project to life
To run STORM on Paperspace, there are a couple things we need to take care of first. To start, it is recommended that we have a Pro or Growth account to take advantage of running the GPUs for only the cost of the membership.
To actually run the demo, we are going to need to sign up for the You.com leverage the Web+News Search API. Use the link to sign up for the free trial, and get your API key. Save the key for later.
Once we have taken care of that preparation, we can spin up our Notebook. We recommend the Free-A6000 or Free-A100-80G GPUs for running STORM, so that we can get our results in a reasonable time frame and avoid out of memory errors. You can use the Run on Paperspace link to do all the setup instantly and run it on an A100-80G, or use the original Github repo as the workspace URL during Notebook creation.
Once your Notebook has spun up, open up STORM.ipynb to continue with the demo.
Setting up the demo
Demo setup is very straightforward. We need to install VLLM and the requirements for STORM to get started. Run the first code cell, or paste this into a corresponding terminal without the exclamation marks at the start of each line.
!git pull
!pip install -r requirements.txt
!pip install -U huggingface-hub anthropic
!pip uninstall jax jaxlib tensorflow -y
!pip install vllm==0.2.7This process may take a moment. Once it is done, run the following code cell to log in to HuggingFace.co to get your API access tokens. The token can be access or created using the link given to you by the output. Simply copy and paste it into the cell provided in the output to add your token.
import huggingface_hub
huggingface_hub.notebook_login()With that complete, we will have access to any HuggingFace model we want to use. We can change this by editing the model id in the run_storm_wiki_mistral.py file on line 35 in the mistral_kwargs variable, and also changing the model ID we call for the VLLM client.
Running the VLLM Client
To run STORM, the python script relies on API calls to input and receive outputs from the LLM. By default, this was set to use OpenAI. In the past few days, they have added functionality to enable DSPY VLLM endpoints to work with the script.
To set this up, all we need to do is run the next code cell. This will launch Mistral as an interactive API endpoint that we can directly chat with.
!python -m vllm.entrypoints.openai.api_server --port 6006 --model 'mistralai/Mistral-7B-Instruct-v0.2'Once the API has launched, we can run STORM. Use the next section to see how to configure it.
Running STORM
Now that everything is set up, all that is left for us to do is run STORM. For this demo, we are going to use their example run_storm_wiki_mistral.py. Paste the following command into a terminal window.
python examples/run_storm_wiki_mistral.py \
--url "http://localhost" \
--port 6006 \
--output-dir '/notebooks/results/' \
--do-research \
--do-generate-outline \
--do-generate-article \
--do-polish-articleFrom here, you will be asked to input a topic of your choice. This is going to be the subject of our new article. We tested ours with the inputted topic "NVIDIA GPUs". You can read a sample section from our generated article below. As we can see, the formatting mimics that of Wikipedia articles perfectly. This topic is likely one that was not heavily covered in the original model training, considering the ironic nicheness of the subject matter, so we can assume that the correct information presented in the generated text was all ascertained through the STORM research procedure. Let's take a look.
## Ampere Architecture (2020)
Ampere is the newer of the two architectures and is employed in the latest generation of NVIDIA graphics cards, including the RTX 30 Series [6]. It offers up to 1.9X Performance per Watt improvement over the Turing architecture [6]. Another great addition to the Ampere is the support for HDMI 2.1, which supports ultra-high resolution and refresh rates of 8K@60Hz and 4K@120Hz [6].
Both Turing and Ampere architectures share some similarities. They are employed in the latest generation of NVIDIA graphics cards, with Turing serving the RTX 20 Series and Ampere serving the RTX 30 Series [6]. However, Ampere comes with some newer features and improvements over the Turing GPU architecture [6].
[6] The Ampere architecture offers up to 1.9X Performance per Watt improvement over the Turing architecture. Another great addition to the Ampere is the support for HDMI 2.1 which supports the ultra-high resolution and refresh rates which are 8K@60Hz and 4K@120Hz.
[7] Look for new applications built from scratch on GPUs rather than porting of existing large simulation applications.
[8] In 2007, NVIDIA’s CUDA powered a new line of NVIDIA GPUs that brought accelerated computing to an expanding array of industrial and scientific applications.
[1] Opens parallel processing capabilities of GPUs to science and research with the unveiling of CUDA® architecture.
[9] RAPIDS, built on NVIDIA CUDA-X AI, leverages more than 15 years of NVIDIA® CUDA® development and machine learning expertise.
[10] Modeling and simulation, the convergence of HPC and AI, and visualization are applicable in a wide range of industries, from scientific research to financial modeling.
[11] PhysX is already integrated into some of the most popular game engines, including Unreal Engine (versions 3 and 4), Unity3D, and Stingray.
[12] NVIDIA Omniverse™ is an extensible, open platform built for virtual collaboration and real-time physically accurate simulation.As we can see, this is a pretty impressive distillation of the available information. While there are some smaller mistakes regarding the specifics of this highly complex and technical subject, the pipeline still was nearly completely accurate with its generated text with regard to the reality of the subject.
Closing thoughts
The applications for STORM we displayed in this article are truly astounding. There is so much potential for supercharging educational and dry content creation processes through applications of LLMs such as this. We cannot wait to see how this evolves even further as the relevant technologies improve.











