

Bring this project to life
Introduction
In the deep-learning field, the choice of the framework can significantly impact the efficiency, flexibility, and performance of machine-learning models. Over the years, this environment has changed frequently, popular frameworks like TensorFlow slowly lose their position to new releases. Over the past few years, PyTorch and JAX have emerged as two contenders among the most popular frameworks, each offering unique advantages and capabilities to developers and researchers alike.
PyTorch, developed by Facebook's AI Research lab (FAIR), has gained widespread adoption due to its simple API, dynamic computation graph allowing easy debugging, and extensive ecosystem of libraries and tools. PyTorch's flexibility and ease of use have made it a go-to choice for machine learning and A.I. practitioners.
On the other hand, JAX, an open-source project from Google Research, has recently gained popularity as a powerful framework for high-performance numerical computing. Built on functional programming principles and composable transformations, JAX offers automatic differentiation, just-in-time compilation, and parallel execution, making it particularly well-suited for scalable and efficient model training on modern hardware accelerators.
What is the difference between them?
JAX, a newer framework, at a high -level is simpler and more flexible than PyTorch for creating high-performance machine learning code. Built on top of NumPy, its syntax follows the same structure, making it an easy choice for users familiar with the popular numerical computing library. PyTorch presents a more complex syntax, which requires something of a learning curve. However, PyTorch still has greater flexibility for constructing dense neural network architectures and is far more prevalent in use for open-source projects.
Comparing the performance and speed of JAX and PyTorch, JAX works well on hardware accelerators such as GPUs and TPUs, leading to potentially faster performance in specific scenarios. However, PyTorch's longer tenure and larger community translate to more available resources for optimizing performance.
Furthermore, automatic differentiation stands as a significant feature in effectively training deep learning models. PyTorch's autograd package offers a straightforward method for computing gradients and adjusting model parameters. Meanwhile, JAX builds upon Autograd and elevates automatic differentiation by integrating its XLA (Accelerated Linear Algebra) backend.
Moreover, ecosystem and community support play crucial roles. Both frameworks provide active communities, diverse tools, and libraries for deep learning tasks. Nevertheless, PyTorch's longer establishment and larger user base result in richer resources for beginners and well-established libraries in specific domains like computer vision or natural language processing.
What is JAX? Why is it so popular?
JAX is a library developed by Google Research that can speed up machine learning and AI tasks. JAX can automatically differentiate Python and NumPy functions, even through complex structures like loops and branches. It also supports forward and reverse mode differentiation, a.k.a. back provocation, allowing for efficient gradient calculations.
Beyond differentiation, JAX can significantly speed up code using a specialized compiler called Accelerated Linear Algebra or XLA. This compiler optimizes linear algebra operations, such as fusing operations, to reduce memory usage and streamline processing. JAX goes further by allowing just-in-time compilation of custom Python functions into optimized kernels using just-in-time (JIT) compilation. Additionally, JAX provides powerful tools like PMAP for parallel execution across devices.
Now, what is PMAP? PMAP allows JAX to execute single-program multiple-data (SPMD) programs. Applying PMAP means that the function gets compiled by XLA like JIT, replicated, and then executed in parallel across devices. That's what the P in PMAP stands for.
VMAP is used for automatic vectorization, and Grad is used for gradient calculations. VMAP is used for automatic vectorization, transforming a function designed for a single data point into one capable of processing batches of varying sizes using a single wrapper function.
These features make JAX a versatile framework for building and optimizing machine learning models.
For example, when training a deep neural network on the MNIST dataset, JAX can handle tasks like batching data efficiently using VMAP and optimizing model training with JIT. While JAX is a research project and may have some rough edges, its capabilities are promising for researchers and developers alike.
Critical Points for Pytorch and JAX
- JAX performance increases when using GPUs to run the code and further the performance increases when using JIT compilation. This provides a greater advantage as GPUs utilize parallelization, which provides faster performance than CPUs.
- JAX has excellent built-in support for parallelism across multiple devices, surpassing other frameworks commonly utilized for machine learning tasks like PyTorch and TensorFlow.
- JAX provides Auto differentiation with the grad() function, this function comes in handy while training a deep neural network. As DNN requires backpropagation, JAX utilizes an analytical gradient solver instead of using other sophisticated techniques. It essentially breaks down the function's structure and applies the chain rule to compute gradients.
- Pytorch combines Torch's efficient and adaptable GPU-accelerated backend libraries with a user-friendly Python frontend. It provides prototyping, clear code readability, and extensive support for diverse deep-learning models. -
- Tensors, similar to multidimensional arrays, are a fundamental data type in PyTorch. They store and manipulate model inputs, outputs, and parameters. They share similarities with NumPy's ndarrays, with the added capability of GPU acceleration for faster computation.
Get started with JAX
We have provided links to a couple of notebooks that can be used to start experimenting with JAX.
Bring this project to life
To install JAX run the below command,
!pip install -U "jax[cuda12_pip]" -f https://storage.googleapis.com/jax-releases/jax_cuda_releases.htmlOnce the requirement is satisfied you can import the necessary libraries,
# JAX's syntax is mostly similar to NumPy's!
# There is also a SciPy API support (jax.scipy)
import jax.numpy as jnp
import numpy as np
# Special transform functions
from jax import grad, jit, vmap, pmap
# JAX's low level API
from jax import lax
from jax import make_jaxpr
from jax import random
from jax import device_putExample 1: JAX's syntax is very similar to NumPy's,
L = [0, 1, 2, 3]
x_np = np.array(L, dtype=np.int32)
x_jnp = jnp.array(L, dtype=jnp.int32)
x_np, x_jnp(array([0, 1, 2, 3], dtype=int32), Array([0, 1, 2, 3], dtype=int32))
x_np = np.linspace(0, 10, 1000)
y_np = 2 * np.sin(x_np) * np.cos(x_np)
plt.plot(x_np, y_np)
Example 2: Here's another comparison code for JAX vs PyTorch with a speed test:
The code below compares the execution time of matrix multiplication using JAX and PyTorch. It generates large matrices of 1000x1000 and measures the time taken to perform the multiplication operation using both libraries.
import time
import jax.numpy as jnp
from jax import jit, random
import torch
# Define JAX matrix multiplication function
def jax_matmul(A, B):
return jnp.dot(A, B)
# Add JIT compilation for performance
jax_matmul_jit = jit(jax_matmul)
# Define PyTorch matrix multiplication function
def torch_matmul(A, B):
return torch.matmul(A, B)
# Generate large matrices
matrix_size = 1000
key = random.PRNGKey(0)
A_jax = random.normal(key, (matrix_size, matrix_size))
B_jax = random.normal(key, (matrix_size, matrix_size))
A_torch = torch.randn(matrix_size, matrix_size)
B_torch = torch.randn(matrix_size, matrix_size)
# Warm-up runs
for _ in range(10):
jax_matmul_jit(A_jax, B_jax)
torch_matmul(A_torch, B_torch)
# Measure execution time for JAX
start_time = time.time()
result_jax = jax_matmul_jit(A_jax, B_jax).block_until_ready()
jax_execution_time = time.time() - start_time
# Measure execution time for PyTorch
start_time = time.time()
result_torch = torch_matmul(A_torch, B_torch)
torch_execution_time = time.time() - start_time
print("JAX execution time:", jax_execution_time, "seconds")
print("PyTorch execution time:", torch_execution_time, "seconds")JAX execution time: 0.00592041015625 seconds
PyTorch execution time: 0.017140865325927734 seconds
Example 3: A comparison code for Automatic Differentiation in JAX and PyTorch
These codes demonstrate automatic differentiation for the function,
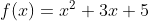
using JAX and PyTorch. JAX's grad function is used to compute the derivative in the JAX code, while PyTorch's autograd mechanism is utilized in the PyTorch code
#for JAX
import jax.numpy as jnp
from jax import grad
# Define the function to differentiate
def f(x):
return x**2 + 3*x + 5
# Define the derivative of the function using JAX's grad function
df_dx = grad(f)
# Test the derivative at a specific point
x_value = 2.0
derivative_value = df_dx(x_value)
print("Derivative (JAX) at x =", x_value, ":", derivative_value)
Derivative (JAX) at x = 2.0 : 7.0
#for PyTorch
import torch
# Define the function to differentiate
def f(x):
return x**2 + 3*x + 5
# Convert the function to a PyTorch tensor
x = torch.tensor([2.0], requires_grad=True)
# Calculate the derivative using PyTorch's autograd mechanism
y = f(x)
y.backward()
derivative_value = x.grad.item()
print("Derivative (PyTorch) at x =", x.item(), ":", derivative_value)
Derivative (PyTorch) at x = 2.0 : 7.0
Conclusion
In conclusion, both PyTorch and JAX offer powerful frameworks for machine learning and developing deep neural networks. Each framework comes with its strengths and areas of expertise. PyTorch excels in its ease of use, extensive community support, and flexibility for rapid prototyping and experimentation, making it an ideal choice for many deep-learning projects. On the other hand, JAX shines in its performance optimization, functional programming paradigm, and seamless integration with hardware accelerators, making it a preferred framework for high-performance computing and research at scale. Ultimately, the choice between PyTorch and JAX depends on the project's specific requirements, balancing ease of development against performance and scalability needs. With both frameworks continually evolving and pushing the boundaries of innovation, practitioners are fortunate to have access to such versatile tools driving advancements.











