
Introduction
Text classification or categorization (TC) is a fundamental subtask in all NLU tasks. Textual information comes from a variety of places, including social media, electronic communications, and customer interactions that involve questions and answers. Text is a great source of information in itself, but it can be difficult and time-consuming to draw conclusions from it due to its lack of organization.
Text classification (TC) can be performed either manually or automatically. Data is increasingly available in text form in a wide variety of applications, making automatic text classification a powerful tool. Automatic text categorization often falls into one of two broad categories: rule-based or artificial intelligence-based. Rule-based approaches divide text into categories according to a set of established criteria and require extensive expertise in relevant topics. The second category, AI-based methods, are trained to identify text using data training with labeled samples.
Limitations of traditional approaches
Reading, understanding, and interpreting make up the bulk of NLU's work. The first step is to manually extract certain features from any document, and the second step is to use those features to train a classifier and make a prediction.
One type of manually extracted feature is a Bag of Words (BoW), and well-known classification methods include Naive Bayes, Logistic Regression, Support Vector Machines, and Random Forests. This multi-step process has a number of drawbacks; relying on the manually collected features requires complex feature analysis to obtain accurate results. More work is needed to generalize this approach to other tasks because it relies heavily on local domain knowledge for feature engineering.
In addition, the predetermined features of these models prevent them from taking advantage of the vast amounts of training data available.
To overcome these limitations, researchers have turned to neural network approaches. Instead of relying on manually extracted features, these methods focus on a machine learning technique that maps text to a low-dimensional continuous feature vector.
Evolution of deep learning models in NLU
- Latent Semantic Analysis (LSA) was first introduced in 1989 by Deerwester et al. It has a long history as one of the first embedding models. When trained on the 200K word corpus, LSA is a linear model with less than a million parameters. The model has certain shortcomings, such as the inability to fully exploit the dimensional information in the vector representation and the statistical properties of an LSA space when used as a measure of similarity.
- In 2000, Bengeo et al. presented the first natural language model. It uses 14 million words for training and is based on a feed-forward neural network. However, the performance of these early embedding models is inferior to that of more conventional models that rely on manually extracted features. This situation shifted dramatically as larger embedding models with more extensive training data were created.
- Google's word2vec models, built in 2013, are considered state-of-the-art for many NLU applications, having been trained on a corpus of 6 billion words.
- In 2017, AI2 and the University of Washington worked together to develop a three-layer bidirectional LSTM contextual embedding model with 93 million parameters and 1 billion words. The Elmo model outperforms the word2vec method by a wide margin because to its ability to take into account context.
- In 2018, OpenAI has been leveraging Google's Transformer, a ground-breaking neural network architecture, to create embedding models. Large-scale model training on TPU benefits greatly from the transformer's reliance on attention.
- The original Transformers-based approach, GPT, is still widely used today for text generating tasks. Based on the bidirectional transformer, Google developed BERT in 2018. BERT is a 340M parameter model that is trained on 3.3B words. The most recent model from OpenAI, GPT-3, maintains this trend toward larger models with more training data.
- It has 170 billion parameters, compared to 600 billion in Google's Gshard. Microsoft's T-NLG has 17 billion parameters, while NVIDIA's Megatron has 1 trillion training parameters; both are popular models based on generative pre-trained transformer approaches.
- While some researchers have shown that these large-scale models perform brilliantly on certain NLU tasks, others have found that they lack language understanding and are hence unfit for many key applications.
Feed-forward networks based models
Feed-forward networks are a type of simple DL model used to represent text. In these frameworks, words are treated as the building blocks of text. These models use word2ve or GloVe to learn a vector representation of each word. Another classifier, fastText, was presented by Joulin et al. To learn more about the local word order, fastText uses a set of n-grams as an additional feature. This approach is effective because it gives similar results to techniques that take word order into account. The unsupervised algorithm doc2vec was developed by Le and Mikolove to learn fixed-length feature representations of variable-length text.
RNN-based models
In RNN-based models, the text is often interpreted as a word order. Capturing word relationship between sentences and text structure is the main goal of an RNN-based model for text categorization. However, regular feed-forward neural networks outperform RNN-based models. One type of RNN designed to learn long-term relationships between words and sentences is the Long Short-Term Memory (LSTM) model. The values are stored in a memory cell that has an input, an output, and a forget gate to keep them safe for a certain amount of time. LSTM models use this memory cell to fix the vanishing gradient and gradient boosting issues of regular RNNs.
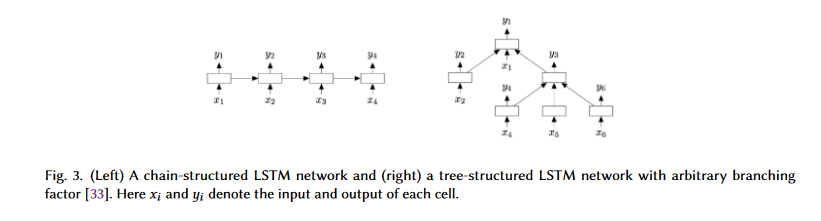
By extending the LSTM model to include tree-structured network types, Tai et al. create a model capable of learning detailed semantic representations. Since real language displays syntactic features that would naturally join words to phrases, the authors believe that Tree-LSTM is more effective than the chain-structured LSTM for NLP applications. Two tasks, sentiment classification and semantic similarity prediction, are used to verify Tree-LSTM's efficiency. Model architectures are shown in Fig. 3.
Models based on CNN
Unlike RNNs, which are trained to recognize patterns over time, CNNs are trained to find patterns in space. While RNNs excel at natural language processing (NLP) tasks that require an understanding of long-range semantics, such as RQA-POS tagging, CNNs excel at tasks where the perception of local and location-independent patterns in text is critical. These repeated occurrences may be key phrases used to express a particular sentiment.
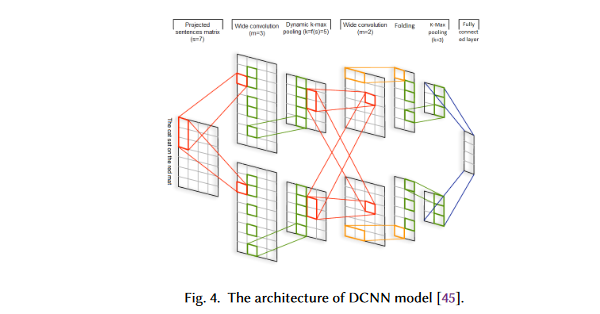
This has led to the widespread adoption of CNNs as a model for general-purpose text categorization. A novel CNN-based text categorization has been proposed by Kalchbrenner et al. Depending on the pooling method used, the model can be referred to as a dynamic K-max pooling model.
The first layer of a DCNN builds a sentence matrix by embedding each word in the sentence. A convolutional structure that combines large convolutional layers with dynamic convolutional settings is used in the second stage of the process.
Using the dynamic K-max pooling layers, we build a sentence-wide feature map that captures different degrees of relatedness between words.
Based on the sentence size and the convolution hierarchy level, the pooling parameter is chosen dynamically at runtime.
Capsule neural network-based models
CNN's picture and text classification is carried out by several layers of convolutions and pooling. While pooling techniques are able to identify important features and reduce the computational cost of convolution processes, they are unable to account for spatial information and may lead to misclassification of objects based on their orientation or proportion.
To get around the issues related to pooling, Hinton et al. proposed a novel method called capsule networks (CapsNets). The activity vector of a group of neurons known as a capsule has several of the hallmarks of a block or partial block. A block's probability of existence is represented by the vector's length, and the block's attributes are represented by the vector's orientation.
In contrast to max-pooling in CNNs, which only uses a subset of the available information for classification, capsules "route" each capsule in the bottom layer to its best parent capsule in the upper layer. Many methods exist for implementing routing, including dynamic routing by agreement.. Several methods, such as the Expectation-Maximization algorithm and dynamic routing by agreement, could achieve this task.
Models with attention mechanism
Attention can be directed in many ways, such as focusing on specific parts of an image or clusters of words in a sentence. Building DL models for NLP increasingly focuses on attention as a key concept and technique. It's a vector with some important weights on it. Using the attention vector, we can evaluate the strength of a word's relationship to the other words in the sentence, and then by summing the weighted values of the attention vector, we can predict the target value.
Yang et al. [79] propose a hierarchical attention network for text classification. This model has two distinctive characteristics: (1) a hierarchical structure that mirrors the hierarchical structure of documents, and (2) two levels of attention mechanisms applied at the word and sentence-level, enabling it to attend differentially to more and less important content when constructing the document representation.
Models based on graph neural network
While regular texts have a sequential order, they also contain underlying network structures, similar to parse trees, that infer their relationship based on the syntax and semantic properties of sentences.
TextRank is a novel NLP model based on graph theory. The authors propose that a text written in a natural language is represented as a graph G (V, E), where V represents a set of nodes and E represents a set of edges connecting these nodes. The various pieces of text that make up sentences are represented by nodes. Edges can also be used to indicate other types of relationships between nodes, depending on the context in which they are used.
DNN models based on CNNs, RNNs, and autoencoders have been modified in recent years to deal with the complexity of graph data. Because of their efficiency, versatility, and ability to be combined with other networks, GCNs and their offshoots have become quite popular among the various types of GNNs.
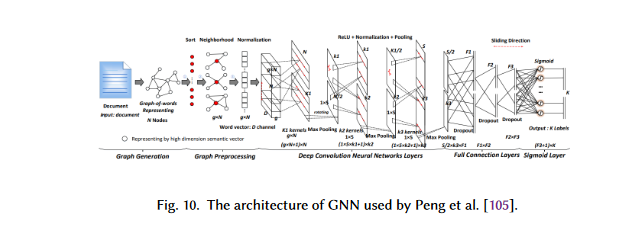
TC is a common use case for GNNs in NLP. To infer document labels, GNNs use the relationships between documents or words. The graph CNN based DL model proposed by Peng et al. involves first transforming text into a graph of words and then convolving this graph using graph convolution processes.
Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) are two examples of additional neural network designs that can be integrated with GNN-based models to enhance their performance. Training GNN-based models on large graphs can be challenging, and the learning representations are sometimes difficult to interpret. Improved GNN-based models, as well as methods for interpreting and visualizing the learned representations, may be the focus of future research in this area.
Models with hybrid techniques
The combination of LSTM and CNN architectures has led to the development of a large number of hybrid models that can distinguish between global and local documents.
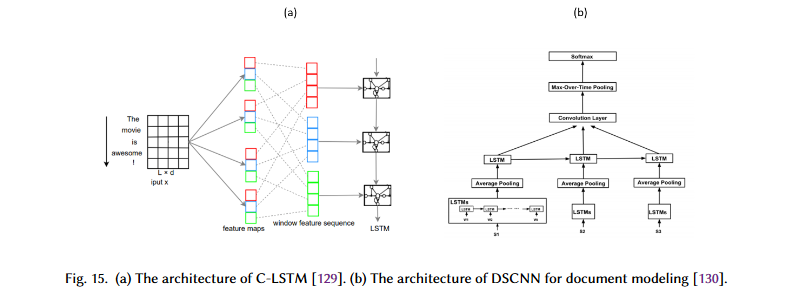
Zhou et al. came up with the idea of a network known as Convolutional LSTM (C-LSTM). In C-LSTM, a CNN is used to extract a set of phrase (n-gram) representations. These representations are then fed into an LSTM network to obtain the sentence-level representation.
For document modeling, Zhang et al. propose a dependency sensitive CNN (DSCNN). For multi-label TC, Chen et al. use a CNN-RNN model. Tang et al. use a CNN to interpret sentence representations that encode the basic links between sentences. In the hierarchical model of the DSCNN, the LSTM learns the sentence vectors, which are then fed into the convolution and max-pooling layers to create the document representation, as shown in the figure below.
Models based on transformers
A computational challenge for RNNs is the sequential processing of text. While RNNs are more sequential than CNNs, the computational cost of capturing the relationship between words in a sentence increases with sentence length for both types of networks. To overcome this limitation, transformer-based models simultaneously generate an "attention score" for each word in a sentence.
Compared to convolutional and recurrent neural networks, transformers offer much greater parallelization, allowing effective training of large models on massive amounts of data on GPUs. Since 2018, several large-scale Transformer-based pre-trained LMs have entered the market. Transformer-based models use more complex network topologies. To better capture the context of text representations, these models are pre-trained on larger amounts of text.
Conclusion
In this artgicle, we have talk about:
- The evolution of deep learning-based language models in natural language understanding.
- The Feed-forward networks based models
- RNN-based models
- Capsule neural network-based models
- Models with attention mechanismModels with attention mechanism
- Models based on graph neural network
- Models with hybrid techniques
- Models based on transformers











