

Bring this project to life
Emojis, unlike before, have now become an integral part of just about any conversation for expressing emotions and feelings in text form. Over the years, the use and expression of emojis has evolved and gained substantial popularity. Emojis can also be used as an independent non-verbal language to convey most emotions, and supplement written text by enhancing its emotional quotient. Recently, in-built keyboards that come in mobile phones have been updated with the feature of suggesting emoji for a given word/phrase as you type. Such a feature gives the user the medium to express his/her emotions without having to go through the pain to search for relevant emojis from the emoji lake.
The latest research shows that the appeal of emojis goes well beyond young users alone - in fact, more than 80% of adults in the UK now use them in their text messages, while a whopping 40% admit to having created a message composed entirely of emojis. - Source
One of the baseline approaches to quickly prototype this is to have a large database of words and their respective emoji mappings, and querying the database as and when required for a word with its possible spelling variations.
In this blog, we are going to build an emoji suggestion system for short sentences rather than just a single word. We also build an interface to showcase the entire system.
Dataset
We will be using the dataset from here. Our data contains short sentences with relevant emojis as their class labels. The labels are marked as numeric between 0–4, mapping of which to actual emoji can be seen in the table shown below —

Given the fact that we have very limited training data (200 sentences), it becomes important for us to leverage pre-trained word embeddings for this task. These are some generic representations of words trained based on the context in which the words occurs in a very large corpora. For this blog, we will use a stack of multiple word embeddings for representing a word. We will see more about the approach and its detail in the Methodology section. To formalize this, it is a multi-class classification problem, wherein for a given utterance we need to predict the most suitable emoji.
Methodology
As mentioned above, the core idea of this task would be to build a multi-class classifier. We start by representing each word in the sentence with some pre-trained semantic word vectors with the hope that they are trained enough to capture different possible semantics of that word. To account for strengths that each pre-training method holds, we represent a word as a stack of multiple word embeddings. These are later fed to a shallow LSTM network that takes care of relating words in sequence and learning dependencies amongst them. As output, we expect to get a fixed-length vector representation of every sentence in the data. This final sentence vector is later fed to a feed-forward neural network with a Softmax Activation function across 5 classes, and the final label is chosen to be the class with maximum probability.
The below diagram shows a pictorial view of the full architecture—
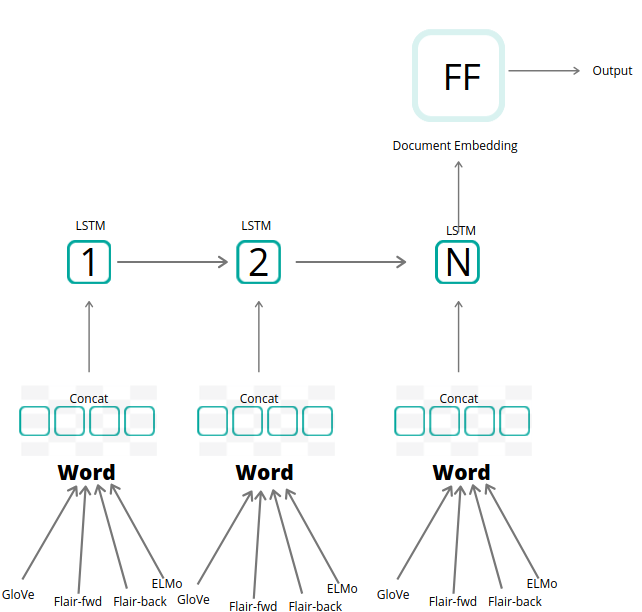
The novelty of this approach comes with the way we represent every word in the sentence. We make use of 4 different types of pre-trained word embeddings in their concatenated version for representing a single word in the sentence. The 4 types of embeddings that we used were — GloVe(Polysemy unaware Word Level), Flair-news-fwd(Contextualized character-level), Flair-news-back (Contextualized character-level), ELMo(Polysemy aware Word Level). The hypothesis for using 4 different types of embeddings was that all the embeddings were trained in different ways giving them the freedom to capture different semantics for the same word across their respective dimensions. This also helps in handling out-of-vocabulary tokens, especially when incorporating character-level embeddings.
Below snippet shows model architecture -
Model: "TextClassifier(
(document_embeddings): DocumentRNNEmbeddings(
(embeddings): StackedEmbeddings(
(list_embedding_0): WordEmbeddings('glove')
(list_embedding_1): FlairEmbeddings(
(lm): LanguageModel(
(drop): Dropout(p=0.05, inplace=False)
(encoder): Embedding(300, 100)
(rnn): LSTM(100, 2048)
(decoder): Linear(in_features=2048, out_features=300, bias=True)
)
)
(list_embedding_2): FlairEmbeddings(
(lm): LanguageModel(
(drop): Dropout(p=0.05, inplace=False)
(encoder): Embedding(300, 100)
(rnn): LSTM(100, 2048)
(decoder): Linear(in_features=2048, out_features=300, bias=True)
)
)
(list_embedding_3): ELMoEmbeddings(model=elmo-medium)
)
(word_reprojection_map): Linear(in_features=5732, out_features=256, bias=True)
(rnn): LSTM(256, 512)
(dropout): Dropout(p=0.5, inplace=False)
)
(decoder): Linear(in_features=512, out_features=5, bias=True)
(loss_function): CrossEntropyLoss()
)"Experiment
Bring this project to life
We will use Flair NLP Framework to train the model. Flair is a simple NLP library developed on top of PyTorch and open-sourced by Zalando Research.
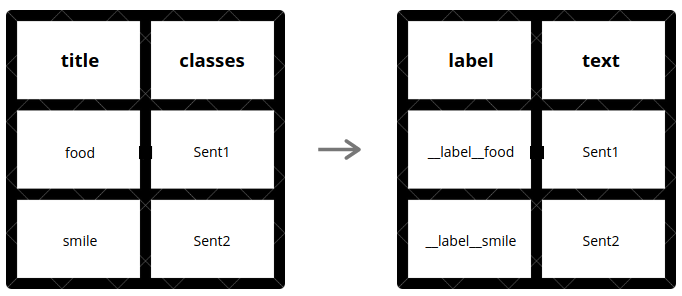
Below is the snippet that does the above shown data transformation —
def segment_data(data_file):
try:
import pandas as pd
except ImportError:
raise
data = pd.read_csv(data_file, encoding='latin-1').sample(frac=1).drop_duplicates()
data = data[['classes', 'title']].rename(columns={"classes":"label", "title":"text"})
data['label'] = '__label__' +data['label'].astype(str)
data['text'] = data['text'].apply(lambda k: k.lower().strip())
data.to_csv('./data/whole.csv', sep='\t', index = False, header = False)
data.iloc[0:int(len(data)*0.8)].to_csv('./data/train.csv', sep='\t', index = False, header = False)
data.iloc[int(len(data)*0.8):int(len(data)*0.9)].to_csv('./data/test.csv', sep='\t', index = False, header = False)
data.iloc[int(len(data)*0.9):].to_csv('./data/dev.csv', sep='\t', index = False, header = False)
return
Next, we load all the necessary embeddings, and return the list encapsulating them. Each word is embedded with the stacked version of all the four embedding schemes as its final representation.
def initialize_embeddings():
"""
Summary:
Stacks the list of pre-trained embedding vectors to be used as word representation (in concat.)
Return:
list: Returns list of pretrained embeddings vectors
"""
word_embeddings = [
WordEmbeddings('glove'),
FlairEmbeddings('news-forward'),
FlairEmbeddings('news-backward'),
ELMoEmbeddings('medium')
]
return word_embeddings
word_embeddings = initialize_embeddings()After finalizing our word representation, we go ahead and use DocumentRNNEmbeddings to learn the contextualized sentence representation followed by training the model with necessary hyper-parameters. You can read about other possible pooling techniques here.
document_embeddings = DocumentRNNEmbeddings(word_embeddings, hidden_size=512, reproject_words=True, reproject_words_dimension=256, rnn_type='LSTM', rnn_layers=1, bidirectional=False)
classifier = TextClassifier(document_embeddings, label_dictionary=corpus.make_label_dictionary(), multi_label=False)
trainer = ModelTrainer(classifier, corpus)
trainer.train('./model', max_epochs=20, patience=5, mini_batch_size=32, learning_rate=0.1)You can access all the original code at this github.
Visit the Gradient-AI fork and click 'Run on Gradient' for access to the notebook version of this code, or use the 'Bring this Project' to life link in this article.
Interface
Finally, a Flask based web-application was developed showcasing the use-case.
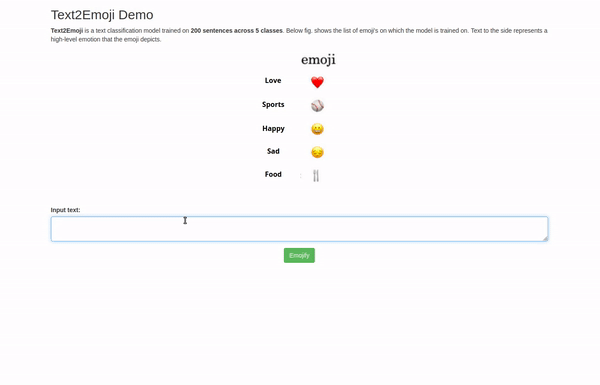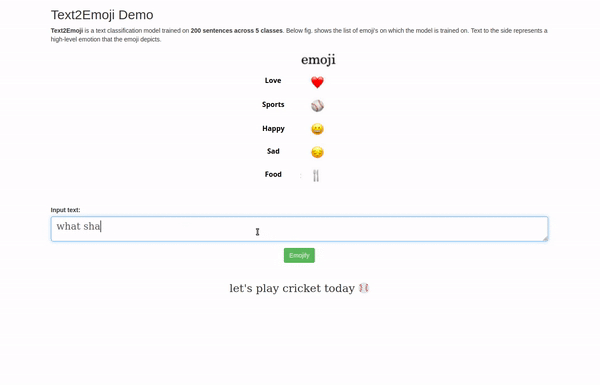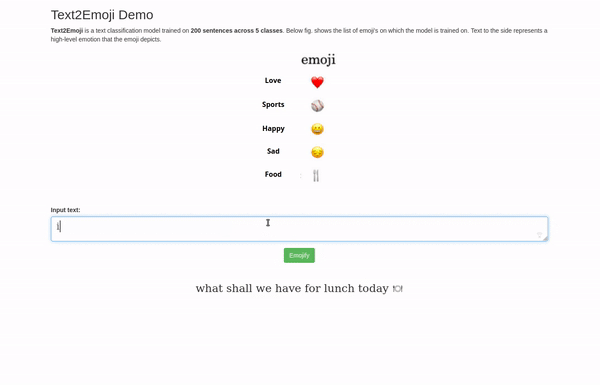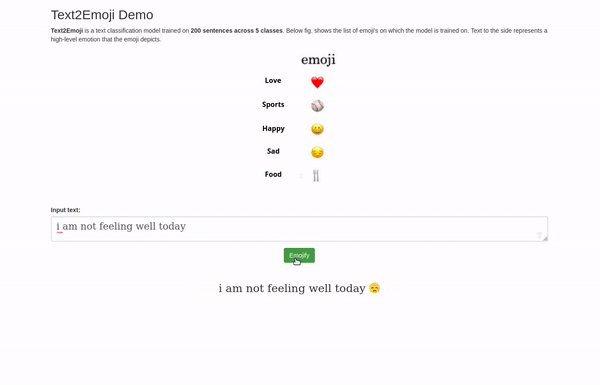
You can access all the code for this demo at this GitHub link.
Possible Improvements
- Fine-tuning pre-trained Transformers model on this specific task or using more advanced deep embeddings from BERT.
- Analyzing the effect of incorporating Emojipedia (Emojipedia is an emoji reference website which documents the meaning and common usage of emoji characters in the Unicode Standard) and other Statistical Features along with the existing embedding vector.
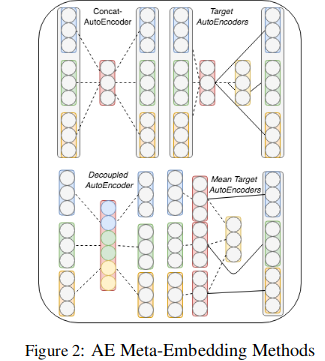
- Training an Auto-encoder, and picking the bottle-neck layer as the Meta-Embedding for word representation. Please refer below the figure for reference —
That't it for this blog, hope you enjoyed reading it. Thanks!











