
Bring this project to life
Speech to text has quickly become one of the more prominent use cases for deep learning technology in our daily lives. From automated call systems to voice assistants to simple search engine integration, this functionality can go a long way for improving a users experience. This added versatility has become built in to many of these technologies, and synonymous with the experience of using them.
For years, this sort of technology was largely proprietary, and for good reason. There is a race to the top to create the best NLP models, and the arms race remains ongoing. Examples of this for speech to text include the popular Google Translate API and AWS Transcribe. Others are built in to popular applications, like Apple's Siri.
Rising up to meet these tools comes the rapidly popularizing Whisper from Open AI, which offers comparable efficacy to production grade models for free to users, with a multitude of pre-trained models to take advantage of. In this tutorial, we will look at Whisper's capabilities and architecture in detail. We then jump into a coding demo showing how to run the powerful speech to text model in a Gradient Notebook, and finally close our tutorial with a guide to setting up the same set up in a simple Flask application with Gradient Deployments.
Whisper
Whisper was trained for 680,000 hours on multi language and multi task supervised data collected from the web. They found that their dataset selection and training gave the model a robust strength for handling peculiarities like accents and background noise that could otherwise interfere with inference. In this section, we will explore the strengths this training gives our model in detail, as well as walk through how the model was able to train on this data.
You can read more in depth information about Whisper in the original paper.
Capabilities
The capabilities of Whisper can essentially be boiled down to 3 main key functionalities: transcription of speech to text, language identification, and translation of one language to another.
Transcription
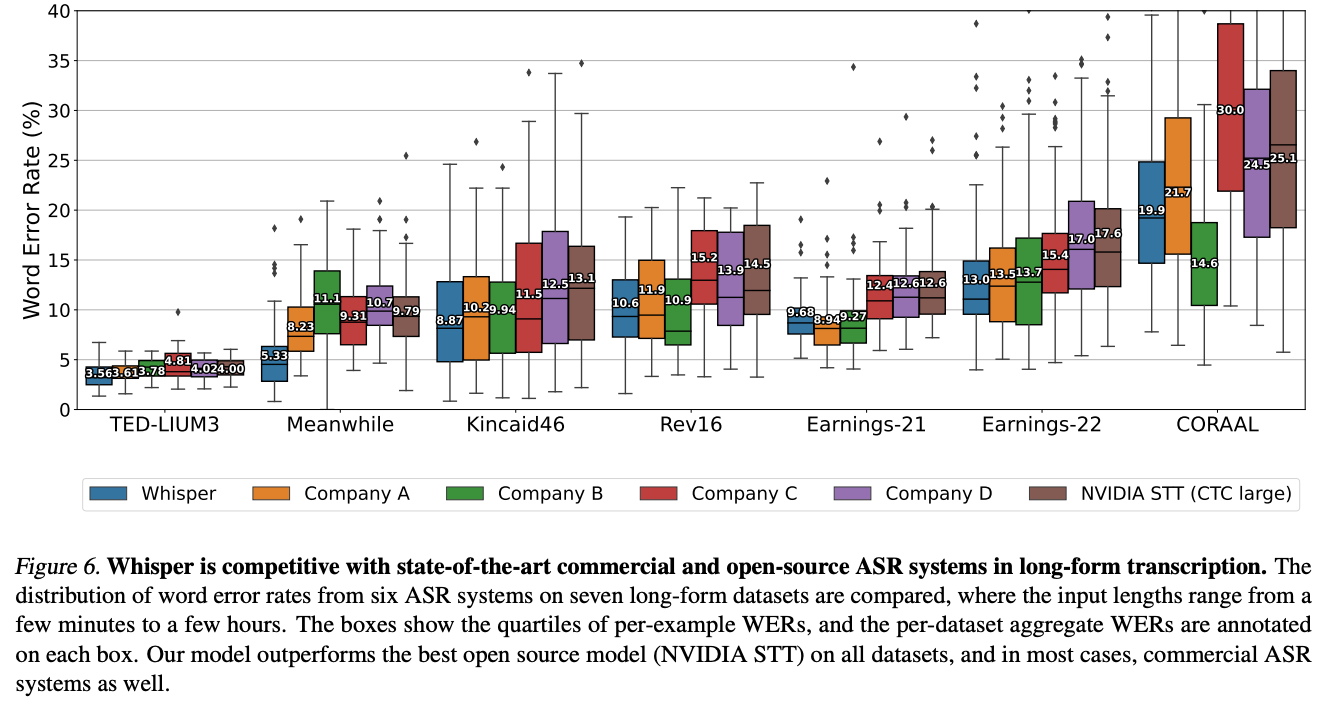
Transcription is the ability to understand and mark down the perceived words being spoken in an audio snippet. As you can see from the plot above, Whisper performs comparably to 5 unnamed company's proprietary Audio Speech Recognition (ASR) systems. This performance came from observing that they could efficiently performed buffered transcription of long sequences of audio by consecutively transcribing 30 second long segments of the whole, and order this by shifting the window according to the timestamps predicted by the model. They found that they were able to accurately and reliably transcribe long sequences of audio with beam search and scheduling of the temperature based on the repetitiveness and log probability of the model predictions.
In practice, the model is capable of accurately and efficiently transcribing text of any length from audio to string format.
Language Identification
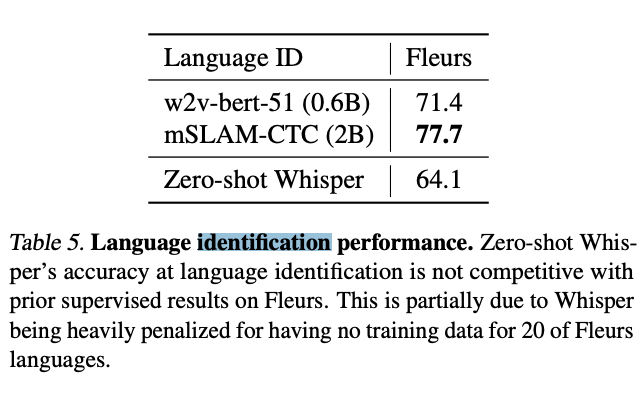
The research team created an audio language detector by fine-tuning a prototype model on the VoxLingua107 dataset to integrate with their model. This was done to ensure that the language being spoken aloud in the audio sample matches the language of the outputted transcript. The version of the CLD2 model used was not up to par with competing identification models, but the authors attribute this to the lack of training data used for the relevant test taking place. 20 of the languages used in the test had no training data, so this is a logical conclusion.
Translation
The ability to translate and transcribe is likely one of Whisper's most interesting capabilities. The applications for such a technology in the modern world are endless, especially as we globalize further. That being said, Whisper is not equally capable for translating all examples of languages.
The figure below shows a WER (Word Error Rate) breakdown by languages of Fleurs dataset, using the large model, which was the best performant of their pretrained sample models. This measures how many of the total words predicted were incorrect of the total translations, and gives us a good idea of how the model performs across the various tasks. More WER and BLEU scores corresponding to the other models and datasets can be found in Appendix D in the paper.
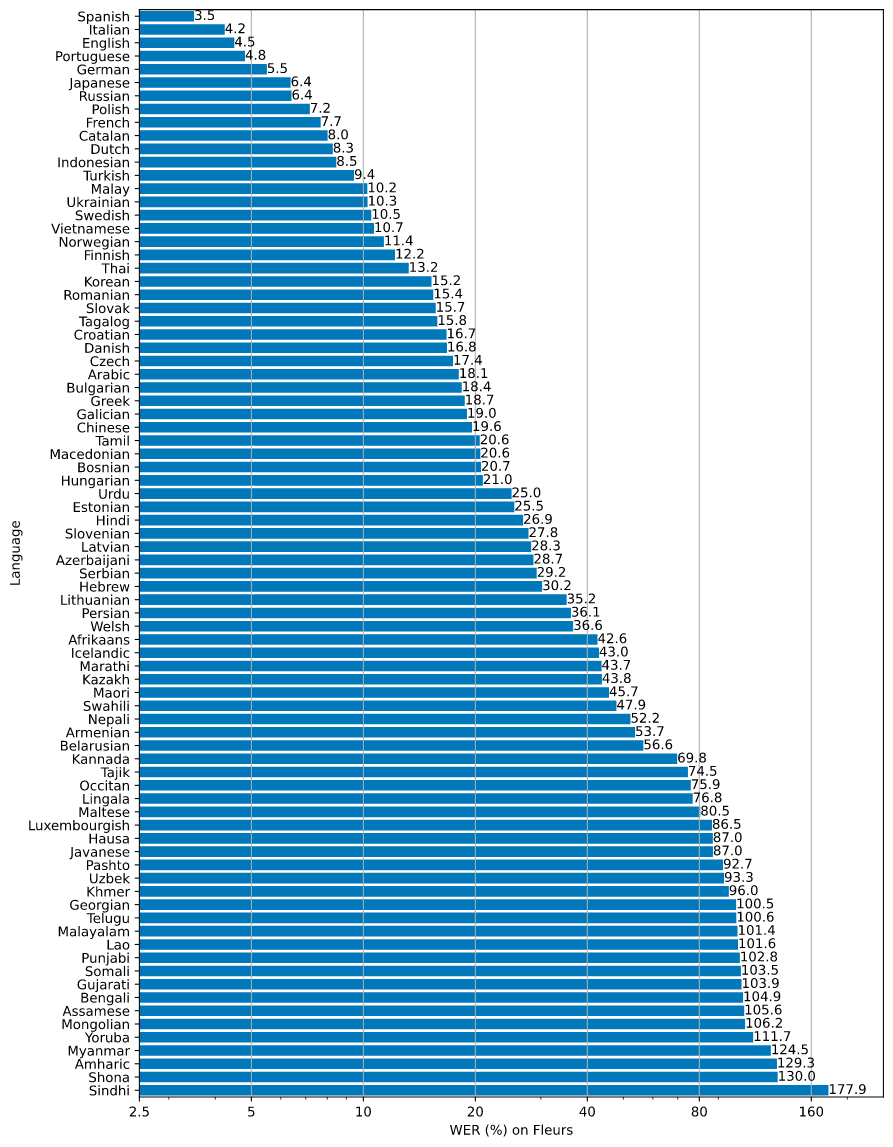
As we can see, there is a huge variation of capability across the Fleurs languages dataset. The model performs best on languages that most closely resemble English, including the romance and germanic languages. This stands to reason, as there are many shared words and traits across these language families with English. The highest WER came from Sindhi, Shona, and Amharic, which represent the more distinguished Indo-Aryan, Bantu, and Semitic language families. This also makes logical sense, given the stark differences between these languages and English in spoken observation.
This goes to show that while Whisper is a powerful tool, it does not represent a universal translator. Like any deep learning framework, it needs exposure to examples from the subject data source during training to truly function as desired.
Architecture
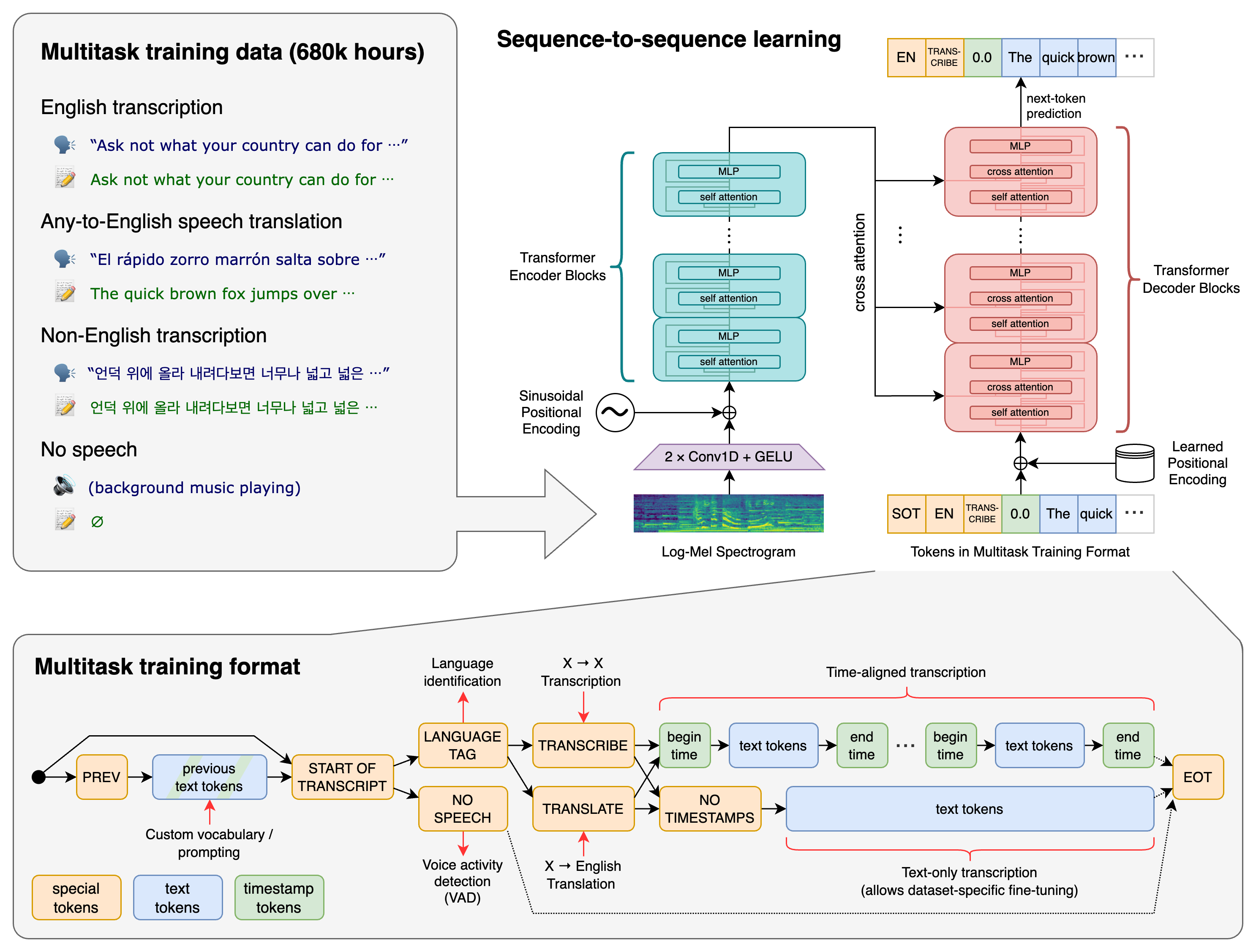
The Whisper model, at its core, is based off the classic encoder-decoder Transformer model. It takes in audio-text pairs of data to learn to predict the text output of inputted audio samples. Before training, the audio data was all re-sampled to 16,000 Hz. During training, first the model generates an 80-channel log-magnitude Mel spectrogram representations of the audio data, using 25-millisecond windows with a stride of 10 milliseconds.
The data is then globally scaled to be between -1 and 1, with a mean of approximately zero across the pre-training dataset. The encoder processes this input representation with a small stem consisting of two convolution layers with a filter width of 3 and the GELU activation function, where the second convolution layer has a stride of two. Sinusoidal position embeddings are then added to the output of the stem. Finally, the transformer pre-activation residual blocks are then applied to the transformed data, and a final layer normalization is applied to the encoder output. The decoder then reverses the process to use learned position embeddings and tied input-output token representations to recreate the encoded words as text.
This pipeline is designed this way so that tasks in addition to transcription can be appended to this process, but some form of task specification is necessary to control it. They devised a simple format to specify all tasks and conditioning information as a sequence of input tokens to the decoder. These specialized tokens, including one for the detected language and task at hand, guide the purpose of the decoder in generating the output. This allows the model, rather ingeniously, to be capable of handling a wide variety of NLP tasks with little to no change to its architecture.
Demos
When working with Whisper, we are fortunate to have access to 9 pretrained models to use for our own inference, with no additional training required.
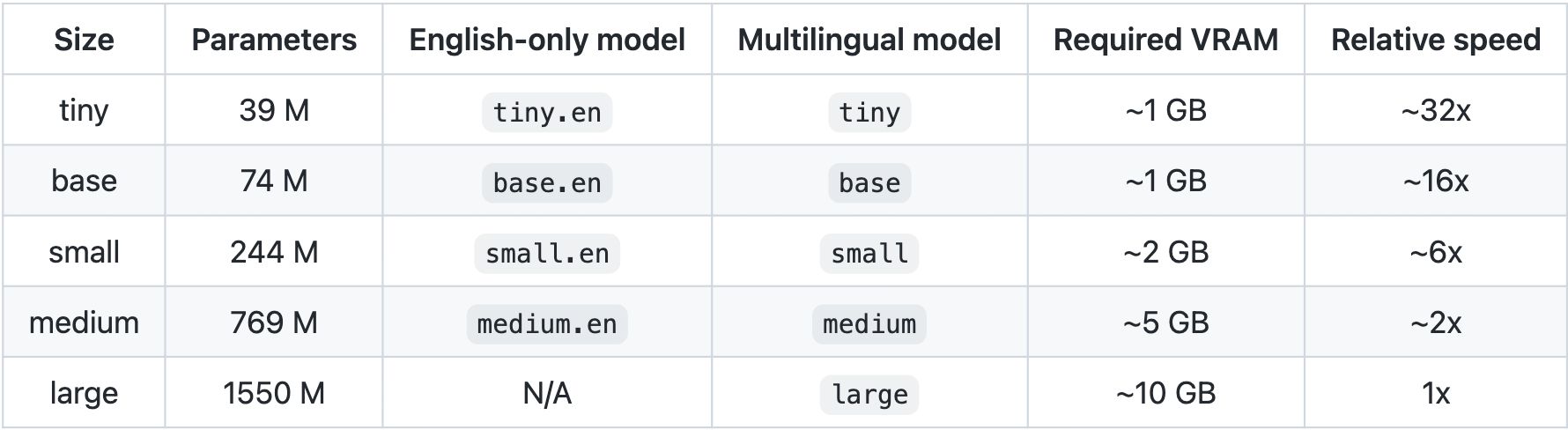
These models vary widely in performance, so be sure to choose the model based on your use case and GPU power. You can expect the higher the count of parameters, the more general and capable your model inference will be. Additionally, you can expect better performance on all English language tasks from the models with the .en suffix.
Now let's look at how we can use these different models in our two Gradient tools: Notebooks and Deployments.
Bring this project to life
Notebook
Running Whisper in a Gradient Notebook is easy thanks to the succinct and well written pipeline provided by Open AI. Following this guide, you will be able to translate and transcribe audio samples of speech in multiple languages in very little time.
First, let's set up the workspace with some installs.
## Install whisper package
pip install git+https://github.com/openai/whisper.git
## Should already be up to date
apt update && apt install ffmpegOnce that is done, running inference code is simple. Let's walk through the provided sample inference code from the project Github, and see how we can best use Whisper with Python.
import whisper
model = whisper.load_model("base")First, we import the whisper package and load in our model. Using the tags designated in Table 1, you can change the type of model we use when calling whisper.load_model(). Our recommendation is to use the tiny model for light weight applications, the large model if accuracy is most important, and the base model if you are unsure.
# load audio and pad/trim it to fit 30 seconds
audio = whisper.load_audio("audio.mp3")
audio = whisper.pad_or_trim(audio)Next, we load in the audio data using whisper.load_audio(). We then use the pad_or_trim() method to ensure the sample is in the right form for inference.
# make log-Mel spectrogram and move to the same device as the model
mel = whisper.log_mel_spectrogram(audio).to(model.device)We then use our audio data to generate a log-Mel spectrogram of the audio. This will serve as our input to the encoder block. Once it is generated, we move it to the GPU from the CPU, so it is on the same device as the model.
# detect the spoken language
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")We then use the inbuilt detect_language() method to detect the inputted language of the speech. We can use this information to infer how well our model will do before running transcription/translation, along with the WER rate plot. This can be useful to run before attempting to transcribe a particularly lengthy segment of audio.
# decode the audio
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
# print the recognized text
print(result.text)Finally, we declare the task and parameters for decoding the speech using whisper.DecodingOptions() . This is where we could declare that we would like to use the model for translation or transcription, and additionally input any other number of sampling options. We then input the model, the mel, and the options to the whisper.decode() method, which transcribes (or translates and then transcribes) the speech into strings of text characters. These are then saved in 3 formats as .txt, .VTT, and .SRT files.
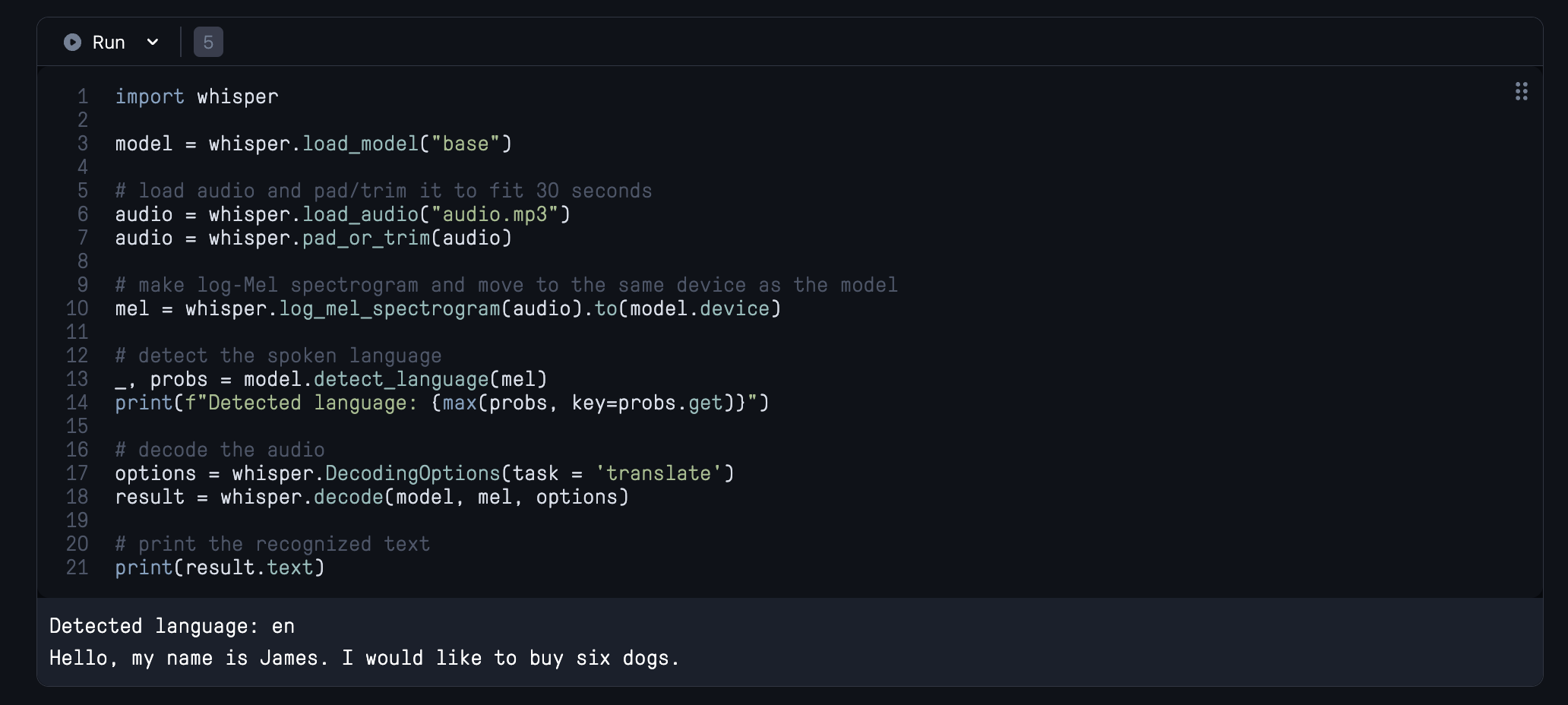
All together, this code can run in just a single cell like pictured above.
Deploy
We have created a sample Deployment of the small pre-trained model for you to use and base your own applications off of. This scaffold itself was adapted from a similar application made for the face restoration model GFPGAN. In this section, we will walkthrough the two methods for launching this application with Gradient Deployments: the Gradient CLI and the Deployments GUI. Our recommendation is to use the latter, and you will see why shortly.
For more information on creating your own Gradient Deployment from scratch, be sure to read the tutorial for how we made this scaffold for launching deep learning Flask applications with Gradient Deployments.
Gradient Client
When using the Gradient CLI, we need to first take a few steps to set up our local environment. Specifically, we need to install the package, if not already, and get our personal API key attached to the installation.
To do this, log into your Gradient account on your browser, and navigate your mouse to the top right drop down menu, and select 'Team Settings'. Then, open the 'API Keys' tab, and create an API key. Save this API key for later, and navigate back into the Gradient console. There, select or create a project space for the deployment in a Team of your choice. Save the project ID in the same place you saved the API key.
We will then use this to log in to our account by entering the following into the terminal on our local machine:
pip install gradient
gradient apikey <your api key here>Once that is completed, we need to get the YAML spec onto the computer, and run the command to start the deployment. We can do this by first cloning the gradient-ai/whisper fork, and navigating into that directory.
git clone https://github.com/gradient-ai/whisper
cd whisperFinally, we can create and run the deployment at the direction of the YAML file.
gradient deployments create --projectId <your project id of choice> --name <name of deployment> --spec spec.yaml
This will then create an API endpoint you can access through your web browser.
Gradient Deployments GUI
The next method to launching the demo deployment is the recommended method: using the Deployments GUI.
To get started, log in to your account and open a project of your choice. Then, navigate to the Deployments tab with your mouse. Once inside, hit 'Create' to advance to the Deployment creation page.
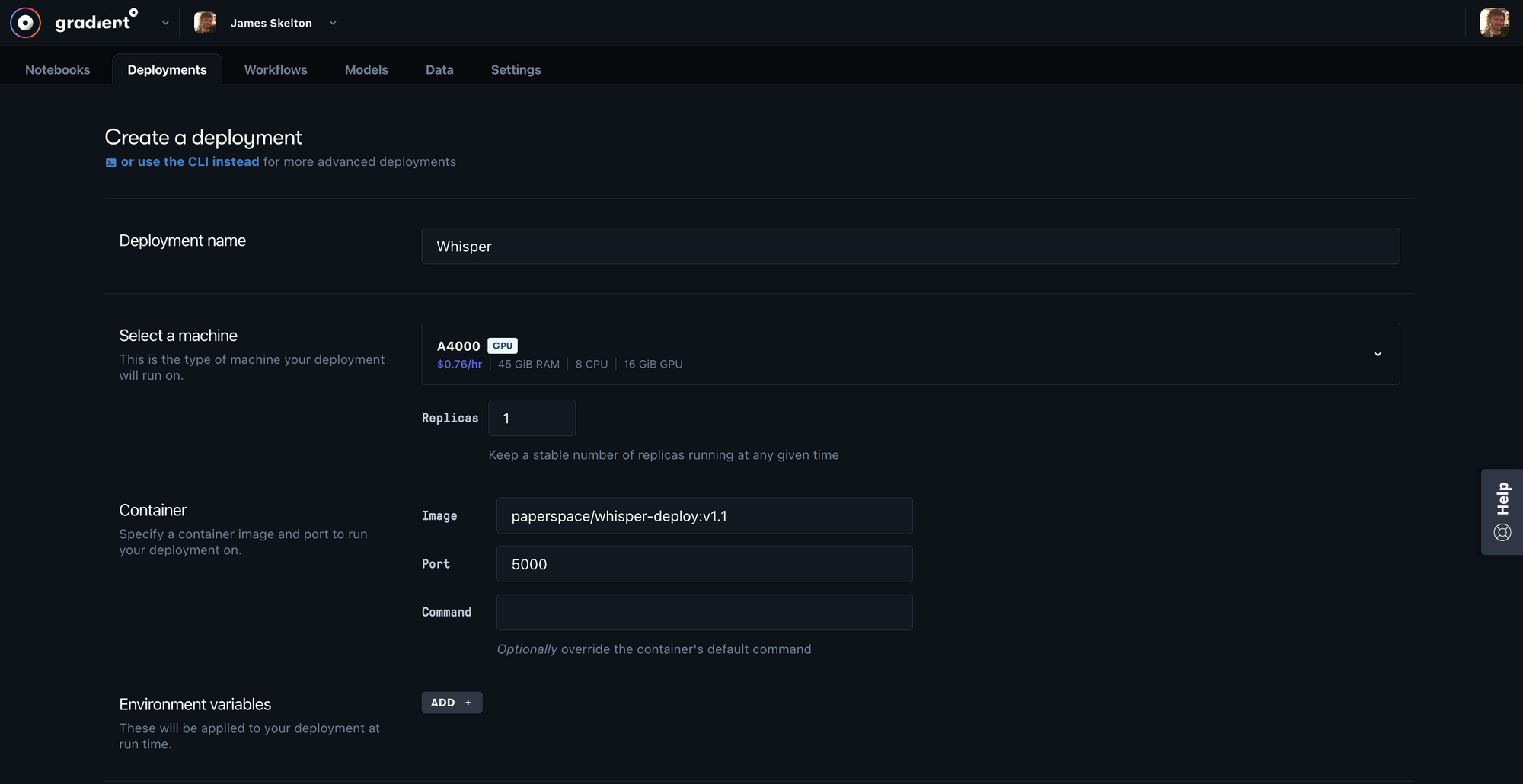
Once inside the creation page, we can use the same data we would have inputted from the spec.yaml file if we were using the Gradient CLI. First, we specify the name of our Deployment, in this case 'Whisper.'
Next, scroll down to 'Select a machine' and choose a GPU machine of your choice. This should run easily on any of our GPUs, since they each offer 8+ GB of VRAM, but there are options to scale up as much as needed. This may be something to consider if you intend to change the application's current model to the Large version in particular.
Finally, navigate to the 'Container' section and fill in the 'Image' box with paperspace/whisper-deploy:v1.1, and the 'Port' box with 5000. This image comes pre-packaged with the various packages you need to run the model, as well as the pre-trained model weights for the small model itself.
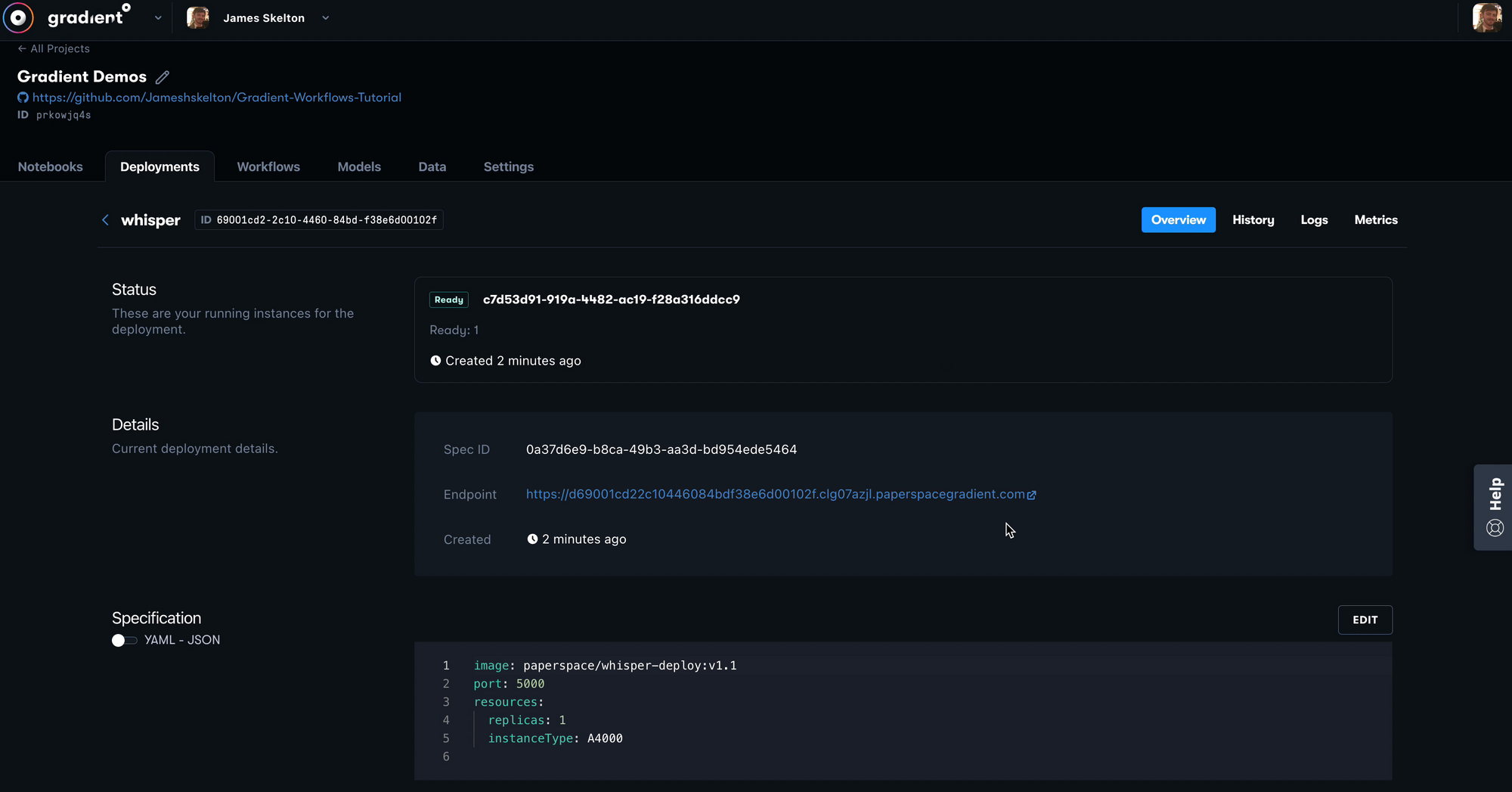
Once that has all been filled in, you can launch your Deployment with the button at the bottom of the page. After about a minute, the Deployment should finish building, and you can then select the API endpoint to open your Deployment.
Using the deployment application
Once your model Deployment is running, you can access it by clicking the link following the 'Endpoint' field in the 'Details' section of the GUI. Alternatively, this will also be printed automatically in the terminal when using the CLI when the Deployment finishes building.
Once you open the link, you will be served with a simplistic interface for uploading an audio file in FLAC, WAV, or MP3 format. When you select the file, and hit 'Upload' in the application, the model will begin transcribing your text. When the model prediction is complete, the application will output the text as HTML in the output page.
Altering the Deployment
To alter this deployment would be complicated at this stage, but future iterations of this scaffold aim to make this more flexible. Nonetheless, we invite readers to experiment with this application as much as they would like. This scaffold is designed to be augmented and improved.
To get started currently, one would likely need to fork the Gradient-AI fork of the Whisper Github repo. Then, change into that directory and take the following steps:
- Edit the Dockerfile lines 17 and 20 to your new fork's URL and the model type you would like to use (URLs to models can be found in
whisper/__init__.py) - Edit line 313 of
whisper/transcribe.pyto contain the arguments for your new model run. This would allow you to add in the--task translationtag if you desire, and change the model fromsmallto your new model type. - Make additional changes to the application HTML as desired in 'app.py'
- Build a new Docker image with this new directory, and push to Dockerhub
- Launch your Deployment using the new container
Closing thoughts
In this tutorial, we walked through the model capabilities and architecture of Open AI's Whisper, before showcasing two ways users can make full use of the model in just minutes with our demos with Gradient Notebooks and Deployments.
Whisper is an incredibly impressive model, and makes for a fantastic test application. The underlying technology is extremely innovative, which allows for it to make accurate transcriptions and translations with an extremely lightweight yet robust model. Be sure to explore the original paper and Github project page for more information about the research involved with creating this awesome model.











