
In this article, we will explore the second version of StyleGAN's models from the paper Analyzing and Improving the Image Quality of StyleGAN, which is obviously an improvement over StyleGAN from the prior paper A Style-Based Generator Architecture for Generative Adversarial Networks. StyleGAN is based on ProGAN from the paper Progressive Growing of GANs for Improved Quality, Stability, and Variation. All three papers are from the same authors from NVIDIA AI. We will go through the StyleGAN2 project, see its goals, the loss function, and results, break down its components, and understand each one. If you want to see the implementation of it from scratch, check out this blog, where I replicate the original paper as close as possible, and make an implementation clean, simple, and readable using PyTorch.
StyleGAN2 Overview
In this section, we will go over StyleGAN2 motivation and get an introduction to its improvement over StyleGAN.
StyleGAN2 motivation
StyleGAN2 is largely motivated by resolving the artifacts introduced in StyleGAN1 that can be used to identify images generated from the StyleGAN architecture. Check out this website whichfaceisreal which has a long list of these different artifacts that you can use to tell if an image was created by StyleGAN or it was a real image.
Introduction of StyleGAN2 improvement over StyleGAN
StyleGAN is a very robust GAN architectures: it generates really highly realistic images with high resolution, the main components it is the use of adaptive instance normalization (AdaIN), a mapping network from the latent vector Z into W, and the progressive growing of going from low-resolution images to high-resolution images. StyleGAN2 restricts the use of adaptive instance normalization, gets away from progressive growing to get rid of the artifacts introduced in StyleGAN1, and introduces a perceptual path length normalization term in the loss function to improve the latent space interpolation ability which describes the changes in the generated images when changing the latent vector Z and introduces a deep defeat detection algorithm to project a generated images back into latent space.
StyleGAN artifacts
The authors of StyleGAN2 identify two causes for the artifacts introduced in StyleGAN1 and describe changes in architecture and training methods that eliminate them.
The first cause
In the figure below you can see a gif extracted from the video released with the paper that shows examples of the droplet artifacts; the authors identify the cause of these artifacts to the way that the adaptive instance normalization layer is structured. It is interesting when they see that the artifacts start from 64 by 64 resolution scale and then persist all the way up to 1024 by 1024 scale.

The authors of StyleGAN2 restrict the use of adaptive instance normalization to get rid of the artifacts introduced above. And they actually achieve their goals. We can see in the figure above the results after the changes in architecture and training methods that eliminate the artifacts.

The second cause
The authors noticed that, as they scale up the images that walk along the latent space, some kind of features such as mounts and eyes (if we generate faces) are sort of fixed in place. They attribute this to the structure of the progressive growing, and having these intermediate scales and needs intermediate low-resolution maps that have to be used to produce images that fool a discriminator. In the figure below, we can see some examples of that.

The authors of StyleGAN2 get away from progressive growing to get rid of the artifacts introduced above. And again, they achieve their goals.

AdaIN revisited
The authors of StyleGAN2 remove the adaptive instance normalization operator and replace it with the weight modulation and demodulation step. The idea is that scaling the parameters by using Si from the data normalization from the intermediate noise vector (w in the figure below refers to weights not intermediate latent space, we are sticking to the same notation as the paper.), where i is the input channel, j is the output channel, and k is the kernel index.
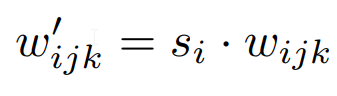
And then we demodulate it to assume that the features have unit variance.
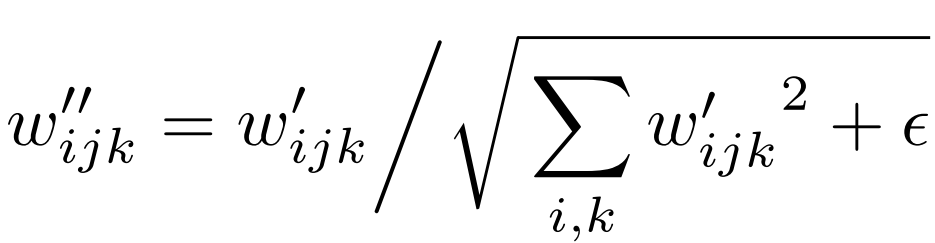
Perceptual path length regularization
The next technical change the authors make to StaleGAN2 is to add Perceptual path length regularization to the loss function of the generator to not have too dramatic changes in the generated image when we change in the latent space Z. If we slightly change the latent vector Z, then we want it to be a smooth change in the semantics of the generated image - rather than having a completely different image generated with respect to a small change in the latent space Z.
The authors argue for the use of the perceptual path length image quality metric compared to the FID score or precision and recall. In the figure below, we can see some examples of the bottom 10% on the left and the top 90% on the right of the cases where low perceptual path length scores are highly correlated with our human judgment of the quality of the images.

In the appendix of the paper, the authors further provide grids of images that have similar FID scores but different perceptual path length scores, and you can see the grids in the figure below that the groups of images with the lower perceptual path length scores generally are better images.

To implement perceptual path length regularization the authors calculate the Jacobian matrix Jw which is sort of seeing the partial derivatives of the output with respect to the small changes in the latent vector that produces the images.
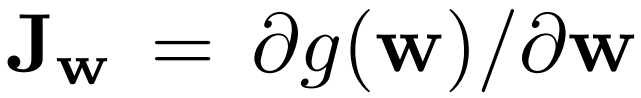
Then they use the Jacobian matrix Jw, multiply it by a random image Y, and the image Y is randomly sampled in each iteration to avoid having some kind of a spatial location dependency introduced by Y. They then take the L2 norm of this kind of matrix, and they subtract it by an exponential moving average, and, finally, they square it.

They do this in order to regulate the perceptual path length and make sure that the changes in latent vector Z do not lead to dramatic changes in the generated images.
Lazy regulation is a very computationally heavy process, so the authors add it in the loss function every 16 steps.
Progressive growing revisited
The last change in StyleGAN2 described in the paper is to eliminate the progressive growing. In progressive growing, when the network finished generating images with resolution of some arbitrary size like 16 by 16, they add a new layer to generate a double size images resolution. They up sample the previously generated image up to 32 by 32, and then they use the formula below [(1−α)×UpsampledLayer+(α)×ConvLayer] to get the upscaled image.
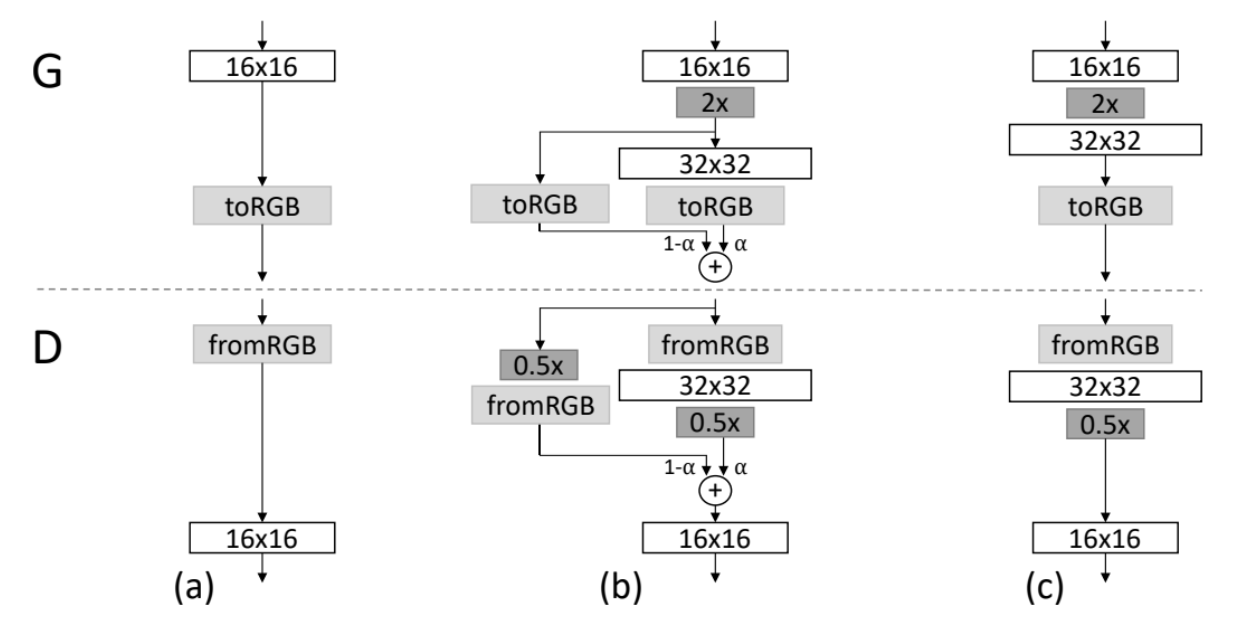
The problem with progressive growing is there are a lot of hyperparameters searching with respect to α that goes with respect to each scale (4x4, 8x8, 16x16, and so on). Additionally, this just complicates training a lot, and it's not a fun thing to implement.
The authors of StyleGAN2 were inspired by MSG-GAN, from the paper MSG-GAN: Multi-Scale Gradients for Generative Adversarial Networks, to come up with two alternative architectures to get away from progressive growing.
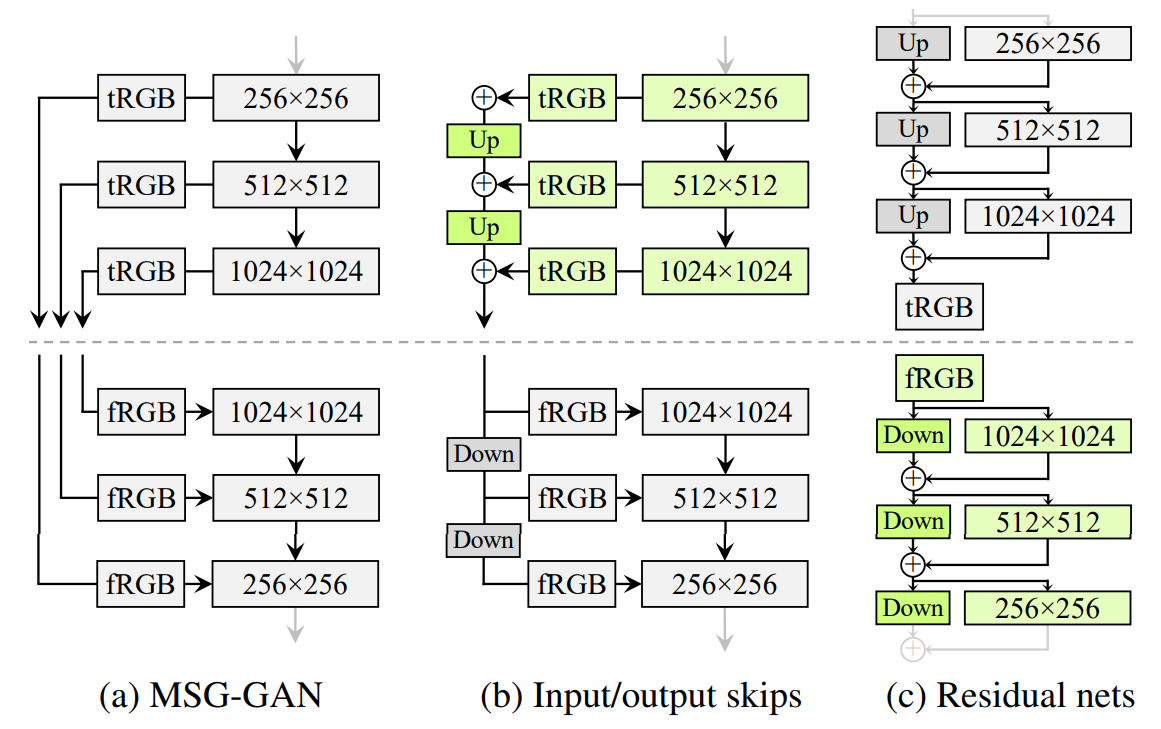
- In MSG-GAN they use intermediate feature maps in the generator, and then provided that as additional features to the discriminator
- In input/output skips they simplify the MSG-GAN architecture by upsampling and summing the contributions of RGB outputs corresponding to different resolutions. In the discriminator, they similarly provide the downsampled image to each resolution block of the discriminator. They use bilinear filtering in all up-and-down sampling operations
- In Residual nets, they further modify the architecture to use residual connections
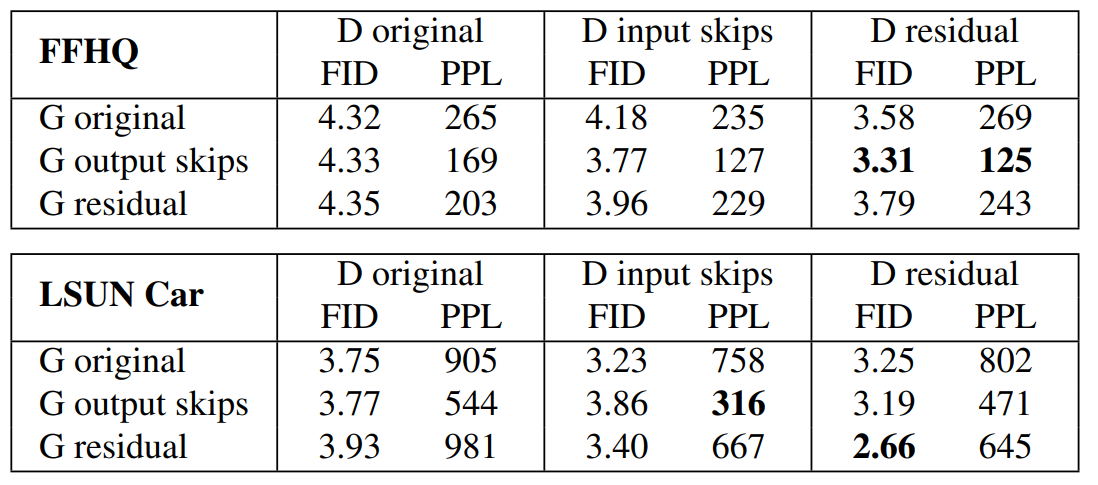
In the figure above you can see the comparison of generator and discriminator architectures without progressive growing that the authors made. It shows that there's really not much of a difference between the skip and residual architectures in the resulting image quality.
Projection of images into latent space
Another interesting thing the authors of StyleGAN2 present in the paper is a deep fake detection algorithm by projecting this image back into the latent space. The idea is we take as input an image that if it is fake we can find a latent vector that produces the same image, and if it is real we can not find any latent vector that produces the same image.
Results

The images generated by StyleGAN2 have no artifacts like the ones generated by STyleGAN1 and that makes them more realistic in a way that you couldn't differentiate between them and the real ones.
Conclusion
In this article, we go through the StyleGAN2 paper, which is an improvement over StyleGAN1, the key changes are restructuring the adaptive instance normalization using the weight demodulation technique, replacing the progressive growing with the skip connection architecture/residual architecture, and then using the perceptual path length normalization. All of that improve the quality of the generated images and get away from the artifacts introduced in StyleGAN1.
Hopefully, you will be able to follow all of the steps and get a good understanding of StyleGAN2, and you are ready to tackle the implementation, you can find it in this article where I make a clean, simple, and readable implementation of it to generate some fashion.










